



I. Introduction▲
L'écriture de codes performants est toujours une tâche difficile. L'application directe des algorithmes théoriques « purs » n'est pas toujours suffisante dans les architectures du monde réel.
Lorsqu'on a commencé à améliorer la rapidité de ces algorithmes purs, on se trouve rapidement confronté à un dilemme : certaines implémentations s'avèrent relativement rapides sur une architecture, mais effroyablement lentes sur d'autres. Dans le même temps, dans certains contextes, une nouvelle implémentation va dépasser les performances de la première, mais perdre de la vitesse sur les autres calculs.
De nombreuses optimisations, grandes et petites, pour chacune des architectures prises en charge peuvent rapidement faire gonfler notre code et nous faire perdre du temps. Souvent, nous sommes donc ramenés à choisir entre deux options : un beau code trop lent, ou bien un code rapide mais illisible.
On peut donc se demander ce qu'il en est des optimisations des compilateurs modernes ?
De nos jours, les compilateurs font beaucoup de choses, mais clairement pas tout. Par exemple, les algorithmes décrits dans cet article ne peuvent pas vraiment être optimisés ni vectorisés du fait de leur complexité.
Dans ce tutoriel, je montre cependant comment le C++17 et le C++14 peuvent aider à obtenir un code rapide, condensé, et bien structuré.
II. Les transformées de Fourier rapides que l'on peut encore accélérer▲
La transformée de Fourier rapide (FFT) est un algorithme au cœur du traitement de signal numérique et a de nombreuses applications dans beaucoup d'autres domaines.
En quelques mots, la FFT fait passer les données (le signal) du domaine temporel (chaque échantillon représente le signal à un temps donné) au domaine des fréquences (chaque échantillon représente la puissance d'une fréquence donnée).
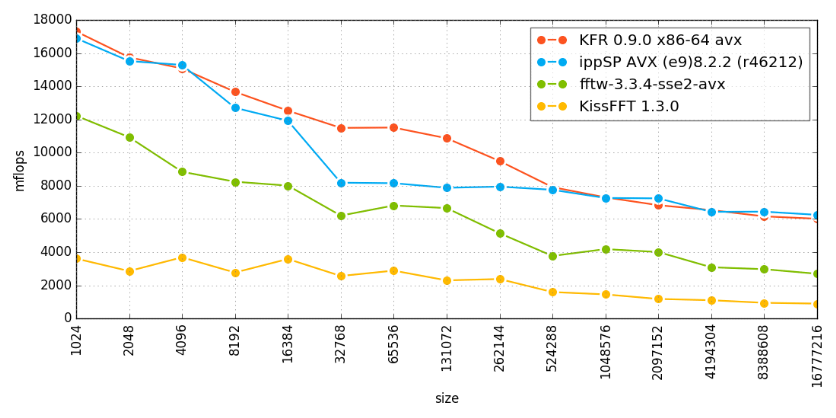
La performance d'une implémentation de transformée de Fourier impacte souvent sur la performance globale d'une application, du fait du grand nombre de transformations effectuées. Dans le KFR Framework, certaines parties de l'implémentation de la FFT ont été grandement améliorées par l'utilisation du C++14, comme illustré en Figure 1.
Note du traducteur : La figure 1 ci-dessous illustre une étude de cas de vitesse pour une FFT par Dan Levin sous GitHub.
II-A. Exemple 1 : Spécialisation ▲
Pour atteindre sa vitesse maximale, la FFT doit être spécialisée quand on l'applique à des vecteurs de petite taille, par exemple 2, 4, 8, 16, 32, 64, 128, 256. L'exemple suivant montre comment sélectionner une taille, connue uniquement à l'exécution (au runtime).
Version C++14 (source code on GitHub) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
cswitch(csizes<1, 2, 3, 4, 5, 6, 7, 8>, log2n,
[&](auto log2n) { // si log2n a été trouvé dans la liste, créer une étape spécialisée
add_stage<internal::fft_specialization_t<T, val_of(log2n), false>::template type>(size, type);
},
[&]() { // si log2n n'a pas été trouvé dans la liste, créer une étape générique
// l'étape générique a deux spécialisations pour les valeurs paires et impaires de log2n, donc on sélectionne la bonne
cswitch(cfalse_true, is_even(log2n), [&](auto is_even) {
make_fft(size, type, is_even, ctrue);
add_stage<internal::fft_reorder_stage_impl_t<T, val_of(is_even)>::template type>(size, type);
});
});
Ci-dessus, j'utilise cswitch, cif et d'autres fonctions de la bibliothèque CoMeta C++14 Metaprogramming library (licence MIT), écrit lors du développement du KFR Framework.
Le code précédent est équivalent à ce code, écrit en C++03 ou bien C++11 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
switch(log2n)
{
case 1:
add_stage<internal::fft_specialization_t<T, 1, false>::template type>(size, type);
break;
case 2:
add_stage<internal::fft_specialization_t<T, 2, false>::template type>(size, type);
break;
case 3:
add_stage<internal::fft_specialization_t<T, 3, false>::template type>(size, type);
break;
case 4:
add_stage<internal::fft_specialization_t<T, 4, false>::template type>(size, type);
break;
case 5:
add_stage<internal::fft_specialization_t<T, 5, false>::template type>(size, type);
break;
case 6:
add_stage<internal::fft_specialization_t<T, 6, false>::template type>(size, type);
break;
case 7:
add_stage<internal::fft_specialization_t<T, 7, false>::template type>(size, type);
break;
case 8:
add_stage<internal::fft_specialization_t<T, 8, false>::template type>(size, type);
break;
default:
if(is_even(log2n))
{
make_fft(size, type, cbool<true>, ctrue);
add_stage<internal::fft_reorder_stage_impl_t<T, true>::template type>(size, type);
}
else
{
make_fft(size, type, cbool<false>, ctrue);
add_stage<internal::fft_reorder_stage_impl_t<T, false>::template type>(size, type);
}
}
Une autre façon d'obtenir ce résultat avec C++11 consiste à extraire le code vers un nouveau foncteur, rendre générique l'opérateur d'appel (operator()) de ce nouveau foncteur (afin de pouvoir accéder aux valeurs pendant la compilation), et lui passer en entrée toutes les variables locales. Mais ceci introduit une complexité indésirable dans le code et dans tous les cas n'est pas plus aisé que l'utilisation de cswitch en C++14.
II-A-1. La fonction cswitch▲
Cette fonction est utilisée lorsqu'une valeur connue en cours d'exécution doit apparaître dans une liste d'arguments d'un template. Il n'y a qu'une seule façon d'y arriver en interne : il faut comparer la valeur renvoyée par le code à chacune des valeurs de la liste prédéfinie, et appeler l'instance de template associée. Mais le C++14 nous aide bien dans cette situation et nous n'avons plus à écrire à la main chacune des comparaisons. Concrètement, la lambda générique est la clef qui fait fonctionner le code.
Ci-dessous le code de cswitch (source GitHub) :
2.
3.
4.
5.
6.
7.
8.
template <typename T, T... vs, typename U, typename Function, typename Fallback = DoNothing>
void cswitch(cvals_t<T, vs...>, const U& value, Function&& function, Fallback&& fallback = Fallback())
{
bool result = false;
swallow{ (result = result || ((vs == value) ? (function(cval<T, vs>), void(), true) : false), void(), 0)... };
if(!result)
fallback();
}
Comme on peut le constater, la fonction fallback est optionnelle.
Lors de l'instanciation, le code sera développé comme une séquence de comparaisons.
2.
3.
4.
5.
6.
7.
bool result = false;
result = result || ((vs == value) ? (function(cval<T, vs>), void(), true) : false);
result = result || ((vs == value) ? (function(cval<T, vs>), void(), true) : false);
...
result = result || ((vs == value) ? (function(cval<T, vs>), void(), true) : false);
if(!result)
fallback();
swallow est une structure avec un constructeur qui accepte initializer_list.
La liste d'initialisation est utilisée pour s'assurer que les arguments sont évalués dans l'ordre où ils apparaissent. La version C++17 à venir introduira les fold expressions (expressions repliées) qui peuvent être utilisées pour obtenir le même effet sous une forme plus élégante.
II-B. SIMD et C++▲
La FFT est constituée de courtes routines appelées papillons qui gagneront fortement à être optimisées en termes d'utilisation des registres SIMD. Le total des spécialisations nécessaires pour un algorithme des FFT est donné par :
- Deux types de données : float et double, donc on démarre par deux spécialisations.
- Le code est à optimiser pour SSE.x et AVX.x qui occupent des tailles de registre SIMD différentes : 4.
- Le x86 possède 8 registres SIMD (même sur les AVX), tandis que le x86-64 en possède 16. En x86-64 on peut doubler la quantité de calculs réalisés en une étape grâce à l'utilisation de deux registres à la place d'un seul.
On ne peut pas décemment laisser passer cette opportunité, ce qui double notre nombre de spécialisations.
On a donc à présent 8 spécialisations. - Afin de pouvoir appliquer à la fois les opérations de FFT et leur inverse, en utilisant les mêmes données précalculées (la TF inverse utilise exactement le même algorithme que la TF directe, mais elle fonctionne avec les coefficients conjugués), il nous faut modifier tous nos papillons : 16.
- L'une des étapes de la FFT multiplie systématiquement les données d'entrées par 1.0, en conséquence, on peut (et on doit, si l'on veut atteindre notre objectif de performance) totalement retirer cette étape de multiplication.
Le nombre de spécialisations devient 32. - Les données peuvent être alignées ou pas.
Les accès à des données alignées en utilisant des instructions non alignées seront lents sur les SSE.
Les accès à des données non alignées en utilisant des instructions alignées amèneront toujours à une segfault.
Il en résulte qu'on doit compter sur 48 spécialisations.
Une fois de plus, 48 spécialisations sont ainsi obtenues pour le papillon radix-4. Certaines de ces spécialisations sont redondantes, mais un comptage global des implémentations optimisées nous amène bien au-delà de 20.
En C, nous aurions eu à écrire et maintenir l'ensemble de ces fonctions.
Et si je vous disais que toutes ces spécialisations ont une syntaxe de code unique dans C++14 ? Toutes ces différentiations nécessaires pour atteindre les meilleurs résultats dans chacune des configurations peuvent être passées en tant qu'arguments template.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
template <size_t width, bool use_br2, bool inverse, bool aligned, typename T>
inline void radix4_body(
size_t N, // dimension du vecteur fft
csize_t<width>, // largeur de la SIMD
cfalse_t,
cfalse_t,
cfalse_t,
cbool_t<use_br2>, // appliquer une permutation par renversement de bits (« bit-reversal »)
cbool_t<inverse>, // vrai dans le cas de la FFT inverse
cbool_t<aligned>, // vrai si on a des accès alignés
complex<T>* out,
const complex<T>* in,
const complex<T>* twiddle)
{
const size_t N4 = N / 4;
cvec<T, width> w1, w2, w3;
cvec<T, width> sum02, sum13, diff02, diff13;
cvec<T, width> a0, a1, a2, a3;
a0 = cread<width, aligned>(in + 0);
a2 = cread<width, aligned>(in + N4 * 2);
sum02 = a0 + a2;
a1 = cread<width, aligned>(in + N4);
a3 = cread<width, aligned>(in + N4 * 3);
sum13 = a1 + a3;
cwrite<width, aligned>(out, sum02 + sum13);
w2 = sum02 - sum13;
cwrite<width, aligned>(
out + N4 * (use_br2 ? 1 : 2),
radix4_apply_twiddle(csize<width>, cfalse, cbool<inverse>, w2, cread<width, true>(twiddle + width)));
diff02 = a0 - a2;
diff13 = a1 - a3;
if (inverse)
{
diff13 = (diff13 ^ broadcast<width * 2, T>(T(), -T()));
diff13 = swap<2>(diff13);
}
else
{
diff13 = swap<2>(diff13);
diff13 = (diff13 ^ broadcast<width * 2, T>(T(), -T()));
}
w1 = diff02 + diff13;
cwrite<width, aligned>(
out + N4 * (use_br2 ? 2 : 1),
radix4_apply_twiddle(csize<width>, cfalse, cbool<inverse>, w1, cread<width, true>(twiddle + 0)));
w3 = diff02 - diff13;
cwrite<width, aligned>(out + N4 * 3, radix4_apply_twiddle(csize<width>, cfalse, cbool<inverse>, w3,
cread<width, true>(twiddle + width * 2)));
}
De plus, le papillon opère sur le type vec<T, width> qui n'affiche plus tous les détails d'implémentation et présente une interface publique unifiée.
C++ possède bien plus d'avantages que le C en termes de réutilisation du code.
Mais C++14 va encore plus loin.
III. Exemples complémentaires▲
Ces quelques fonctions tirent avantage du C++11 ou bien du C++14.
III-A. counter▲
Probablement la plus simple des fonctions du KFR Framework.
counter est un générateur, qui renvoie séquentiellement les valeurs à partir de 0 (GitHub).
2.
3.
4.
5.
6.
inline auto counter()
{
return lambda([](cinput_t, size_t index, auto x) {
return enumerate(x) + index;
});
}
cinput_t indique que nous lisons dans une expression et non pas que nous y écrivons. Ce type est utilisé pour faire la distinction entre ce que l'on veut faire lorsqu'un objet implémente des operator() à la fois d'entrée et de sortie.
index prend sa valeur de la variable de boucle for lorsque l'expression template est exécutée.
x contrôle le type du résultat renvoyé par cette fonction.
lambda encapsule la lambda dans un objet-expression.
Sans l'utilisation des lambda génériques, nous aurions à écrire un foncteur avec un operator() générique.
III-B. sequence▲
Cette fonction renvoie des valeurs données dans une séquence et retourne à son point de départ lorsqu'elle arrive à la fin.
Cette fonction utilise l'initialisation des captures de lambda, la déduction du type de retour pour une fonction normale et les lambda génériques, qui sont tous dans le standard C++14.
2.
3.
4.
5.
6.
7.
template <typename... Ts, typename T = common_type<Ts...>>
inline auto sequence(const Ts&... list)
{
return lambda([seq = std::array<T, sizeof...(Ts)>{ list... }](size_t index) {
return seq[index % seq.size()];
});
}
IV. Conclusion▲
Les standards modernes de C++ sont bien plus que de simples révisions de syntaxe ou bien de nouvelles fonctions et types de variables.
Ils présentent de nombreuses améliorations concrètes, y compris quand il s'agit d'implémenter un logiciel dédié à la haute performance, et aident à gérer explicitement les optimisations et la vectorisation dans le but d'obtenir les performances optimales tout en conservant du code léger.
Avec les standards modernes de C++, les codes peuvent être tout à la fois rapides, beaux, ajustables et maintenables.
V. Remerciements▲
Note de la traduction : l'article original (en anglais) a été écrit par Dan Levin.
Nous tenons à remercier scsab pour la traduction, JolyLoic pour sa relecture technique, Winjerome pour la mise au gabarit et f-leb pour la relecture orthographique.