



I. Les motivations▲
J’ai commencé la rédaction de ce billet, car j’ai rencontré un problème similaire dans le cadre de mon travail il y a quelques temps. Le code d’une zone de notre système compactait des résultats booléens de conditions en bits. Je me demandais s'il était possible d’optimiser ce processus. Cet algorithme n’est pas des plus complexes, mais comme à l’accoutumée, il ouvre la réflexion sur des détails et solutions intéressantes. Alors j’ai décidé de partager cette réflexion avec mes lecteurs.
Pour illustrer le problème, on peut considérer une image en niveaux de gris. On veut générer à partir de celle-ci une autre image composée uniquement de deux couleurs : noir et blanc. On utilise un seuil qui va permettre de distinguer les pixels blancs et noirs à partir de l’image d’origine.
outputColor[x][y] = inputColor[x][y] > Threshold;Le tableau d’entré possède des valeurs comprises entre 0 et 255 mais celui de sortie est composé de booléens (vrai/faux).
La figure ci-dessous nous montre le résultat du ![]() seuillage d’une image :
seuillage d’une image :

Maintenant, on veut compacter ces valeurs booléennes en bits (0 ou 1), pour économiser une grande quantité de mémoire. Si un booléen est implémenté comme un caractère non signé (unsigned char) sur 8 bits, alors on peut économiser 7/8 de notre mémoire !
Par exemple, pour une image en niveau de gris d’une dimension de 256 par 512 pixels qui utiliserait 128 ko, on utilise alors seulement 16 ko.
kitxmlcodelatexdvp256 \times 512 = 131072\,(octets) = 128\,Kofinkitxmlcodelatexdvp kitxmlcodelatexdvp\frac{131072}{8} = 16384\,(octets) = 16\,KofinkitxmlcodelatexdvpCela devrait être simple à implémenter non ?
II. L’algorithme▲
Pour que les choses soient claires, supposons que nous ayons :
-
en entrée :
- un tableau d’entiers,
- la longueur de ce tableau : N,
- la valeur du seuil ;
-
en sortie :
- un tableau d’octets de longueur M,
M est le nombre d’octets nécessaires pour écrire N bits,
le ième bit du tableau est mis à 1 lorsque la ième valeur du tableau d’entiers est supérieure au seuil donné.
Voici un bref pseudocode :
2.
3.
4.
5.
6.
7.
8.
9.
for i = 0...N-1
octet = pack (input[i] > threshold,
input[i+1] > threshold,
...,
input[i+7] > threshold)
output[i/8] = Octet
i+=8
// Prendre en charge le cas où N n’est pas divisible par 8
Une autre solution est de supprimer le seuil en entrée et de prendre juste un tableau de booléens (plus besoin d’effectuer les comparaisons).
III. Les inconvénients▲
Avec la version compactée nous économisons de la mémoire, mais il y a des instructions supplémentaires pour décompacter les valeurs. Parfois ce calcul additionnel peut causer un ralentissement de tout le processus ! Il faut toujours mesurer encore et encore, car chaque cas peut être différent.
Ce problème est similaire aux algorithmes de compression, bien que le compactage soit une opération bien plus rapide. Comme toujours, il y a conflit entre le stockage et la puissance de calcul (![]() compromis temps-mémoire).
compromis temps-mémoire).
IV. Benchmark▲
Je veux comparer plusieurs implémentations :
- celle de référence, sans compactage. On stocke simplement les valeurs booléennes ;
- std::bitset ;
- std::vector de booléens ;
- une version « manuelle » ;
- une seconde version « manuelle » ;
- une version avec la valeur du seuil à 127.
Ce qui représente 50 % de chances d’obtenir vrai et vrai.
En ce qui concerne la bibliothèque de test, nous utiliserons Celero. Vous pouvez trouver plus de détails sur son utilisation dans ce billet qui parle des ![]() bibliothèques de tests de performance en C++.
bibliothèques de tests de performance en C++.
Avec Celero, il existe une manière simple de définir différentes options pour les tests de performances. Par exemple, si l’on souhaite exécuter le code avec des tableaux d’entrée de tailles différentes (100 k, 200 k éléments). Il y a également une manière propre pour fournir des méthodes d’initialisation/désactivation qui seront appelées avant et après chaque exécution.
La composante permanente de base fournit le tableau d’entrée :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
inputValues.reset(new int[N]);
referenceValues.reset(new bool[N]);
arrayLength = N;
//Standard mersenne_twister_engine seeded with 0, constant
std::mt19937 gen(0);
std::uniform_int_distribution<> dist(0, 255);
// renseigner tous les octets
for (int64_t i = 0; i < experimentValue; ++i)
{
inputValues[i] = dist(gen);
referenceValues[i] = inputValues[i] > ThresholdValue;
}
V. Le test de référence▲
Dans la première version de ce post, j’utilisais la version std ::bitset comme test de référence, mais cela peut être trompeur. Il est bien mieux de voir la version sans compactage comme test de référence, ainsi on peut voir s'il y a un réel gain.
Il peut arriver que les versions avec compactage soient plus lentes que l’approche n’en comportant pas.
Le code de test est le suivant :
2.
for (size_t i = 0; i < arrayLength; ++i)
outputValues[i] = inputValues[i] > ThresholdValue;
outputValues est un tableau de booléens.
VI. std::bitset<N>▲
Cette version est vraiment très simple :
for (int64_t i = 0; i < arrayLength; ++i)
outputBitset.set(i, inputValues[i] > ThresholdValue);Le seul inconvénient avec l’utilisation de std::bitset est que la valeur N doit être une constante connue lors de la compilation. De plus std::bitset dépend de son implémentation, on ne sait donc pas comment la mémoire est utilisée en interne. Nous n’utiliserons pas cette version dans le code final, cependant c’est un bon test pour la comparaison.
Voici les modifications apportées pour cette version du programme :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
class StdBitsetFixture : public CompressBoolsFixture
{
public:
virtual void tearDown()
{
for (int64_t i = 0; i < arrayLength; ++i)
Checker(outputBitset[i], referenceValues[i], i);
}
std::bitset<MAX_ARRAY_LEN> outputBitset;
};
Dans la fonction membre tearDown nous comparons les valeurs générées avec celles de référence - Checker vérifie simplement les valeurs et affiche un message si elles ne sont pas égales.
VII. std::vector<bool>▲
Voici un autre code simple. Mais cette fois le vecteur est plus utile comme il est dynamique et le code reste très simple.
2.
for (int64_t i = 0; i < arrayLength; ++i)
outputVector[i] = inputValues[i] > ThresholdValue;
Les modifications :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
class StdVectorFixture : public CompressBoolsFixture
{
public:
virtual void setUp(int64_t experimentValue) override
{
CompressBoolsFixture::setUp(experimentValue);
outputVector.resize(experimentValue);
}
virtual void tearDown()
{
for (int64_t i = 0; i < arrayLength; ++i)
Checker(outputVector[i], referenceValues[i], i);
}
std::vector<bool> outputVector;
};
Cette fois nous générons le vecteur dynamiquement en utilisant experimentValue (N – taille du tableau).
Pour rappel, vector<bool> est une implémentation spécifique de vecteur. Il ne contient pas un tableau de booléens, il contient des bits (d’une manière non spécifiée). Il devrait utiliser beaucoup moins de mémoire que la version non compactée.
Tout de même, le choix d’un vector<bool> n’est peut-être pas le bon pour la version de production ; voir cette ![]() règle17.1.1 Do not use std::vector | High Integrity C++ Coding Standard.
règle17.1.1 Do not use std::vector | High Integrity C++ Coding Standard.
VIII. Version manuelle▲
Les deux premières versions (ainsi que celle de référence) étaient juste un point de départ, nous allons maintenant créer une véritable version manuelle :).
Je dis manuelle car toute la mémoire sera gérée par du code que nous aurons écrit. Aussi, il n’y aura pas de couche d’abstraction pour attribuer/récupérer les bits.
La fonction membre setup sera donc :
2.
3.
4.
5.
6.
7.
virtual void setUp(int64_t experimentValue) override
{
CompressBoolsFixture::setUp(experimentValue);
numOctets = (experimentValue + 7) / 8;
numFullOctets = (experimentValue) / 8;
outputValues.reset(new uint8_t[numOctets]);
}
La variable outputValue est simplement un unique_ptr contenant un tableau de uint8_t. Nous avons N/8 octets pleins plus un à la fin qui peut être partiellement rempli.
Le premier cas utilise seulement une variable pour construire l’octet. Quand il est complet (stockage de 8 bits), nous pouvons le sauvegarder dans le tableau de sortie :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
uint8_t OutOctet = 0;
int shiftCounter = 0;
auto pInputData = inputValues.get();
auto pOutputOctet = outputValues.get();
for (int64_t i = 0; i < arrayLength; ++i)
{
if (*pInputData > ThresholdValue)
OutOctet |= (1 << shiftCounter);
pInputData++;
shiftCounter++;
if (shiftCounter > 7)
{
*pOutputOctet++ = OutOctet;
OutOctet = 0;
shiftCounter = 0;
}
}
// Notre octet peut être incomplet, il faut prendre ce cas en
// considération
if (arrayLength & 7)
*pOutputOctet++ = OutOctet;
IX. Améliorations▲
La première version manuelle a un petit défaut. Comme on peut le voir, une seule valeur est utilisée pour tous les calculs. Ce n’est pas très efficace, car on utilise très peu ![]() l’architecture du processeur.
l’architecture du processeur.
Donc nous utiliserons l’idée suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
uint8_t Bits[8] = { 0 };
const int64_t lenDivBy8 = (arrayLength / 8) * 8;
auto pInputData = inputValues.get();
auto pOutputOctet = outputValues.get();
for (int64_t i = 0; i < lenDivBy8; i += 8)
{
Bits[0] = pInputData[0] > ThresholdValue ? 0x01 : 0;
Bits[1] = pInputData[1] > ThresholdValue ? 0x02 : 0;
Bits[2] = pInputData[2] > ThresholdValue ? 0x04 : 0;
Bits[3] = pInputData[3] > ThresholdValue ? 0x08 : 0;
Bits[4] = pInputData[4] > ThresholdValue ? 0x10 : 0;
Bits[5] = pInputData[5] > ThresholdValue ? 0x20 : 0;
Bits[6] = pInputData[6] > ThresholdValue ? 0x40 : 0;
Bits[7] = pInputData[7] > ThresholdValue ? 0x80 : 0;
*pOutputOctet++ = Bits[0] | Bits[1] | Bits[2] | Bits[3] |
Bits[4] | Bits[5] | Bits[6] | Bits[7];
pInputData += 8;
}
if (arrayLength & 7)
{
auto RestW = arrayLength & 7;
memset(Bits, 0, 8);
for (long long i = 0; i < RestW; ++i)
{
Bits[i] = *pInputData == ThresholdValue ? 1 << i : 0;
pInputData++;
}
*pOutputOctet++ = Bits[0] | Bits[1] | Bits[2] | Bits[3] | Bits[4] | Bits[5] | Bits[6] | Bits[7];
}
Que se passe-t-il ici ?
Au lieu de travailler sur une seule variable, nous en utilisons huit différentes où nous stockons le résultat de la condition. Il reste tout de même un problème lorsque l’on effectue l’opération « OU ». Pour le moment, je ne sais pas comment améliorer cela. Peut-être avez-vous des astuces (sans utilisation d’instruction SIMD) ?
X. Résultats▲
Était-il judicieux d’utiliser cette approche à plusieurs variables ? Les résultats parlent d’eux-même !
Intel i7 4720HQ, 12GB Ram, 512 SSD, Windows 10. Visual Studio 2017, 32bit :
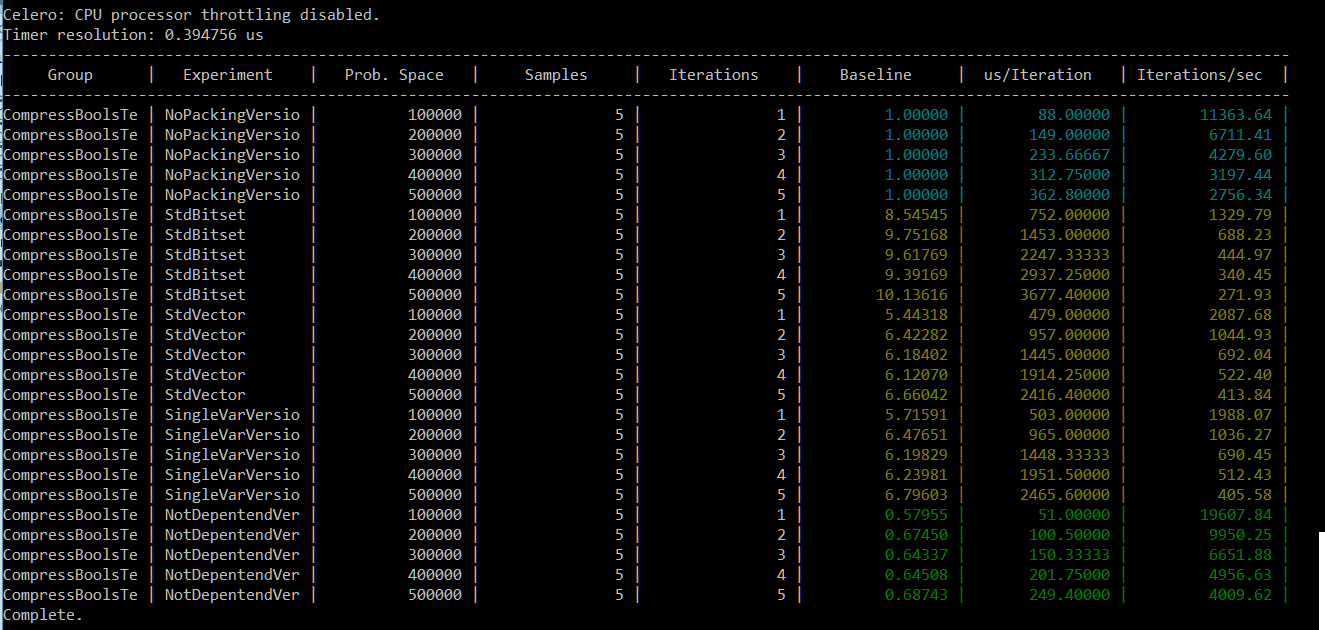
La version optimisée (utilisant des variables séparées) est cinq fois plus rapide que la méthode bitset et presque 3,5 fois plus rapide que la première version manuelle !
Le graphique :
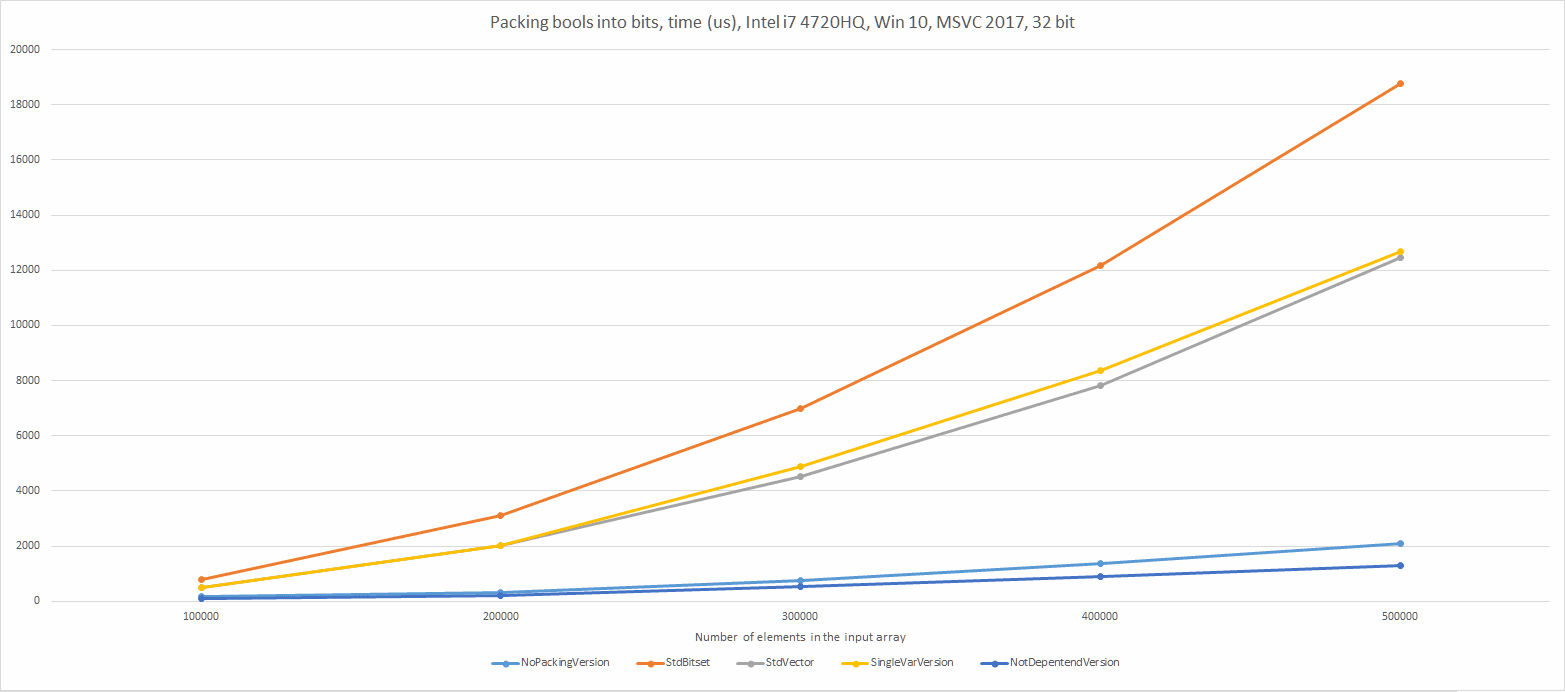
Il y a une raison supplémentaire qui fait que la version optimisée est plus rapide. Vous pouvez en lire plus dans ce ![]() billet de blog. De fait, la première version utilise des embranchements tandis que la version optimisée peut utiliser des instructions move conditionnelles (ce qui dans ce cas améliore les performances).
billet de blog. De fait, la première version utilise des embranchements tandis que la version optimisée peut utiliser des instructions move conditionnelles (ce qui dans ce cas améliore les performances).
XI. En résumé▲
Même un problème qui peut paraître simple aux premiers abords peut poser des soucis lors de l’utilisation (je l’espère) d’un test correct de performance. Au départ, j’ai choisi d’utiliser bitset comme référence, mais il est bien mieux d'y placer une version sans compactage. Maintenant, nous savons que le compactage peut ralentir le processus (avec l’utilisation d’une structure de données non appropriée). La version manuelle semble être meilleure, elle peut potentiellement faire une économie de 7/8 de la mémoire et est plus rapide de 20 à 30 % que la version sans compactage.
Sans regarder la pile d’appels, la première version est optimisée en utilisant plus de variables pour l’évaluation des conditions. De cette manière, il y a moins de dépendance au niveau des données et le CPU peut être plus performant.
Dans le futur j’essayerai de paralléliser le code. Que se passera-t-il en utilisant plus de threads ou plus d’appels d’instructions de vecteur ? Par exemple, j’ai trouvé une instruction intéressante appelée : _mm_movemask_epi8.
Code sur Github.
XII. Remerciements▲
Nous tenons à remercier Bartlomiej Filipek qui nous a autorisés à traduire et publier ce tutoriel.
Nous tenons également à remercier smarlytomtom pour la traduction, Luc Hermitte pour la relecture technique et escartefigue pour la relecture orthographique de ce tutoriel.