
FAQ C++Consultez toutes les FAQ
Nombre d'auteurs : 34, nombre de questions : 368, dernière mise à jour : 14 novembre 2021 Ajouter une question
Cette FAQ a été réalisée à partir des questions fréquemment posées sur les forums de http://www.developpez.com et de l'expérience personnelle des auteurs.
Je tiens à souligner que cette FAQ ne garantit en aucun cas que les informations qu'elle propose sont correctes ; les auteurs font le maximum, mais l'erreur est humaine. Cette FAQ ne prétend pas non plus être complète. Si vous trouvez une erreur ou si vous souhaitez devenir rédacteur, lisez ceci.
Sur ce, nous vous souhaitons une bonne lecture.
- Pourquoi mettre en uvre un héritage ?
- Quand dois-je faire un héritage public ? protégé ? privé ?
- Qu'est-ce que le LSP ?
- Héritage EST-UN et programmation par contrat
- Pourquoi le destructeur d'une classe de base doit être public et virtuel ou protégé et non virtuel ?
- Qu'est-ce qu'une classe abstraite ?
- Qu'est-ce que l'héritage virtuel et quelle est son utilité ?
- Dans quel ordre sont construits les différents composants d'une classe ?
- Qu'est-ce que le polymorphisme ?
- Mes fonctions virtuelles doivent-elles être publiques, protégées, ou privées ? Le pattern NVI
- Comment varier le comportement au moment de l'exécution par le polymorphisme d'inclusion ?
- Puis-je appeler des fonctions virtuelles dans le constructeur (ou le destructeur) ?
- Que sont le typage statique et le typage dynamique ? Question subsidiaire : qu'est-ce que l'inférence de type ?



On trouve deux sémantiques liées à l'héritage :
- EST-IMPLEMENTE-EN-TERMES-DE (IS-IMPLEMENTED-IN-TERM-OF) :
Ce type d'héritage permet à la classe dérivée de tirer profit de l'implémentation de la classe de base. Si B dérive de A avec cette sémantique, alors toutes les fonctions de B peuvent appeler les fonctions de A. Le service apporté par la classe A est disponible dans la classe B. Une alternative à l'héritage 'EST-IMPLEMENTE-EN-TERMES-DE' est la composition. B possède un membre de type A et invoque ses fonctions au besoin. On peut préférer l'héritage lorsque la classe de base est vide (sans attribut) et que l'on souhaite bénéficier de l'optimisation des classes de base vides, ou lorsqu'il est nécessaire de redéfinir une fonction virtuelle de la classe de base. La composition permet de varier l'implémentation plus facilement. - EST-UN (IS-A) :
La sémantique de cet héritage découle de la définition du sous-type par Liskov et est donc intrinsèquement lié au principe LSP (Liskov substitution principle).
LSP (Liskov substitution principle).
Si le qualificatif 'EST-UN' est assez explicite, comprendre ses implications est parfois moins évident. « B dérive de A » avec cette sémantique a diverses conséquences. D'abord, on dit que B est un sous-type de A. Ensuite, tout objet de type A dans une expression valide peut être remplacé par un objet de type B : B doit garantir que l'expression reste valide ET qu'elle possède la même sémantique. Enfin, définir un sous-type n'est pas définir un type plus restrictif : B doit respecter tout ce que respecte A mais peut faire des choses en plus ou différemment.
À noter que les deux types d'héritage ne sont pas mutuellement exclusifs : B peut dériver de A à la fois car il EST-UN A et à la fois car il EST-IMPLEMENTE-EN-TERMES-DE A.
- public : uniquement si l'héritage porte une sémantique EST-UN ;
- privé : lorsque l'héritage porte une sémantique EST-IMPLEMENTE-EN-TERMES-DE et ne supporte pas la sémantique EST-UN ;
- protégé : si vous avez une bonne raison, la rédaction sera curieuse de la connaître.
L'héritage public est le plus problématique car il doit respecter le LSP et notamment ses implications en termes de contrat.
Le LSP (pour Liskov substitution principle) est un principe général de programmation s'énonçant de la façon suivante :
Comment cela se traduit-il sur le contrat de la classe ?
Sur les invariants des fonctions membres, les préconditions doivent ne pas être plus fortes et les postconditions doivent ne pas être plus faibles.
En effet, l'héritage est l'exposition d'une interface que les sous-classes vont affiner. Dès lors, toutes les fonctions membres d'une sous-classe doivent pouvoir travailler sur des objets acceptés selon l'interface de la classe parente et fournir un résultat au moins aussi sûr que celui de la classe parente.
On peut faire une analogie avec un sous-traitant. Un sous-traitant doit accepter tous les travaux que vous acceptez (et même plus s'il le veut) et doit rendre un travail au moins aussi sûr que le votre et même plus s'il le veut.
Sur les invariants de la classe, cela se taduit par le fait qu'une classe dérivée ne peut qu'ajouter des invariants à sa définition.
En effet, l'héritage public est une relation EST-UN. Quand Y dérive de X, Y EST-UN X. Dès lors, il doit vérifier tous les invariants de X plus ceux qui lui sont propres.
À ce titre examinons le code suivant :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | class rectangle { protected: double width; double height; public: virtual void set_width(double x){width=x;} virtual void set_height(double x){height=x;} double area() const {return width*height;} }; class square : public rectangle { /* L'invariant d'un carré est que à tout moment, width=height*/ void INVARIANT() {assert(width==height);} public: void set_width(double x) { INVARIANT(); rectangle::set_width(x); rectangle::set_height(x); INVARIANT(); } void set_height(double x) { INVARIANT(); rectangle::set_width(x); rectangle::set_height(x); INVARIANT(); } }; void foo(rectange& r) { r.set_height(4); r.set_width(5); assert(r.area() == 20); } |
Un carré est bien est un rectangle d'un point de vue mathématique mais pas sur le plan du comportement logiciel. Et c'est ce qui importe dans la programmation. Le comportement d'un carré N'EST PAS identique à celui d'un rectangle.On peut supposer que dans un rectangle, longueur et largeur vont varier indépendamment l'une de l'autre. Changer l'une ne doit pas changer l'autre, ce qui est intrinsèquement faux pour un carré.
Le carré n'est pas substituable au rectangle, il ne devrait donc pas hériter de la classe rectangle.
Il se passe le même problème entre une liste et une liste ordonnée. Les deux classes n'ont pas les mêmes invariants pour l'insertion.
Dans une liste, on peut insérer un objet où l'on veut, pas dans une liste triée. Des assertions valides pour la liste ne le sont plus pour une liste triée.
La réponse est donnée par Principe de Substitution de Liskov !

C'est un peu la question symétrique de la sémantique d'héritage, vue de la classe de base.
Avoir un destructeur public signifie qu'un objet de type statique A peut être détruit alors que son type dynamique est B, un sous-type de A :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 | class A { // Déclaration de A... }; class B : public A { // Déclaration de B... }; // ... // Quelque part dans le code : { std::auto_ptr<A> ptr_a(new B); } // Destruction à partir du type statique A avec un type dynamique B ! |
destruction soit correcte, le destructeur de A doit être virtuel. À partir du moment où une classe peut être dérivée et que vous ne savez pas à l'avance comment elle sera ensuite utilisée, vous devez traiter ce problème. Or il n'existe que deux solutions :- le destructeur est public et virtuel : vous autorisez sans risque qu'un objet dérivé soit détruit à partir d'une variable de type statique de l'objet de base.
- le destructeur est protégé et non virtuel : le destructeur d'un objet de type de base ne peut être appelé que par le destructeur du type dérivé. Plus de risque qu'un objet de type statique A tente de détruire un objet de type dynamique B.
Une classe abstraite est une classe qui possède au moins une fonction membre virtuelle pure (lire Qu'est-ce qu'une fonction virtuelle pure ?). Cette fonction devant être supplantée, ce type de classe ne peut pas être instancié, et est donc destiné à être dérivé pour être spécialisé. La ou les classes filles doivent supplanter l'ensemble des fonctions virtuelles pures de leurs parents. On dit alors que les classes filles concrétisent la classe abstraite.
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | class Bienvenue // classe abstraite { public: // le "= 0" à la fin indique que c'est // une fonction virtuelle pure virtual void Message() = 0; }; class BienvenueEnFrancais : public Bienvenue { public: void Message() { std::cout << "Bienvenue !\n"; } }; class BienvenueEnAnglais : public Bienvenue { public: void Message() { std::cout << "Welcome !\n"; } }; |
Le C++ est un langage qui autorise l'héritage multiple, c'est-à-dire qu'une classe peut avoir plus d'un parent. Exemple :
| Code c++ : | Sélectionner tout |
1 2 3 | class A{}; class B{}; class C: public A,public B{}; |
Imaginons le cas suivant :
| Code c++ : | Sélectionner tout |
1 2 3 4 | class V { protected:int i;/* ... */ }; class A : public V { /* ... */ }; class B : public V { /* ... */ }; class C : public A, public B { /* ... */ }; |
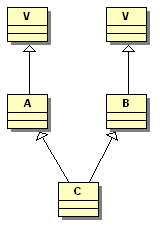
La classe A contient une variable membre i. Il en va de même pour la classe B. En ce qui concerne la classe C, elle possède deux variables membres i, l'une par l'héritage par A, l'autre selon l'héritage de B, c'est ce qui provoque une erreur si on tente d'accéder à i dans C, le compilateur ne sait pas s'il doit regarder A::i ou B::i.
Pour vous convaincre de la présence de deux variables i dans la classe C, compilez le code suivant :
| Code c++ : | Sélectionner tout |
void C::f(){std::cout << &(A::i) << "/" << &(B::i) << std::endl;}
Dans bon nombre de cas, il va être gênant (selon le point de vue de l'utilisation mémoire) d'avoir tous les membres dédoublés. La solution que propose le C++ est alors l'héritage virtuel. A hérite virtuellement de V et pour B il en va de même.
Exemple :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 | class V { protected:int i; /* ... */ }; class A : virtual public V { /* ... */ }; class B : virtual public V { /* ... */ }; class C : public A, public B { /* ... */ }; |
Pour preuve :
| Code c++ : | Sélectionner tout |
void C::f(){std::cout << &(A::i) << "/" << &(B::i) << std::endl;}
L'héritage est alors (on parle d' héritage en losange ou en diamant):
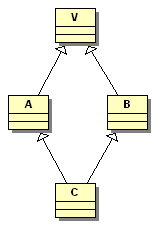
Notez par contre qu'on peut toujours introduire un nouvel objet V dans C de la façon suivante :
| Code c++ : | Sélectionner tout |
1 2 | class C : public A, public B, public V { /* ... */ }; |
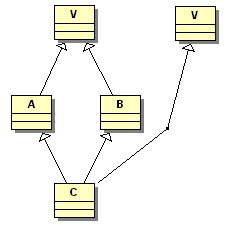
Les constructeurs sont appelés dans l'ordre suivant :
- le constructeur des classes de base héritées virtuellement en profondeur croissante et de gauche à droite ;
- le constructeur des classes de base héritées non virtuellement en profondeur croissante et de gauche à droite ;
- le constructeur des membres dans l'ordre de leur déclaration ;
- le constructeur de la classe.
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 | #include <iostream> #include <string> struct MembreA{ MembreA() { std::cout << "MembreA" << std::endl; } }; struct A { A() { std::cout << "A" << std::endl; } MembreA m; }; struct MembreB { MembreB() { std::cout << "MembreB" << std::endl; } }; struct B : A { B() { std::cout << "B" << std::endl; } MembreB m; }; struct MembreC { MembreC() { std::cout << "MembreC" << std::endl; } }; struct C : A { C() { std::cout << "C" << std::endl; } MembreC m; }; struct MembreD { MembreD() { std::cout << "MembreD" << std::endl; } }; struct D : B, C {D() { std::cout << "D" << std::endl; MembreD m; }; struct MembreE{MembreE() { std::cout << "MembreE" << std::endl; }; struct E : virtual A {E() { std::cout << "E" << std::endl; } MembreE m; }; struct MembreF{MembreF() { std::cout << "MembreF" << std::endl; }; struct F : virtual A { F() { std::cout << "F" << std::endl; } MembreF m; }; struct MembreG { MembreG() { std::cout << "MembreG" << std::endl; } }; struct G { G() { std::cout << "G" << std::endl; } MembreG m; }; struct MembreH { MembreH() { std::cout << "MembreH" << std::endl; } }; struct H : G, F { H() { std::cout << "H" << std::endl; } MembreH m; }; struct MembreI { MembreI() { std::cout << "MembreI" << std::endl; } }; struct I : E, G, F { I() { std::cout << "I" << std::endl; } MembreI m; }; template<class T> void Creation() { std::cout << "Creation d'un " << typeid(T).name() << " : " << std::endl; T t; } int main() { Creation<A>(); Creation<B>(); Creation<C>(); Creation<D>(); Creation<E>(); Creation<F>(); Creation<G>(); Creation<H>(); Creation<I>(); return 0; } |
| Code : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | Creation d'un struct A : MembreA A Creation d'un struct B : MembreA A MembreB B Creation d'un struct C : MembreA A MembreC C Creation d'un struct D : MembreA A MembreB B MembreA A MembreC C MembreD D Creation d'un struct E : MembreA A MembreE E Creation d'un struct F : MembreA A MembreF F Creation d'un struct G : MembreG G Creation d'un struct H : MembreA A MembreG G MembreF F MembreH H Creation d'un struct I : MembreA A MembreE E MembreG G MembreF F MembreI I |
Remarque 2 : L'ordre de construction est fixé par la norme et ne dépend pas des listes d'initialisation du code :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | struct Membre1 { Membre1() { std::cout << "Membre1" << std::endl; } }; struct Membre2 { Membre2() { std::cout << "Membre2" << std::endl; } }; struct A { A() { std::cout << "A" << std::endl; } }; struct B { B() { std::cout << "B" << std::endl; } }; struct C : A,B { C() :m2(), B(), m1(), A() { std::cout << "C" << std::endl; } Membre1 m1; Membre2 m2; }; int main() { C c; return 0; } |
| Code : | Sélectionner tout |
1 2 3 4 5 | A B Membre1 Membre2 C |
Remarque 3 : pour l'héritage virtuel, le constructeur appelé est celui spécifié par le type effectivement instancié et non par celui spécifié par le type demandant l'héritage. Si le type instancié ne spécifie pas de constructeur, alors c'est celui par défaut :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | struct A { A(std::string appelant_="defaut") { std::cout << "A construit par " << appelant_ << std::endl; } }; struct B : virtual A { B() :A("B") { } }; struct C : B { C() { } }; struct D : B { D() :A("D") { } }; template<class T> void Creation() { std::cout << "Creation d'un " << typeid(T).name() << " : " << std::endl; T t; } int main() { Creation<B>(); Creation<C>(); Creation<D>(); return 0; } |
| Code : | Sélectionner tout |
1 2 3 4 5 6 | Creation d'un struct B : A construit par B Creation d'un struct C : A construit par defaut Creation d'un struct D : A construit par D |
Le constructeur d'une classe doit monter sa liste d'initialisation suivant cet ordre :
- les constructeurs des classes héritées virtuellement dans tout l'arbre d'héritage en profondeur croissante et de gauche à droite ;
- les constructeurs des classes de base directement héritées dans l'ordre de gauche à droite ;
- les membres dans l'ordre de leur déclaration.
Ceci a comme conséquences :
- Ce sont d'éventuelles contraintes dans l'ordre de construction qui imposeront l'ordre d'héritage (et non des approches de type d'abord le public, puis le privé).
- Toute dépendance de construction entre les variables membres devra être explicitement commentée à défaut de pouvoir être évitée. Par cette documentation, les lecteurs du code sont avertis qu'il s'agit d'un comportement compris et maîtrisé par le développeur : la fiabilité est accrue et la maintenance est facilitée.
Le polymorphisme, c'est la capacité d'une expression à être valide quand les valeurs présentes ont des types différents. On trouve différents types de polymorphismes :
- ad-hoc : surcharge et coercition ;
- universel (ou non ad-hoc) : paramétrique et d'inclusion.
 On Understanding Types, Data Abstraction, and Polymorphism, de Luca Cardelli
On Understanding Types, Data Abstraction, and Polymorphism, de Luca Cardelli  Types et polymorphisme, de Jean-Marc Bourguet Connaissance des langages de programmation, de Ph. Narbel (Cours de MASTER 1 BORDEAUX 1 [2006-2007]) Qu'est-ce que la coercition ? Qu'est-ce que la surcharge ? Qu'est-ce que le polymorphisme paramétrique ? Qu'est-ce que le polymorphisme d'inclusion ?
Types et polymorphisme, de Jean-Marc Bourguet Connaissance des langages de programmation, de Ph. Narbel (Cours de MASTER 1 BORDEAUX 1 [2006-2007]) Qu'est-ce que la coercition ? Qu'est-ce que la surcharge ? Qu'est-ce que le polymorphisme paramétrique ? Qu'est-ce que le polymorphisme d'inclusion ?Vous avez sans doute déjà croisé des bibliothèques - ou en avez fait vous-même - proposant une interface à base de fonctions virtuelles :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 | class IInterface { public : virtual void Action(); // éventuellement pure (=0) }; |
Le pattern NVI - Non Virtual Interface - propose une autre approche pour la définition de telles interfaces dont le principe est : l'interface est proposée en fonction non virtuelle publique; la variabilité est encapsulée dans les fonctions virtuelles privées :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 | class IInterface { public : void Action(); private: virtual void DoAction(); // =0 }; |
Une fonction virtuelle privée ne peut être appelée par les classes dérivées. En revanche, une classe dérivée peut redéfinir la fonction pour adapter le comportement. La nécessité par la classe dérivée d'appeler l'implémentation de la classe parente est de part le pattern assez exceptionnelle. C'est pourquoi la fonction est privée et non protégée. Dans les cas exceptionnels où la classe de base peut proposer un comportement intéressant pour les classes dérivées, DoAction peut être protected.
La réponse à notre question première, « Mes fonctions virtuelles doivent-elles être publiques, protégées, ou privées ? », devient avec ce pattern :
- publique : jamais ;
- protégées : exceptionnellement ;
- privées : par défaut.
Ceci ne concerne pas le destructeur dont la problématique est envisagée dans une autre question (cf
pourquoi le destructeur d'une classe de base doit être public et virtuel ou protégé et non virtuel ?). « Quel est l'intérêt ? » est la première question qui se pose !
D'abord, il faut comprendre que la définition d'une interface s'adresse en fait à deux interlocuteurs bien distincts : la classe client qui utilise IInterface pour son service Action et la classe concrète qui dérive de IInterface et réalise Action en la redéfinissant. On voit donc par là qu'avec la première approche, Action se voit conférer deux rôles distincts. Séparer les deux fonctions permet ainsi d'indiquer clairement à chacun des deux interlocuteurs sa responsabilité. Il faut se souvenir qu'une bonne conception ne donne qu'une responsabilité bien définie à un élément. Octroyer de multiples responsabilités est souvent source de rigidité (problème de réutilisabilité), de confusion (pensez toujours à la maintenance) et de bugs (maîtrise de la complexité).
Dans une approche par contrat, IInterface passe un contrat avec le client sur la fonction Action : le client assure les préconditions s'il veut obtenir les postconditions. Et réciproquement, IInterface assure les préconditions de DoAction pour obtenir les postconditions :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 | void IInterface::Action() { // mise en place des préconditions de DoAction // éventuellement en mode debug, tests des préconditions DoAction(); // éventuellement en mode debug, tests des postconditions // traitements supplémentaires si besoin pour garantir les postconditions de Action() } |
En assignant à chacun sa responsabilité, cette séparation accroit la souplesse de l'interface face aux évolutions :
- Le service offert au client via Action peut évoluer de façon plus lâche par rapport à l'implémentation proposée par la classe concrète via DoAction.
- L'implémentation de DoAction dans la classe concrète peut évoluer en réduisant les impacts sur les clients de Action. Les détails d'implémentation peuvent évoluer par la spécialisation ou par la mise en ouvre d'autres mécanismes (pimpl idiom, patron de conception pont, etc.) sans que cela n'affecte le client.
Cette séparation crée aussi un endroit idéal pour l'instrumentation d'un code. La fonction non virtuelle Action peut accueillir les demandes de trace, peut surveiller les performances, etc. En mode debug, Action peut aussi tester les invariants, s'assurer des préconditions et garantir les postconditions.
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 | void IInterface::Action() { Log::Report("Entrée IInterface::Action"); Duree temps(Duree::maintenant); DoAction1(); temps.Stop(); Log::Report("Temps d'exécution : ", temps.LireDuree()); } |
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 | void IInterface::Action() { // Première partie de traitements DoAction1(); // Traitements suivants DoAction2(); // Traitements suivants.. DoAction3(); // fin des traitements } |
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 | class IInterface { public : void Action(); private: virtual void DoAction1(); // =0 virtual void DoAction2(); // =0 virtual void DoAction3(); // =0 }; |
En C++, on utilise souvent l'héritage pour ce faire. En effet, imaginez que nous soyons en présence d'une hiérarchie de composants graphiques, dont la classe de base serait Widget. On aurait ainsi Button et Textfield qui hériteraient de Widget par exemple. Enfin, chacun possèderait une méthode show() qui permet d'afficher le composant en question. Bien entendu, un Button et un Textfield étant de natures différentes, leur affichage le serait aussi.
C'est grâce au polymorphisme d'héritage, mis en ouvre en C++ grâce au mot clé virtual, que l'on peut réaliser cela dynamiquement : à l'exécution du programme, il sera choisi d'utiliser la méthode Button::show() ou la méthode Textfield::show() selon le type réel de l'objet sur lequel on appelle show(). Voici un exemple minimal illustrant cela.
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | class Widget { public: virtual ~Widget() { /* ... */ } void show() { // ... do_show(); // ... } // ... private : virtual void do_show()=0; // fonction virtuelle pure }; class Button : public Widget { private : virtual void do_show() { std::cout << "Button" << std::endl; } // ... }; class Textfield : public Widget { private : virtual void do_show() { std::cout << "Textfield" << std::endl; } // ... }; void show_widget(Widget& w) { w.show(); } // ... Button b; Textfield t; show_widget(b); // affiche "Button" show_widget(t); // affiche "Textfield" |
Oui, c'est possible, mais attention, ça ne fait pas toujours ce qu'on pense. La première approche consiste à comprendre que lors de l'appel du constructeur d'une classe de base, la classe dérivée n'a pas encore été construite. Donc, c'est la méthode spécialisée à ce niveau qui est appelée.
Voyons en détail :
La règle est que le type dynamique d'une variable en cours de construction est celui du constructeur qui est en train d'être exécuté. Pour bien comprendre ce qui se passe, il faut donc revenir sur la différence entre le type statique d'une variable, et son type dynamique.
Prenons par exemple trois classes, C qui dérive de B qui dérive de A. Par exemple, dans :
| Code c++ : | Sélectionner tout |
A* a = new B();
Par contre, son type dynamique est B*. Une fonction virtuelle est simplement une fonction dont on va chercher le code en utilisant le type dynamique de la variable, au lieu de son type statique, comme une fonction classique.
Maintenant, quand on crée un objet de type C, les choses se passent ainsi :
- On alloue assez de mémoire pour un objet de la taille de C.
- On initialise la sous partie correspondant à A de l'objet.
- On appelle le corps du constructeur de A. Pendant cet appel, l'objet crée a pour type dynamique A.
- On initialise la sous partie correspondant à B de l'objet.
- On appelle le corps du constructeur de B. Pendant cet appel, l'objet crée a pour type dynamique B.
- On initialise la sous partie correspondant à C de l'objet.
- On appelle le corps du constructeur de C. Pendant cet appel, l'objet crée a pour type dynamique C.
Donc, dans le corps du constructeur de la classe B, un appel d'une fonction virtuelle appellera la version de la fonction définie dans la classe B (ou à défaut celle définie dans A si la fonction n'a pas été définie dans B), et non pas celle définie dans la classe C.
D'ailleurs, si la fonction est virtuelle pure dans B, ça causera quelques problèmes, puisqu'on tentera alors d'appeler une fonction qui n'existe pas. En général, le programme va planter, si on a de la chance, il affichera une message du style « Pure function called ».
La problématique est exactement la même pour les destructeurs, mais dans l'ordre inverse.
Pourquoi cette règle ? Une fonction définie dans C a accès aux données membre de C. Or, on a vu que au moment où on exécute l'appel au corps du constructeur de B, ces dernières ne sont pas encore créées. On a donc préféré jouer la sécurité.
Le C++ est un langage typé, c'est-à-dire que toute variable possède au moment de sa définition un type connu par le compilateur : c'est le typage statique. Mais le type réel de l'objet peut être différent de son type statique. C'est ce qui se passe lors du polymorphisme dynamique.
| Code c++ : | Sélectionner tout |
1 2 3 4 | class A {}; class B : public A {}; A* ptr = new B; // le type statique l'objet est A mais son type dynamique est B |
Regardons la différence entre le typage statique/dynamique et le typage faible qui est présent dans bien des langages.
| Code c++ : | Sélectionner tout |
1 2 | x = 10; x = "Hello World"; |
Dans les deux cas, x n'est ni de type numérique ni de type chaîne de caractères, c'est une juste variable qui contient une valeur se comportant d'une certaine façon. C'est le typage faible.
L'inférence de type est autre chose. Elle consiste à détecter automatiquement le type statique d'une variable, sans que celui-ci ne soit explicité dans le code source via le mot clé auto.
Néanmoins, cette détection possède ses propres limites, le type assigné va au plus simple possible :
| Code c++ : | Sélectionner tout |
auto s = "blabla"; // ici s est de type const char* alors qu'on aurait voulu l'avoir de type std::string
Proposer une nouvelle réponse sur la FAQ
Ce n'est pas l'endroit pour poser des questions, allez plutôt sur le forum de la rubrique pour ça
Les sources présentées sur cette page sont libres de droits et vous pouvez les utiliser à votre convenance. Par contre, la page de présentation constitue une uvre intellectuelle protégée par les droits d'auteur. Copyright © 2026 Developpez Developpez LLC. Tous droits réservés Developpez LLC. Aucune reproduction, même partielle, ne peut être faite de ce site et de l'ensemble de son contenu : textes, documents et images sans l'autorisation expresse de Developpez LLC. Sinon vous encourez selon la loi jusqu'à trois ans de prison et jusqu'à 300 000 de dommages et intérêts.