


8. C++ : la couche objet▲
La couche objet constitue sans doute la plus grande innovation du C++ par rapport au C. Le but de la programmation objet est de permettre une abstraction entre l'implémentation des modules et leur utilisation, apportant ainsi un plus grand confort dans la programmation. Elle s'intègre donc parfaitement dans le cadre de la modularité. Enfin, l'encapsulation des données permet une meilleure protection et donc une plus grande fiabilité des programmes.
8.1. Généralités▲
Théoriquement, il y a une nette distinction entre les données et les opérations qui leur sont appliquées. En tout cas, les données et le code ne se mélangent pas dans la mémoire de l'ordinateur, sauf cas très particuliers (autoprogrammation, alias pour le chargement des programmes ou des overlays, débogueurs, virus).
Cependant, l'analyse des problèmes à traiter se présente d'une manière plus naturelle si l'on considère les données avec leurs propriétés. Les données constituent les variables, et les propriétés les opérations qu'on peut leur appliquer. De ce point de vue, les données et le code sont logiquement inséparables, même s'ils sont placés en différents endroits de la mémoire de l'ordinateur.
Ces considérations conduisent à la notion d'objet. Un objet est un ensemble de données sur lesquelles des procédures peuvent être appliquées. Ces procédures ou fonctions applicables aux données sont appelées méthodes. La programmation d'un objet se fait donc en indiquant les données de l'objet et en définissant les procédures qui peuvent lui être appliquées.
Il se peut qu'il y ait plusieurs objets identiques, dont les données ont bien entendu des valeurs différentes, mais qui utilisent le même jeu de méthodes. On dit que ces différents objets appartiennent à la même classe d'objets. Une classe constitue donc une sorte de type, et les objets de cette classe en sont des instances. La classe définit donc la structure des données, alors appelées champs ou variables d'instances, que les objets correspondants auront, ainsi que les méthodes de l'objet. À chaque instanciation, une allocation de mémoire est faite pour les données du nouvel objet créé. L'initialisation de l'objet nouvellement créé est faite par une méthode spéciale, le constructeur. Lorsque l'objet est détruit, une autre méthode est appelée : le destructeur. L'utilisateur peut définir ses propres constructeurs et destructeurs d'objets si nécessaire.
Comme seules les valeurs des données des différents objets d'une classe diffèrent, les méthodes sont mises en commun pour tous les objets d'une même classe (c'est-à-dire que les méthodes ne sont pas recopiées). Pour que les méthodes appelées pour un objet sachent sur quelles données elles doivent travailler, un pointeur sur l'objet contenant ces données leur est passé en paramètre. Ce mécanisme est complètement transparent pour le programmeur en C++.
Nous voyons donc que non seulement la programmation orientée objet est plus logique, mais elle est également plus efficace (les méthodes sont mises en commun, les données sont séparées).
Enfin, les données des objets peuvent être protégées : c'est-à-dire que seules les méthodes de l'objet peuvent y accéder. Ce n'est pas une obligation, mais cela accroît la fiabilité des programmes. Si une erreur se produit, seules les méthodes de l'objet doivent être vérifiées. De plus, les méthodes constituent ainsi une interface entre les données de l'objet et l'utilisateur de l'objet (un autre programmeur). Cet utilisateur n'a donc pas à savoir comment les données sont gérées dans l'objet, il ne doit utiliser que les méthodes. Les avantages sont immédiats : il ne risque pas de faire des erreurs de programmation en modifiant les données lui-même, l'objet est réutilisable dans un autre programme parce qu'il a une interface standardisée, et on peut modifier l'implémentation interne de l'objet sans avoir à refaire tout le programme, pourvu que les méthodes gardent le même nom, les mêmes paramètres et la même sémantique. Cette notion de protection des données et de masquage de l'implémentation interne aux utilisateurs de l'objet constitue ce que l'on appelle l'encapsulation. Les avantages de l'encapsulation seront souvent mis en valeur dans la suite au travers d'exemples.
Nous allons entrer maintenant dans le vif du sujet. Cela permettra de comprendre ces généralités.
8.2. Extension de la notion de type du C▲
Il faut avant tout savoir que la couche objet n'est pas un simple ajout au langage C, c'est une véritable extension. En effet, les notions qu'elle a apportées ont été intégrées au C à tel point que le typage des données de C a fusionné avec la notion de classe. Ainsi, les types prédéfinis char, int, double, etc. représentent à présent l'ensemble des propriétés des variables ayant ce type. Ces propriétés constituent la classe de ces variables, et elles sont accessibles par les opérateurs. Par exemple, l'addition est une opération pouvant porter sur des entiers (entre autres) qui renvoie un objet de la classe entier. Par conséquent, les types de base se manipuleront exactement comme des objets. Du point de vue du C++, les utiliser revient déjà à faire de la programmation orientée objet.
De même, le programmeur peut, à l'aide de la notion de classe d'objets, définir de nouveaux types. Ces types comprennent la structure des données représentées par ces types et les opérations qui peuvent leur être appliquées. En fait, le C++ assimile complètement les classes avec les types, et la définition d'un nouveau type se fait donc en définissant la classe des variables de ce type.
8.3. Déclaration de classes en C++▲
Afin de permettre la définition des méthodes qui peuvent être appliquées aux structures des classes C++, la syntaxe des structures C a été étendue (et simplifiée). Il est à présent possible de définir complètement des méthodes dans la définition de la structure. Cependant il est préférable de la reporter et de ne laisser que leur déclaration dans la structure. En effet, cela accroît la lisibilité et permet de masquer l'implémentation de la classe à ses utilisateurs en ne leur montrant que sa déclaration dans un fichier d'en-tête. Ils ne peuvent donc ni la voir, ni la modifier (en revanche, ils peuvent toujours voir la structure de données utilisée par son implémentation).
La syntaxe est la suivante :
struct Nom
{
[type champs;
[type champs;
[...]]]
[méthode;
[méthode;
[...]]]
};où Nom est le nom de la classe. Elle peut contenir divers champs de divers types.
Les méthodes peuvent être des définitions de fonctions, ou seulement leurs déclarations. Si on ne donne que leurs déclarations, on devra les définir plus loin. Pour cela, il faudra spécifier la classe à laquelle elles appartiennent avec la syntaxe suivante :
type classe::nom(paramètres)
{
/* Définition de la méthode. */
}La syntaxe est donc identique à la définition d'une fonction normale, à la différence près que leur nom est précédé du nom de la classe à laquelle elles appartiennent et de deux deux-points (::). Cet opérateur :: est appelé l'opérateur de résolution de portée. Il permet, d'une manière générale, de spécifier le bloc auquel l'objet qui le suit appartient. Ainsi, le fait de précéder le nom de la méthode par le nom de la classe permet au compilateur de savoir de quelle classe cette méthode fait partie. Rien n'interdit, en effet, d'avoir des méthodes de même signature, pourvu qu'elles soient dans des classes différentes.
struct Entier
{
int i; // Donnée membre de type entier.
// Fonction définie à l'intérieur de la classe :
int lit_i(void)
{
return i;
}
// Fonction définie à l'extérieur de la classe :
void ecrit_i(int valeur);
};
void Entier::ecrit_i(int valeur)
{
i=valeur;
return ;
}Note : Si la liste des paramètres de la définition de la fonction contient des initialisations supplémentaires à celles qui ont été spécifiées dans la déclaration de la fonction, les deux jeux d'initialisations sont fusionnées et utilisées dans le fichier où la définition de la fonction est placée. Si les initialisations sont redondantes ou contradictoires, le compilateur génère une erreur.
Note : L'opérateur de résolution de portée permet aussi de spécifier le bloc d'instructions d'un objet qui n'appartient à aucune classe. Pour cela, on ne mettra aucun nom avant l'opérateur de résolution de portée. Ainsi, pour accéder à une fonction globale à l'intérieur d'une classe contenant une fonction de même signature, on fera précéder le nom de la fonction globale de cet opérateur.
int valeur(void) // Fonction globale.
{
return 0;
}
struct A
{
int i;
void fixe(int a)
{
i=a;
return;
}
int valeur(void) // Même signature que la fonction globale.
{
return i;
}
int global_valeur(void)
{
return ::valeur(); // Accède à la fonction globale.
}
};De même, l'opérateur de résolution de portée permettra d'accéder à une variable globale lorsqu'une autre variable homonyme aura été définie dans le bloc en cours. Par exemple :
int i=1; // Première variable de portée globale
int main(void)
{
if (test())
{
int i=3; // Variable homonyme de portée locale.
int j=2*::i; // j vaut à présent 2, et non pas 6.
/* Suite ... */
}
/* Suite ... */
return 0;
}Les champs d'une classe peuvent être accédés comme des variables normales dans les méthodes de cette classe.
struct client
{
char Nom[21], Prenom[21]; // Définit le client.
unsigned int Date_Entree; // Date d'entrée du client
// dans la base de données.
int Solde;
bool dans_le_rouge(void)
{
return (Solde<0);
}
bool bon_client(void) // Le bon client est
// un ancien client.
{
return (Date_Entree<1993); // Date limite : 1993.
}
};Dans cet exemple, le client est défini par certaines données. Plusieurs méthodes sont définies dans la classe même.
L'instanciation d'un objet se fait comme celle d'une simple variable :
classe objet;Par exemple, si on a une base de données devant contenir 100 clients, on peut faire :
client clientele[100]; /* Instancie 100 clients. */On remarquera qu'il est à présent inutile d'utiliser le mot clé struct pour déclarer une variable, contrairement à ce que la syntaxe du C exigeait.
L'accès aux méthodes de la classe se fait comme pour accéder aux champs des structures. On donne le nom de l'objet et le nom du champ ou de la méthode, séparés par un point. Par exemple :
/* Relance de tous les mauvais payeurs. */
int i;
for (i=0; i<100; ++i)
if (clientele[i].dans_le_rouge()) relance(clientele[i]);Lorsque les fonctions membres d'une classe sont définies dans la déclaration de cette classe, le compilateur les implémente en inline (à moins qu'elles ne soient récursives ou qu'il existe un pointeur sur elles).
Si les méthodes ne sont pas définies dans la classe, la déclaration de la classe sera mise dans un fichier d'en-tête, et la définition des méthodes sera reportée dans un fichier C++, qui sera compilé et lié aux autres fichiers utilisant la classe client. Bien entendu, il est toujours possible de déclarer les fonctions membres comme étant des fonctions inline même lorsqu'elles sont définies en dehors de la déclaration de la classe. Pour cela, il faut utiliser le mot clé inline, et placer le code de ces fonctions dans le fichier d'en-tête ou dans un fichier .inl.
Sans fonctions inline, notre exemple devient :
struct client
{
char Nom[21], Prenom[21];
unsigned int Date_Entree;
int Solde;
bool dans_le_rouge(void);
bool bon_client(void);
};
/*
Attention à ne pas oublier le ; à la fin de la classe dans un
fichier .h ! L'erreur apparaîtrait dans tous les fichiers ayant
une ligne #include "client.h" , parce que la compilation a lieu
après l'appel au préprocesseur.
*//* Inclut la déclaration de la classe : */
#include "client.h"
/* Définit les méthodes de la classe : */
bool client::dans_le_rouge(void)
{
return (Solde<0);
}
bool client::bon_client(void)
{
return (Date_Entree<1993);
}8.4. Encapsulation des données▲
Les divers champs d'une structure sont accessibles en n'importe quel endroit du programme. Une opération telle que celle-ci est donc faisable :
clientele[0].Solde = 25000;Le solde d'un client peut donc être modifié sans passer par une méthode dont ce serait le but. Elle pourrait par exemple vérifier que l'on n'affecte pas un solde supérieur au solde maximal autorisé par le programme (la borne supérieure des valeurs des entiers signés). Par exemple, si les entiers sont codés sur 16 bits, cette borne maximum est 32767. Un programme qui ferait :
clientele[0].Solde = 32800;obtiendrait donc un solde de -12 (valeur en nombre signé du nombre non signé 32800), alors qu'il espérerait obtenir un solde positif !
Il est possible d'empêcher l'accès des champs ou de certaines méthodes à toute fonction autre que celles de la classe. Cette opération s'appelle l'encapsulation.
- public : les accès sont libres ;
- private : les accès sont autorisés dans les fonctions de la classe seulement ;
- protected : les accès sont autorisés dans les fonctions de la classe et de ses descendantes (voir la section suivante) seulement. Le mot clé protected n'est utilisé que dans le cadre de l'héritage des classes. La section suivante détaillera ce point.
Pour changer les droits d'accès des champs et des méthodes d'une classe, il faut faire précéder ceux-ci du mot clé indiquant les droits d'accès suivi de deux points (':'). Par exemple, pour protéger les données relatives au client, on changera simplement la déclaration de la classe en :
struct client
{
private: // Données privées :
char Nom[21], Prenom[21];
unsigned int Date_Entree;
int Solde;
// Il n'y a pas de méthode privée.
public: // Les données et les méthodes publiques :
// Il n'y a pas de donnée publique.
bool dans_le_rouge(void);
bool bon_client(void)
};Outre la vérification de la validité des opérations, l'encapsulation a comme intérêt fondamental de définir une interface stable pour la classe au niveau des méthodes et données membres publiques et protégées. L'implémentation de cette interface, réalisée en privé, peut être modifiée à loisir sans pour autant perturber les utilisateurs de cette classe, tant que cette interface n'est pas elle-même modifiée.
Par défaut, les classes construites avec struct ont tous leurs membres publics. Il est possible de déclarer une classe dont tous les éléments sont par défaut privés. Pour cela, il suffit d'utiliser le mot clé class à la place du mot clé struct.
class client
{
// private est à présent inutile.
char Nom[21], Prenom[21];
unsigned int Date_Entree;
int Solde;
public: // Les données et les méthodes publiques.
bool dans_le_rouge(void);
bool bon_client(void);
};Enfin, il existe un dernier type de classe, que je me contenterai de mentionner : les classes union. Elles se déclarent comme les classes struct et class, mais avec le mot clé union. Les données sont, comme pour les unions du C, situées toutes au même emplacement, ce qui fait qu'écrire dans l'une d'entre elle provoque la destruction des autres. Les unions sont très souvent utilisées en programmation système, lorsqu'un polymorphisme physique des données est nécessaire (c'est-à-dire lorsqu'elles doivent être interprétées de différentes façons selon le contexte).
Note : Les classes de type union ne peuvent pas avoir de méthodes virtuelles et de membres statiques. Elles ne peuvent pas avoir de classes de base, ni servir de classe de base. Enfin, les unions ne peuvent pas contenir des références, ni des objets dont la classe a un constructeur non trivial, un constructeur de copie non trivial ou un destructeur non trivial. Pour toutes ces notions, voir la suite du chapitre.
Les classes définies au sein d'une autre classe sont considérées comme faisant partie de leur classe hôte, et ont donc le droit d'accéder aux données membres private et protected de celle-ci. Remarquez que cette règle est assez récente dans la norme du langage, et que la plupart des compilateurs refuseront ces accès. Il faudra donc déclarer amies de la classe hôte les classes qui sont définies au sein de celle-ci. La manière de procéder sera décrite dans la Section 8.7.2.
8.5. Héritage▲
L'héritage permet de donner à une classe toutes les caractéristiques d'une ou de plusieurs autres classes. Les classes dont elle hérite sont appelées classes mères, classes de base ou classes antécédentes. La classe elle-même est appelée classe fille, classe dérivée ou classe descendante.
Les propriétés héritées sont les champs et les méthodes des classes de base.
Pour faire un héritage en C++, il faut faire suivre le nom de la classe fille par la liste des classes mères dans la déclaration avec les restrictions d'accès aux données, chaque élément étant séparé des autres par une virgule. La syntaxe (donnée pour class, identique pour struct) est la suivante :
class Classe_mere1
{
/* Contenu de la classe mère 1. */
};
[class Classe_mere2
{
/* Contenu de la classe mère 2. */
};]
[...]class Classe_fille : public|protected|private Classe_mere1
[, public|protected|private Classe_mere2 [...]]
{
/* Définition de la classe fille. */
};La signification des mots clés private, protected et public dans l'héritage est récapitulée dans le tableau suivant :
Tableau 8-1. Droits d'accès sur les membres hérités
| mot clé utilisé pour l'héritage | ||||
|---|---|---|---|---|
| Accès aux données | public | protected | private | |
| mot clé utilisé | public | public | protected | private |
| pour les champs | protected | protected | protected | private |
| et les méthodes | private | interdit | interdit | interdit |
Ainsi, les données publiques d'une classe mère deviennent soit publiques, soit protégées, soit privées selon que la classe fille hérite en public, protégé ou en privé. Les données privées de la classe mère sont toujours inaccessibles, et les données protégées deviennent soit protégées, soit privées.
Il est possible d'omettre les mots clés public, protected et private dans la syntaxe de l'héritage. Le compilateur utilise un type d'héritage par défaut dans ce cas. Les classes de type struct utilisent l'héritage public par défaut et les classes de type class utilisent le mot clé private par défaut.
class Emplacement
{
protected:
int x, y; // Données ne pouvant être accédées
// que par les classes filles.
public:
void Change(int, int); // Méthode toujours accessible.
};
void Emplacement::Change(int i, int j)
{
x = i;
y = j;
return;
}
class Point : public Emplacement
{
protected:
unsigned int couleur; // Donnée accessible
// aux classes filles.
public:
void SetColor(unsigned int);
};
void Point::SetColor(unsigned int NewColor)
{
couleur = NewColor; // Définit la couleur.
return;
}Si une classe Cercle doit hériter de deux classes mères, par exemple Emplacement et Forme, sa déclaration aura la forme suivante :
class Cercle : public Emplacement, public Forme
{
/*
Définition de la classe Cercle. Cette classe hérite
des données publiques et protégées des classes Emplacement
et Forme.
*/
};Il est possible de redéfinir les fonctions et les données des classes de base dans une classe dérivée. Par exemple, si une classe B dérive de la classe A, et que toutes deux contiennent une donnée d, les instances de la classe B utiliseront la donnée d de la classe B et les instances de la classe A utiliseront la donnée d de la classe A. Cependant, les objets de classe B contiendront également un sous-objet, lui-même instance de la classe de base A. Par conséquent, ils contiendront la donnée d de la classe A, mais cette dernière sera cachée par la donnée d de la classe la plus dérivée, à savoir la classe B.
Ce mécanisme est général : quand une classe dérivée redéfinit un membre d'une classe de base, ce membre est caché et on ne peut plus accéder directement qu'au membre redéfini (celui de la classe dérivée). Cependant, il est possible d'accéder aux données cachées si l'on connaît leur classe, pour cela, il faut nommer le membre complètement à l'aide de l'opérateur de résolution de portée (::). Le nom complet d'un membre est constitué du nom de sa classe suivi de l'opérateur de résolution de portée, suivis du nom du membre :
classe::membrestruct Base
{
int i;
};
struct Derivee : public Base
{
int i;
int LitBase(void);
};
int Derivee::LitBase(void)
{
return Base::i; // Renvoie la valeur i de la classe de base.
}
int main(void)
{
Derivee D;
D.i=1; // Accède à l'entier i de la classe Derivee.
D.Base::i=2; // Accède à l'entier i de la classe Base.
return 0;
}8.6. Classes virtuelles▲
Supposons à présent qu'une classe D hérite de deux classes mères, les classes B et C. Supposons également que ces deux classes héritent d'une classe mère commune appelée classe A. On a l'arbre « généalogique » suivant :
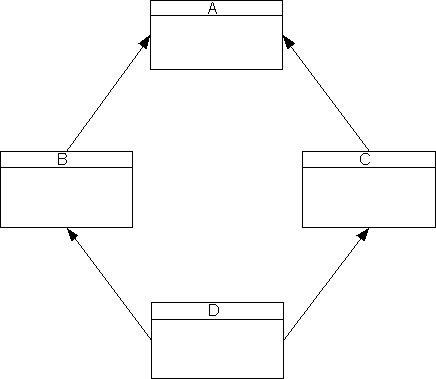
On sait que B et C héritent des données et des méthodes publiques et protégées de A. De même, D hérite des données de B et C, et par leur intermédiaire des données de A. Il se pose donc le problème suivant : quelles sont les données que l'on doit utiliser quand on référence les champs de A ? Celles de B ou celles de C ? On peut accéder aux deux sous-objets de classe A en spécifiant le chemin à suivre dans l'arbre généalogique à l'aide de l'opérateur de résolution de portée. Cependant, cela n'est ni pratique ni efficace, et en général, on s'attend à ce qu'une seule copie de A apparaisse dans D.
Le problème est résolu en déclarant virtuelle la classe de base commune dans la spécification de l'héritage pour les classes filles. Les données de la classe de base ne seront alors plus dupliquées. Pour déclarer une classe mère comme une classe virtuelle, il faut faire précéder son nom du mot clé virtual dans l'héritage des classes filles.
class A
{
protected:
int Donnee; // La donnée de la classe de base.
};
// Héritage de la classe A, virtuelle :
class B : virtual public A
{
protected:
int Valeur_B; // Autre donnée que "Donnee" (héritée).
};
// A est toujours virtuelle :
class C : virtual public A
{
protected:
int valeur_C; // Autre donnée
// ("Donnee" est acquise par héritage).
};
class D : public B, public C // Ici, Donnee n'est pas dupliqué.
{
/* Définition de la classe D. */
};Note : Normalement, l'héritage est réalisé par le compilateur par aggrégation de la structure de données des classes de base dans la structure de données de la classe dérivée. Pour les classes virtuelles, ce n'est en général pas le cas, puisque le compilateur doit assurer l'unicité des données héritées de ces classes, même en cas d'héritage multiple. Par conséquent, certaines restrictions d'usage s'appliquent sur les classes virtuelles.
Premièrement, il est impossible de transtyper directement un pointeur sur un objet d'une classe de base virtuelle en un pointeur sur un objet d'une de ses classes dérivées. Il faut impérativement utiliser l'opérateur de transtypage dynamique dynamic_cast. Cet opérateur sera décrit dans le Chapitre 10.
Deuxièmement, chaque classe dérivée directement ou indirectement d'une classe virtuelle doit en appeler le constructeur explicitement dans son constructeur si celui-ci prend des paramètres. En effet, elle ne peut pas se fier au fait qu'une autre de ses classes de base, elle-même dérivée de la classe de base virtuelle, appelle un constructeur spécifique, car il est possible que plusieurs classes de base cherchent à initialiser différemment chacune un objet commun hérité de la classe virtuelle. Pour reprendre l'exemple donné ci-dessus, si les classes B et C appellaient toutes les deux un constructeur non trivial de la classe virtuelle A, et que la classe D appellait elle-même les constructeurs de B et C, le sous-objet hérité de A serait construit plusieurs fois. Pour éviter cela, le compilateur ignore purement et simplement les appels au constructeur des classes de bases virtuelles dans les classes de base dérivées. Il faut donc systématiquement le spécifier, à chaque niveau de la hiérarchie de classe. La notion de constructeur sera vue dans la Section 8.8
8.7. Fonctions et classes amies▲
Il est parfois nécessaire d'avoir des fonctions qui ont un accès illimité aux champs d'une classe. En général, l'emploi de telles fonctions traduit un manque d'analyse dans la hiérarchie des classes, mais pas toujours. Elles restent donc nécessaires malgré tout.
De telles fonctions sont appelées des fonctions amies. Pour qu'une fonction soit amie d'une classe, il faut qu'elle soit déclarée dans la classe avec le mot clé friend.
Il est également possible de faire une classe amie d'une autre classe, mais dans ce cas, cette classe devrait peut-être être une classe fille. L'utilisation des classes amies peut traduire un défaut de conception.
8.7.1. Fonctions amies▲
Les fonctions amies se déclarent en faisant précéder la déclaration classique de la fonction du mot clé friend à l'intérieur de la déclaration de la classe cible. Les fonctions amies ne sont pas des méthodes de la classe cependant (cela n'aurait pas de sens puisque les méthodes ont déjà accès aux membres de la classe).
class A
{
int a; // Une donnée privée.
friend void ecrit_a(int i); // Une fonction amie.
};
A essai;
void ecrit_a(int i)
{
essai.a=i; // Initialise a.
return;
}Il est possible de déclarer amie une fonction d'une autre classe, en précisant son nom complet à l'aide de l'opérateur de résolution de portée.
8.7.2. Classes amies▲
Pour rendre toutes les méthodes d'une classe amies d'une autre classe, il suffit de déclarer la classe complète comme étant amie. Pour cela, il faut encore une fois utiliser le mot clé friend avant la déclaration de la classe, à l'intérieur de la classe cible. Cette fois encore, la classe amie déclarée ne sera pas une sous-classe de la classe cible, mais bien une classe de portée globale.
Note : Le fait, pour une classe, d'appartenir à une autre classe lui donne le droit d'accéder aux membres de sa classe hôte. Il n'est donc pas nécessaire de déclarer amies d'une classe les classes définies au sein de celle-ci. Remarquez que cette règle a été récemment modifiée dans la norme C++, et que la plupart des compilateurs refuseront aux classes incluses d'accéder aux membres non publics de leur conteneur.
#include <stdio.h>
class Hote
{
friend class Amie; // Toutes les méthodes de Amie sont amies.
int i; // Donnée privée de la classe Hote.
public:
Hote(void)
{
i=0;
return ;
}
};
Hote h;
class Amie
{
public:
void print_hote(void)
{
printf("%d\n", h.i); // Accède à la donnée privée de h.
return ;
}
};
int main(void)
{
Amie a;
a.print_hote();
return 0;
}On remarquera plusieurs choses importantes. Premièrement, l'amitié n'est pas transitive. Cela signifie que les amis des amis ne sont pas des amis. Une classe A amie d'une classe B, elle-même amie d'une classe C, n'est pas amie de la classe C par défaut. Il faut la déclarer amie explicitement si on désire qu'elle le soit. Deuxièmement, les amis ne sont pas hérités. Ainsi, si une classe A est amie d'une classe B et que la classe C est une classe fille de la classe B, alors A n'est pas amie de la classe C par défaut. Encore une fois, il faut la déclarer amie explicitement. Ces remarques s'appliquent également aux fonctions amies (une fonction amie d'une classe A amie d'une classe B n'est pas amie de la classe B, ni des classes dérivées de A).
8.8. Constructeurs et destructeurs▲
Le constructeur et le destructeur sont deux méthodes particulières qui sont appelées respectivement à la création et à la destruction d'un objet. Toute classe a un constructeur et un destructeur par défaut, fournis par le compilateur. Ces constructeurs et destructeurs appellent les constructeurs par défaut et les destructeurs des classes de base et des données membres de la classe, mais en dehors de cela, ils ne font absolument rien. Il est donc souvent nécessaire de les redéfinir afin de gérer certaines actions qui doivent avoir lieu lors de la création d'un objet et de leur destruction. Par exemple, si l'objet doit contenir des variables allouées dynamiquement, il faut leur réserver de la mémoire à la création de l'objet ou au moins mettre les pointeurs correspondants à NULL. À la destruction de l'objet, il convient de restituer la mémoire allouée, s'il en a été alloué. On peut trouver bien d'autres situations où une phase d'initialisation et une phase de terminaison sont nécessaires.
Dès qu'un constructeur ou un destructeur a été défini par l'utilisateur, le compilateur ne définit plus automatiquement le constructeur ou le destructeur par défaut correspondant. En particulier, si l'utilisateur définit un constructeur prenant des paramètres, il ne sera plus possible de construire un objet simplement, sans fournir les paramètres à ce constructeur, à moins bien entendu de définir également un constructeur qui ne prenne pas de paramètres.
8.8.1. Définition des constructeurs et des destructeurs▲
Le constructeur se définit comme une méthode normale. Cependant, pour que le compilateur puisse la reconnaître en tant que constructeur, les deux conditions suivantes doivent être vérifiées :
- elle doit porter le même nom que la classe ;
- elle ne doit avoir aucun type, pas même le type void.
Le destructeur doit également respecter ces règles. Pour le différencier du constructeur, son nom sera toujours précédé du signe tilde ('~').
Un constructeur est appelé automatiquement lors de l'instanciation de l'objet. Le destructeur est appelé automatiquement lors de sa destruction. Cette destruction a lieu lors de la sortie du bloc de portée courante pour les objets de classe de stockage auto. Pour les objets alloués dynamiquement, le constructeur et le destructeur sont appelés automatiquement par les expressions qui utilisent les opérateurs new, new[], delete et delete[]. C'est pour cela qu'il est recommandé de les utiliser à la place des fonctions malloc et free du C pour créer dynamiquement des objets. De plus, il ne faut pas utiliser delete ou delete[] sur des pointeurs de type void, car il n'existe pas d'objets de type void. Le compilateur ne peut donc pas déterminer quel est le destructeur à appeler avec ce type de pointeur.
Le constructeur est appelé après l'allocation de la mémoire de l'objet et le destructeur est appelé avant la libération de cette mémoire. La gestion de l'allocation dynamique de mémoire avec les classes est ainsi simplifiée. Dans le cas des tableaux, l'ordre de construction est celui des adresses croissantes, et l'ordre de destruction est celui des adresses décroissantes. C'est dans cet ordre que les constructeurs et destructeurs de chaque élément du tableau sont appelés.
Les constructeurs pourront avoir des paramètres. Ils peuvent donc être surchargés, mais pas les destructeurs. Cela est dû a fait qu'en général on connaît le contexte dans lequel un objet est créé, mais qu'on ne peut pas connaître le contexte dans lequel il est détruit : il ne peut donc y avoir qu'un seul destructeur. Les constructeurs qui ne prennent pas de paramètre ou dont tous les paramètres ont une valeur par défaut, remplacent automatiquement les constructeurs par défaut définis par le compilateur lorsqu'il n'y a aucun constructeur dans les classes. Cela signifie que ce sont ces constructeurs qui seront appelés automatiquement par les constructeurs par défaut des classes dérivées.
class chaine // Implémente une chaîne de caractères.
{
char * s; // Le pointeur sur la chaîne de caractères.
public:
chaine(void); // Le constructeur par défaut.
chaine(unsigned int); // Le constructeur. Il n'a pas de type.
~chaine(void); // Le destructeur.
};
chaine::chaine(void)
{
s=NULL; // La chaîne est initialisée avec
return ; // le pointeur nul.
}
chaine::chaine(unsigned int Taille)
{
s = new char[Taille+1]; // Alloue de la mémoire pour la chaîne.
s[0]='\0'; // Initialise la chaîne à "".
return;
}
chaine::~chaine(void)
{
if (s!=NULL) delete[] s; // Restitue la mémoire utilisée si
// nécessaire.
return;
}Pour passer les paramètres au constructeur, on donne la liste des paramètres entre parenthèses juste après le nom de l'objet lors de son instanciation :
chaine s1; // Instancie une chaîne de caractères
// non initialisée.
chaine s2(200); // Instancie une chaîne de caractères
// de 200 caractères.Les constructeurs devront parfois effectuer des tâches plus compliquées que celles données dans cet exemple. En général, ils peuvent faire toutes les opérations faisables dans une méthode normale, sauf utiliser les données non initialisées bien entendu. En particulier, les données des sous-objets d'un objet ne sont pas initialisées tant que les constructeurs des classes de base ne sont pas appelés. C'est pour cela qu'il faut toujours appeler les constructeurs des classes de base avant d'exécuter le constructeur de la classe en cours d'instanciation. Si les constructeurs des classes de base ne sont pas appelés explicitement, le compilateur appellera, par défaut, les constructeurs des classes mères qui ne prennent pas de paramètre ou dont tous les paramètres ont une valeur par défaut (et, si aucun constructeur n'est défini dans les classe mères, il appellera les constructeurs par défaut de ces classes).
Comment appeler les constructeurs et les destructeurs des classes mères lors de l'instanciation et de la destruction d'une classe dérivée ? Le compilateur ne peut en effet pas savoir quel constructeur il faut appeler parmi les différents constructeurs surchargés potentiellement présents... Pour appeler un autre constructeur d'une classe de base que le constructeur ne prenant pas de paramètre, il faut spécifier explicitement ce constructeur avec ses paramètres après le nom du constructeur de la classe fille, en les séparant de deux points (':').
En revanche, il est inutile de préciser le destructeur à appeler, puisque celui-ci est unique. Le programmeur ne doit donc pas appeler lui-même les destructeurs des classes mères, le langage s'en charge.
/* Déclaration de la classe mère. */
class Mere
{
int m_i;
public:
Mere(int);
~Mere(void);
};
/* Définition du constructeur de la classe mère. */
Mere::Mere(int i)
{
m_i=i;
printf("Exécution du constructeur de la classe mère.\n");
return;
}
/* Définition du destructeur de la classe mère. */
Mere::~Mere(void)
{
printf("Exécution du destructeur de la classe mère.\n");
return;
}
/* Déclaration de la classe fille. */
class Fille : public Mere
{
public:
Fille(void);
~Fille(void);
};
/* Définition du constructeur de la classe fille
avec appel du constructeur de la classe mère. */
Fille::Fille(void) : Mere(2)
{
printf("Exécution du constructeur de la classe fille.\n");
return;
}
/* Définition du destructeur de la classe fille
avec appel automatique du destructeur de la classe mère. */
Fille::~Fille(void)
{
printf("Exécution du destructeur de la classe fille.\n");
return;
}Lors de l'instanciation d'un objet de la classe fille, le programme affichera dans l'ordre les messages suivants :
Exécution du constructeur de la classe mère.
Exécution du constructeur de la classe fille.et lors de la destruction de l'objet :
Exécution du destructeur de la classe fille.
Exécution du destructeur de la classe mère.Si l'on n'avait pas précisé que le constructeur à appeler pour la classe Mere était le constructeur prenant un entier en paramètre, le compilateur aurait essayé d'appeler le constructeur par défaut de cette classe. Or, ce constructeur n'étant plus généré automatiquement par le compilateur (à cause de la définition d'un constructeur prenant un paramètre), il y aurait eu une erreur de compilation.
Il est possible d'appeler plusieurs constructeurs si la classe dérive de plusieurs classes de base. Pour cela, il suffit de lister les constructeurs un à un, en séparant leurs appels par des virgules. On notera cependant que l'ordre dans lequel les constructeurs sont appelés n'est pas forcément l'ordre dans lequel ils sont listés dans la définition du constructeur de la classe fille. En effet, le C++ appelle toujours les constructeurs dans l'ordre d'apparition de leurs classes dans la liste des classes de base de la classe dérivée.
Note : Afin d'éviter l'utilisation des données non initialisées de l'objet le plus dérivé dans une hiérarchie pendant la construction de ses sous-objets par l'intermédiaire des fonctions virtuelles, le mécanisme des fonctions virtuelles est désactivé dans les constructeurs (voyez la Section 8.13 pour plus de détails sur les fonctions virtuelles). Ce problème survient parce que pendant l'exécution des constructeurs des classes de base, l'objet de la classe en cours d'instanciation n'a pas encore été initialisé, et malgré cela, une fonction virtuelle aurait pu utiliser une donnée de cet objet.
Une fonction virtuelle peut donc toujours être appelée dans un constructeur, mais la fonction effectivement appelée est celle de la classe du sous-objet en cours de construction : pas celle de la classe de l'objet complet. Ainsi, si une classe A hérite d'une classe B et qu'elles ont toutes les deux une fonction virtuelle f, l'appel de f dans le constructeur de B utilisera la fonction f de B, pas celle de A (même si l'objet que l'on instancie est de classe A).
La syntaxe utilisée pour appeler les constructeurs des classes de base peut également être utilisée pour initialiser les données membres de la classe. En particulier, cette syntaxe est obligatoire pour les données membres constantes et pour les références, car le C++ ne permet pas l'affectation d'une valeur à des variables de ce type. Encore une fois, l'ordre d'appel des constructeurs des données membres ainsi initialisées n'est pas forcément l'ordre dans lequel ils sont listés dans le constructeur de la classe. En effet, le C++ utilise cette fois l'ordre de déclaration de chaque donnée membre.
class tableau
{
const int m_iTailleMax;
const int *m_pDonnees;
public:
tableau(int iTailleMax);
~tableau();
};
tableau::tableau(int iTailleMax) :
m_iTailleMax(iTailleMax) // Initialise la donnée membre constante.
{
// Allocation d'un tableau de m_iTailleMax entrées :
m_pDonnees = new int[m_iTailleMax];
}
tableau::~tableau()
{
// Destruction des données :
delete[] m_pDonnees;
}Note : Les constructeurs des classes de base virtuelles prenant des paramètres doivent être appelés par chaque classe qui en dérive, que cette dérivation soit directe ou indirecte. En effet, les classes de base virtuelles subissent un traitement particulier qui assure l'unicité de leurs données dans toutes leurs classes dérivées. Les classes dérivées ne peuvent donc pas se reposer sur leurs classes de base pour appeler le constructeur des classes virtuelles, car il peut y avoir plusieurs classes de bases qui dérivent d'une même classe virtuelle, et cela supposerait que le constructeur de cette dernière classe serait appelé plusieurs fois, éventuellement avec des valeurs de paramètres différentes. Chaque classe doit donc prendre en charge la construction des sous-objets des classes de base virtuelles dont il hérite dans ce cas.
8.8.2. Constructeurs de copie▲
Il faudra parfois créer un constructeur de copie. Le but de ce type de constructeur est d'initialiser un objet lors de son instanciation à partir d'un autre objet. Toute classe dispose d'un constructeur de copie par défaut généré automatiquement par le compilateur, dont le seul but est de recopier les champs de l'objet à recopier un à un dans les champs de l'objet à instancier. Toutefois, ce constructeur par défaut ne suffira pas toujours, et le programmeur devra parfois en fournir un explicitement.
Ce sera notamment le cas lorsque certaines données des objets auront été allouées dynamiquement. Une copie brutale des champs d'un objet dans un autre ne ferait que recopier les pointeurs, pas les données pointées. Ainsi, la modification de ces données pour un objet entraînerait la modification des données de l'autre objet, ce qui ne serait sans doute pas l'effet désiré.
La définition des constructeurs de copie se fait comme celle des constructeurs normaux. Le nom doit être celui de la classe, et il ne doit y avoir aucun type. Dans la liste des paramètres cependant, il devra toujours y avoir une référence sur l'objet à copier.
Pour la classe chaine définie ci-dessus, il faut un constructeur de copie. Celui-ci peut être déclaré de la façon suivante :
chaine(const chaine &Source);où Source est l'objet à copier.
Si l'on rajoute la donnée membre Taille dans la déclaration de la classe, la définition de ce constructeur peut être :
chaine::chaine(const chaine &Source)
{
int i = 0; // Compteur de caractères.
Taille = Source.Taille;
s = new char[Taille + 1]; // Effectue l'allocation.
strcpy(s, Source.s); // Recopie la chaîne de caractères source.
return;
}Le constructeur de copie est appelé dans toute instanciation avec initialisation, comme celles qui suivent :
chaine s2(s1);
chaine s2 = s1;Dans les deux exemples, c'est le constructeur de copie qui est appelé. En particulier, à la deuxième ligne, le constructeur normal n'est pas appelé et aucune affectation entre objets n'a lieu.
Note : Le fait de définir un constructeur de copie pour une classe signifie généralement que le constructeur de copie, le destructeur et l'opérateur d'affectation fournis par défaut par le compilateur ne conviennent pas pour cette classe. Par conséquent, ces méthodes devront systématiquement être redéfinies toutes les trois dès que l'une d'entre elle le sera. Cette règle, que l'on appelle la règle des trois, vous permettra d'éviter des bogues facilement. Vous trouverez de plus amples détails sur la manière de redéfinir l'opérateur d'affectation dans la Section 8.11.3.
8.8.3. Utilisation des constructeurs dans les transtypages▲
Les constructeurs sont utilisés dans les conversions de type dans lesquelles le type cible est celui de la classe du constructeur. Ces conversions peuvent être soit implicites (dans une expression), soit explicite (à l'aide d'un transtypage). Par défaut, les conversions implicites sont légales, pourvu qu'il existe un constructeur dont le premier paramètre a le même type que l'objet source. Par exemple, la classe Entier suivante :
class Entier
{
int i;
public:
Entier(int j)
{
i=j;
return ;
}
};dispose d'un constructeur de transtypage pour les entiers. Les expressions suivantes :
int j=2;
Entier e1, e2=j;
e1=j;sont donc légales, la valeur entière située à la droite de l'expression étant convertie implicitement en un objet du type de la classe Entier.
Si, pour une raison quelconque, ce comportement n'est pas souhaitable, on peut forcer le compilateur à n'accepter que les conversions explicites (à l'aide de transtypage). Pour cela, il suffit de placer le mot clé explicit avant la déclaration du constructeur. Par exemple, le constructeur de la classe chaine vue ci-dessus prenant un entier en paramètre risque d'être utilisé dans des conversions implicites. Or ce constructeur ne permet pas de construire une chaîne de caractères à partir d'un entier, et ne doit donc pas être utilisé dans les opérations de transtypage. Ce constructeur doit donc être déclaré explicit :
class chaine
{
size_t Taille;
char * s;
public:
chaine(void);
// Ce constructeur permet de préciser la taille de la chaîne
// à sa création :
explicit chaine(unsigned int);
~chaine(void);
};Avec cette déclaration, l'expression suivante :
int j=2;
chaine s = j;n'est plus valide, alors qu'elle l'était lorsque le constructeur n'était pas déclaré explicit.
Note : On prendra garde au fait que le mot clé explicit n'empêche l'utilisation du constructeur dans les opérations de transtypage que dans les conversions implicites. Si le transtypage est explicitement demandé, le constructeur sera malgré tout utilisé. Ainsi, le code suivant sera accepté :
int j=2;
chaine s = (chaine) j;Bien entendu, cela n'a pas beaucoup de signification et ne devrait jamais être effectué.
8.9. Pointeur this▲
Nous allons à présent voir comment les fonctions membres, qui appartiennent à la classe, peuvent accéder aux données d'un objet, qui est une instance de cette classe. Cela est indispensable pour bien comprendre les paragraphes suivants.
À chaque appel d'une fonction membre, le compilateur passe implicitement un pointeur sur les données de l'objet en paramètre. Ce paramètre est le premier paramètre de la fonction. Ce mécanisme est complètement invisible au programmeur, et nous ne nous attarderons pas dessus.
En revanche, il faut savoir que le pointeur sur l'objet est accessible à l'intérieur de la fonction membre. Il porte le nom « this ». Par conséquent, *this représente l'objet lui-même. Nous verrons une utilisation de this dans le paragraphe suivant (surcharge des opérateurs).
this est un pointeur constant, c'est-à-dire qu'on ne peut pas le modifier (il est donc impossible de faire des opérations arithmétiques dessus). Cela est tout à fait normal, puisque le faire reviendrait à sortir de l'objet en cours (celui pour lequel la méthode en cours d'exécution travaille).
Il est possible de transformer ce pointeur constant en un pointeur constant sur des données constantes pour chaque fonction membre. Le pointeur ne peut toujours pas être modifié, et les données de l'objet ne peuvent pas être modifiées non plus. L'objet est donc considéré par la fonction membre concernée comme un objet constant. Cela revient à dire que la fonction membre s'interdit la modification des données de l'objet. On parvient à ce résultat en ajoutant le mot clé const à la suite de l'en-tête de la fonction membre. Par exemple :
class Entier
{
int i;
public:
int lit(void) const;
};
int Entier::lit(void) const
{
return i;
}Dans la fonction membre lit, il est impossible de modifier l'objet. On ne peut donc accéder qu'en lecture seule à i. Nous verrons une application de cette possibilité dans la Section 8.15.
Il est à noter qu'une méthode qui n'est pas déclarée comme étant const modifie a priori les données de l'objet sur lequel elle travaille. Donc, si elle est appelée sur un objet déclaré const, une erreur de compilation se produit. Ce comportement est normal. On devra donc toujours déclarer const une méthode qui ne modifie pas réellement l'objet, afin de laisser à l'utilisateur le choix de déclarer const ou non les objets de sa classe.
Note : Le mot clé const n'intervient pas dans la signature des fonctions en général lorsqu'il s'applique aux paramètres (tout paramètre déclaré const perd sa qualification dans la signature). En revanche, il intervient dans la signature d'une fonction membre quand il s'applique à cette fonction (ou, plus précisément, à l'objet pointé par this). Il est donc possible de déclarer deux fonctions membres acceptant les mêmes paramètres, dont une seule est const. Lors de l'appel, la détermination de la fonction à utiliser dépendra de la nature de l'objet sur lequel elle doit s'appliquer. Si l'objet est const, la méthode appelée sera celle qui est const.
8.10. Données et fonctions membres statiques▲
Nous allons voir dans ce paragraphe l'emploi du mot clé static dans les classes. Ce mot clé intervient pour caractériser les données membres statiques des classes, les fonctions membres statiques des classes, et les données statiques des fonctions membres.
8.10.1. Données membres statiques▲
Une classe peut contenir des données membres statiques. Ces données sont soit des données membres propres à la classe, soit des données locales statiques des fonctions membres de la classe. Dans tous les cas, elles appartiennent à la classe, et non pas aux objets de cette classe. Elles sont donc communes à tous ces objets.
Il est impossible d'initialiser les données d'une classe dans le constructeur de la classe, car le constructeur n'initialise que les données des nouveaux objets. Les données statiques ne sont pas spécifiques à un objet particulier et ne peuvent donc pas être initialisées dans le constructeur. En fait, leur initialisation doit se faire lors de leur définition, en dehors de la déclaration de la classe. Pour préciser la classe à laquelle les données ainsi définies appartiennent, on devra utiliser l'opérateur de résolution de portée (::).
class test
{
static int i; // Déclaration dans la classe.
...
};
int test::i=3; // Initialisation en dehors de la classe.La variable test::i sera partagée par tous les objets de classe test, et sa valeur initiale est 3.
Note : La définition des données membres statiques suit les mêmes règles que la définition des variables globales. Autrement dit, elles se comportent comme des variables déclarées externes. Elles sont donc accessibles dans tous les fichiers du programme (pourvu, bien entendu, qu'elles soient déclarées en zone publique dans la classe). De même, elles ne doivent être définies qu'une seule fois dans tout le programme. Il ne faut donc pas les définir dans un fichier d'en-tête qui peut être inclus plusieurs fois dans des fichiers sources, même si l'on protège ce fichier d'en-tête contre les inclusions multiples.
Les variables statiques des fonctions membres doivent être initialisées à l'intérieur des fonctions membres. Elles appartiennent également à la classe, et non pas aux objets. De plus, leur portée est réduite à celle du bloc dans lequel elles ont été déclarées. Ainsi, le code suivant :
#include <stdio.h>
class test
{
public:
int n(void);
};
int test::n(void)
{
static int compte=0;
return compte++;
}
int main(void)
{
test objet1, objet2;
printf("%d ", objet1.n()); // Affiche 0
printf("%d\n", objet2.n()); // Affiche 1
return 0;
}affichera 0 et 1, parce que la variable statique compte est la même pour les deux objets.
8.10.2. Fonctions membres statiques▲
Les classes peuvent également contenir des fonctions membres statiques. Cela peut surprendre à première vue, puisque les fonctions membres appartiennent déjà à la classe, c'est-à-dire à tous les objets. En fait, cela signifie que ces fonctions membres ne recevront pas le pointeur sur l'objet this, comme c'est le cas pour les autres fonctions membres. Par conséquent, elles ne pourront accéder qu'aux données statiques de l'objet.
class Entier
{
int i;
static int j;
public:
static int get_value(void);
};
int Entier::j=0;
int Entier::get_value(void)
{
j=1; // Légal.
return i; // ERREUR ! get_value ne peut pas accéder à i.
}La fonction get_value de l'exemple ci-dessus ne peut pas accéder à la donnée membre non statique i, parce qu'elle ne travaille sur aucun objet. Son champ d'action est uniquement la classe Entier. En revanche, elle peut modifier la variable statique j, puisque celle-ci appartient à la classe Entier et non aux objets de cette classe.
L'appel des fonctions membre statiques se fait exactement comme celui des fonctions membres non statiques, en spécifiant l'identificateur d'un des objets de la classe et le nom de la fonction membre, séparés par un point. Cependant, comme les fonctions membres ne travaillent pas sur les objets des classes mais plutôt sur les classes elles-mêmes, la présence de l'objet lors de l'appel est facultatif. On peut donc se contenter d'appeler une fonction statique en qualifiant son nom du nom de la classe à laquelle elle appartient à l'aide de l'opérateur de résolution de portée.
class Entier
{
static int i;
public:
static int get_value(void);
};
int Entier::i=3;
int Entier::get_value(void)
{
return i;
}
int main(void)
{
// Appelle la fonction statique get_value :
int resultat=Entier::get_value();
return 0;
}Les fonctions membres statiques sont souvent utilisées afin de regrouper un certain nombre de fonctionnalités en rapport avec leur classe. Ainsi, elles sont facilement localisable et les risques de conflits de noms entre deux fonctions membres homonymes sont réduits. Nous verrons également dans le Chapitre 11 comment éviter les conflits de noms globaux dans le cadre des espaces de nommage.
8.11. Surcharge des opérateurs▲
On a vu précédemment que les opérateurs ne se différencient des fonctions que syntaxiquement, pas logiquement. D'ailleurs, le compilateur traite un appel à un opérateur comme un appel à une fonction. Le C++ permet donc de surcharger les opérateurs pour les classes définies par l'utilisateur, en utilisant une syntaxe particulière calquée sur la syntaxe utilisée pour définir des fonctions membres normales. En fait, il est même possible de surcharger les opérateurs du langage pour les classes de l'utilisateur en dehors de la définition de ces classes. Le C++ dispose donc de deux méthodes différentes pour surcharger les opérateurs.
Les seuls opérateurs qui ne peuvent pas être surchargés sont les suivants :
::
.
.*
?:
sizeof
typeid
static_cast
dynamic_cast
const_cast
reinterpret_castTous les autres opérateurs sont surchargeables. Leur surcharge ne pose généralement pas de problème et peut être réalisée soit dans la classe des objets sur lesquels ils s'appliquent, soit à l'extérieur de cette classe. Cependant, un certain nombre d'entre eux demandent des explications complémentaires, que l'on donnera à la fin de cette section.
Note : On prendra garde aux problèmes de performances lors de la surcharge des opérateurs. Si la facilité d'écriture des expressions utilisant des classes est grandement simplifiée grâce à la possibilité de surcharger les opérateurs pour ces classes, les performances du programme peuvent en être gravement affectées. En effet, l'utilisation inconsidérée des opérateurs peut conduire à un grand nombre de copies des objets, copies que l'on pourrait éviter en écrivant le programme classiquement. Par exemple, la plupart des opérateurs renvoient un objet du type de la classe sur laquelle ils travaillent. Ces objets sont souvent créés localement dans la fonction de l'opérateur (c'est-à-dire qu'ils sont de portée auto). Par conséquent, ces objets sont temporaires et sont détruits à la sortie de la fonction de l'opérateur. Cela impose donc au compilateur d'en faire une copie dans la valeur de retour de la fonction avant d'en sortir. Cette copie sera elle-même détruite par le compilateur une fois qu'elle aura été utilisée par l'instruction qui a appelé la fonction. Si le résultat doit être affecté à un objet de l'appelant, une deuxième copie inutile est réalisée par rapport au cas où l'opérateur aurait travaillé directement dans la variable résultat. Si les bons compilateurs sont capables d'éviter ces copies, cela reste l'exception et il vaut mieux être averti à l'avance plutôt que de devoir réécrire tout son programme a posteriori pour des problèmes de performances.
Nous allons à présent voir dans les sections suivantes les deux syntaxes permettant de surcharger les opérateurs pour les types de l'utilisateur, ainsi que les règles spécifiques à certains opérateurs particuliers.
8.11.1. Surcharge des opérateurs internes▲
Une première méthode pour surcharger les opérateurs consiste à les considérer comme des méthodes normales de la classe sur laquelle ils s'appliquent. Le nom de ces méthodes est donné par le mot clé operator, suivi de l'opérateur à surcharger. Le type de la fonction de l'opérateur est le type du résultat donné par l'opération, et les paramètres, donnés entre parenthèses, sont les opérandes. Les opérateurs de ce type sont appelés opérateurs internes, parce qu'ils sont déclarés à l'intérieur de la classe.
Voici la syntaxe :
type operatorOp(paramètres)
l'écriture
A Op Bse traduisant par :
A.operatorOp(B)Avec cette syntaxe, le premier opérande est toujours l'objet auquel cette fonction s'applique. Cette manière de surcharger les opérateurs est donc particulièrement bien adaptée pour les opérateurs qui modifient l'objet sur lequel ils travaillent, comme par exemple les opérateurs =, +=, ++, etc. Les paramètres de la fonction opérateur sont alors le deuxième opérande et les suivants.
Les opérateurs définis en interne devront souvent renvoyer l'objet sur lequel ils travaillent (ce n'est pas une nécessité cependant). Cela est faisable grâce au pointeur this.
Par exemple, la classe suivante implémente les nombres complexes avec quelques-unes de leurs opérations de base.
class complexe
{
double m_x, m_y; // Les parties réelles et imaginaires.
public:
// Constructeurs et opérateur de copie :
complexe(double x=0, double y=0);
complexe(const complexe &);
complexe &operator=(const complexe &);
// Fonctions permettant de lire les parties réelles
// et imaginaires :
double re(void) const;
double im(void) const;
// Les opérateurs de base:
complexe &operator+=(const complexe &);
complexe &operator-=(const complexe &);
complexe &operator*=(const complexe &);
complexe &operator/=(const complexe &);
};
complexe::complexe(double x, double y)
{
m_x = x;
m_y = y;
return ;
}
complexe::complexe(const complexe &source)
{
m_x = source.m_x;
m_y = source.m_y;
return ;
}
complexe &complexe::operator=(const complexe &source)
{
m_x = source.m_x;
m_y = source.m_y;
return *this;
}
double complexe::re() const
{
return m_x;
}
double complexe::im() const
{
return m_y;
}
complexe &complexe::operator+=(const complexe &c)
{
m_x += c.m_x;
m_y += c.m_y;
return *this;
}
complexe &complexe::operator-=(const complexe &c)
{
m_x -= c.m_x;
m_y -= c.m_y;
return *this;
}
complexe &complexe::operator*=(const complexe &c)
{
double temp = m_x*c.m_x -m_y*c.m_y;
m_y = m_x*c.m_y + m_y*c.m_x;
m_x = temp;
return *this;
}
complexe &complexe::operator/=(const complexe &c)
{
double norm = c.m_x*c.m_x + c.m_y*c.m_y;
double temp = (m_x*c.m_x + m_y*c.m_y) / norm;
m_y = (-m_x*c.m_y + m_y*c.m_x) / norm;
m_x = temp;
return *this;
}Note : La bibliothèque standard C++ fournit une classe traitant les nombres complexes de manière complète, la classe complex. Cette classe n'est donc donnée ici qu'à titre d'exemple et ne devra évidemment pas être utilisée. La définition des nombres complexes et de leur principales propriétés sera donnée dans la Section 14.3.1, où la classe complex sera décrite.
Les opérateurs d'affectation fournissent un exemple d'utilisation du pointeur this. Ces opérateurs renvoient en effet systématiquement l'objet sur lequel ils travaillent, afin de permettre des affectations multiples. Les opérateurs de ce type devront donc tous se terminer par :
return *this;8.11.2. Surcharge des opérateurs externes▲
Une deuxième possibilité nous est offerte par le langage pour surcharger les opérateurs. La définition de l'opérateur ne se fait plus dans la classe qui l'utilise, mais en dehors de celle-ci, par surcharge d'un opérateur de l'espace de nommage global. Il s'agit donc d'opérateurs externes cette fois.
La surcharge des opérateurs externes se fait donc exactement comme on surcharge les fonctions normales. Dans ce cas, tous les opérandes de l'opérateur devront être passés en paramètres : il n'y aura pas de paramètre implicite (le pointeur this n'est pas passé en paramètre).
La syntaxe est la suivante :
type operatorOp(opérandes)où opérandes est la liste complète des opérandes.
L'avantage de cette syntaxe est que l'opérateur est réellement symétrique, contrairement à ce qui se passe pour les opérateurs définis à l'intérieur de la classe. Ainsi, si l'utilisation de cet opérateur nécessite un transtypage sur l'un des opérandes, il n'est pas nécessaire que cet opérande soit obligatoirement le deuxième. Donc si la classe dispose de constructeurs permettant de convertir un type de donnée en son prope type, ce type de donnée peut être utilisé avec tous les opérateurs de la classe.
Par exemple, les opérateurs d'addition, de soustraction, de multiplication et de division de la classe complexe peuvent être implémentés comme dans l'exemple suivant.
class complexe
{
friend complexe operator+(const complexe &, const complexe &);
friend complexe operator-(const complexe &, const complexe &);
friend complexe operator*(const complexe &, const complexe &);
friend complexe operator/(const complexe &, const complexe &);
double m_x, m_y; // Les parties réelles et imaginaires.
public:
// Constructeurs et opérateur de copie :
complexe(double x=0, double y=0);
complexe(const complexe &);
complexe &operator=(const complexe &);
// Fonctions permettant de lire les parties réelles
// et imaginaires :
double re(void) const;
double im(void) const;
// Les opérateurs de base:
complexe &operator+=(const complexe &);
complexe &operator-=(const complexe &);
complexe &operator*=(const complexe &);
complexe &operator/=(const complexe &);
};
// Les opérateurs de base ont été éludés ici :
...
complexe operator+(const complexe &c1, const complexe &c2)
{
complexe result = c1;
return result += c2;
}
complexe operator-(const complexe &c1, const complexe &c2)
{
complexe result = c1;
return result -= c2;
}
complexe operator*(const complexe &c1, const complexe &c2)
{
complexe result = c1;
return result *= c2;
}
complexe operator/(const complexe &c1, const complexe &c2)
{
complexe result = c1;
return result /= c2;
}Avec ces définitions, il est parfaitement possible d'effectuer la multiplication d'un objet de type complexe avec une valeur de type double. En effet, cette valeur sera automatiquement convertie en complexe grâce au constructeur de la classe complexe, qui sera utilisé ici comme constructeur de transtypage. Une fois cette conversion effectuée, l'opérateur adéquat est appliqué.
On constatera que les opérateurs externes doivent être déclarés comme étant des fonctions amies de la classe sur laquelle ils travaillent, faute de quoi ils ne pourraient pas manipuler les données membres de leurs opérandes.
Note : Certains compilateurs peuvent supprimer la création des variables temporaires lorsque celles-ci sont utilisées en tant que valeur de retour des fonctions. Cela permet d'améliorer grandement l'efficacité des programmes, en supprimant toutes les copies d'objets inutiles. Cependant ces compilateurs sont relativement rares et peuvent exiger une syntaxe particulière pour effectuer cette optimisation. Généralement, les compilateurs C++ actuels suppriment la création de variable temporaire dans les retours de fonctions si la valeur de retour est construite dans l'instruction return elle-même. Par exemple, l'opérateur d'addition peut être optimisé ainsi :
complexe operator+(const complexe &c1, const complexe &c2)
{
return complexe(c1.m_x + c2.m_x, c1.m_y + c2.m_y);
}Cette écriture n'est cependant pas toujours utilisable, et l'optimisation n'est pas garantie.
La syntaxe des opérateurs externes permet également d'implémenter les opérateurs pour lesquels le type de la valeur de retour est celui de l'opérande de gauche et que le type de cet opérande n'est pas une classe définie par l'utilisateur (par exemple si c'est un type prédéfini). En effet, on ne peut pas définir l'opérateur à l'intérieur de la classe du premier opérande dans ce cas, puisque cette classe est déjà définie. De même, cette syntaxe peut être utile dans le cas de l'écriture d'opérateurs optimisés pour certains types de données, pour lesquels les opérations réalisées par l'opérateur sont plus simples que celles qui auraient été effectuées après transtypage.
Par exemple, si l'on veut optimiser la multiplication à gauche par un scalaire pour la classe complexe, on devra procéder comme suit :
complexe operator*(double k, const complexe &c)
{
complexe result(c.re()*k,c.im()*k);
return result;
}ce qui permettra d'écrire des expressions du type :
complexe c1, c2;
double r;
...
c1 = r*c2;La première syntaxe n'aurait permis d'écrire un tel opérateur que pour la multiplication à droite par un double. En effet, pour écrire un opérateur interne permettant de réaliser cette optimisation, il aurait fallu surcharger l'opérateur de multiplication de la classe double pour lui faire accepter un objet de type complexe en second opérande...
8.11.3. Opérateurs d'affectation▲
Nous avons déjà vu un exemple d'opérateur d'affectation avec la classe complexe ci-dessus. Cet opérateur était très simple, mais ce n'est généralement pas toujours le cas, et l'implémentation des opérateurs d'affectation peut parfois soulever quelques problèmes.
Premièrement, comme nous l'avons dit dans la Section 8.8.2, le fait de définir un opérateur d'affectation signale souvent que la classe n'a pas une structure simple et que, par conséquent, le constructeur de copie et le destructeur fournis par défaut par le compilateur ne suffisent pas. Il faut donc veiller à respecter la règle des trois, qui stipule que si l'une de ces méthodes est redéfinie, il faut que les trois le soient. Par exemple, si vous ne redéfinissez pas le constructeur de copie, les écritures telles que :
classe object = source;ne fonctionneront pas correctement. En effet, c'est le constructeur de copie qui est appelé ici, et non l'opérateur d'affectation comme on pourrait le penser à première vue. De même, les traitements particuliers effectués lors de la copie ou de l'initialisation d'un objet devront être effectués en ordre inverse dans le destructeur de l'objet. Les traitements de destruction consistent généralement à libérer la mémoire et toutes les ressources allouées dynamiquement.
Lorsque l'on écrit un opérateur d'affectation, on a généralement à reproduire, à peu de choses près, le même code que celui qui se trouve dans le constructeur de copie. Il arrive même parfois que l'on doive libérer les ressources existantes avant de faire l'affectation, et donc le code de l'opérateur d'affectation ressemble souvent à la concaténation du code du destructeur et du code du constructeur de copie. Bien entendu, cette duplication de code est gênante et peu élégante. Une solution simple est d'implémenter une fonction de duplication et une fonction de libération des données. Ces deux fonctions, par exemple reset et clone, pourront être utilisées dans le destructeur, le constructeur de copie et l'opérateur d'affectation. Le programme devient ainsi beaucoup plus simple. Il ne faut généralement pas utiliser l'opérateur d'affectation dans le constructeur de copie, car cela peut poser des problèmes complexes à résoudre. Par exemple, il faut s'assurer que l'opérateur de copie ne cherche pas à utiliser des données membres non initialisées lors de son appel.
Un autre problème important est celui de l'autoaffectation. Non seulement affecter un objet à lui-même est inutile et consommateur de ressources, mais en plus cela peut être dangereux. En effet, l'affectation risque de détruire les données membres de l'objet avant même qu'elles ne soient copiées, ce qui provoquerait en fin de compte simplement la destruction de l'objet ! Une solution simple consiste ici à ajouter un test sur l'objet source en début d'opérateur, comme dans l'exemple suivant :
classe &classe::operator=(const classe &source)
{
if (&source != this)
{
// Traitement de copie des données :
...
}
return *this;
}Enfin, la copie des données peut lancer une exception et laisser l'objet sur lequel l'affectation se fait dans un état indéterminé. La solution la plus simple dans ce cas est encore de construire une copie de l'objet source en local, puis d'échanger le contenu des données de l'objet avec cette copie. Ainsi, si la copie échoue pour une raison ou une autre, l'objet source n'est pas modifié et reste dans un état stable. Le pseudo-code permettant de réaliser ceci est le suivant :
classe &classe::operator=(const classe &source)
{
// Construit une copie temporaire de la source :
class Temp(source);
// Échange le contenu de cette copie avec l'objet courant :
swap(Temp, *this);
// Renvoie l'objet courant (modifié) et détruit les données
// de la variable temporaire (contenant les anciennes données) :
return *this;
}Note : Le problème de l'état des objets n'est pas spécifique à l'opérateur d'affectation, mais à toutes les méthodes qui modifient l'objet, donc, en pratique, à toutes les méthodes non const. L'écriture de classes sûres au niveau de la gestion des erreurs est donc relativement difficile.
Vous trouverez de plus amples informations sur le mécanisme des exceptions en C++ dans le Chapitre 9.
8.11.4. Opérateurs de transtypage▲
Nous avons vu dans la Section 8.8.3 que les constructeurs peuvent être utilisés pour convertir des objets du type de leur paramètre vers le type de leur classe. Ces conversions peuvent avoir lieu de manière implicite ou non, selon que le mot clé explicit est appliqué au constructeur en question.
Cependant, il n'est pas toujours faisable d'écrire un tel constructeur. Par exemple, la classe cible peut parfaitement être une des classes de la bibliothèque standard, dont on ne doit évidemment pas modifier les fichiers source, ou même un des types de base du langage, pour lequel il n'y a pas de définition. Heureusement, les conversions peuvent malgré tout être réalisées dans ce cas, simplement en surchargeant les opérateurs de transtypage.
Prenons l'exemple de la classe chaine, qui permet de faire des chaînes de caractères dynamiques (de longueur variable). Il est possible de les convertir en chaîne C classiques (c'est-à-dire en tableau de caractères) si l'opérateur (char const *) a été surchargé :
chaine::operator char const *(void) const;On constatera que cet opérateur n'attend aucun paramètre, puisqu'il s'applique à l'objet qui l'appelle, mais surtout il n'a pas de type. En effet, puisque c'est un opérateur de transtypage, son type est nécessairement celui qui lui correspond (dans le cas présent, char const *).
Note : Si un constructeur de transtypage est également défini dans la classe du type cible de la conversion, il peut exister deux moyens de réaliser le transtypage. Dans ce cas, le compilateur choisira toujours le constructeur de transtypage de la classe cible à la place de l'opérateur de transtypage, sauf s'il est déclaré explicit. Ce mot clé peut donc être utilisé partout où l'on veut éviter que le compilateur n'utilise le constructeur de transtypage. Cependant, cette technique ne fonctionne qu'avec les conversions implicites réalisées par le compilateur. Si l'utilisateur effectue un transtypage explicite, ce sera à nouveau le constructeur qui sera appelé.
De plus, les conversions réalisées par l'intermédiaire d'un constructeur sont souvent plus performantes que celles réalisées par l'intermédiaire d'un opérateur de transtypage, en raison du fait que l'on évite ainsi la copie de la variable temporaire dans le retour de l'opérateur de transtypage. On évitera donc de définir les opérateurs de transtypage autant que faire se peut, et on écrira de préférence des constructeurs dans les classes des types cibles des conversions réalisées.
8.11.5. Opérateurs de comparaison▲
Les opérateurs de comparaison sont très simples à surcharger. La seule chose essentielle à retenir est qu'ils renvoient une valeur booléenne. Ainsi, pour la classe chaine, on peut déclarer les opérateurs d'égalité et d'infériorité (dans l'ordre lexicographique par exemple) de deux chaînes de caractères comme suit :
bool chaine::operator==(const chaine &) const;
bool chaine::operator<(const chaine &) const;8.11.6. Opérateurs d'incrémentation et de décrémentation▲
Les opérateurs d'incrémentation et de décrémentation sont tous les deux doubles, c'est-à-dire que la même notation représente deux opérateurs en réalité. En effet, ils n'ont pas la même signification, selon qu'ils sont placés avant ou après leur opérande. Le problème est que comme ces opérateurs ne prennent pas de paramètres (ils ne travaillent que sur l'objet), il est impossible de les différencier par surcharge. La solution qui a été adoptée est de les différencier en donnant un paramètre fictif de type int à l'un d'entre eux. Ainsi, les opérateurs ++ et -- ne prennent pas de paramètre lorsqu'il s'agit des opérateurs préfixés, et ont un argument fictif (que l'on ne doit pas utiliser) lorsqu'ils sont suffixés. Les versions préfixées des opérateurs doivent renvoyer une référence sur l'objet lui-même, les versions suffixées en revanche peuvent se contenter de renvoyer la valeur de l'objet.
class Entier
{
int i;
public:
Entier(int j)
{
i=j;
return;
}
Entier operator++(int) // Opérateur suffixe :
{ // retourne la valeur et incrémente
Entier tmp(i); // la variable.
++i;
return tmp;
}
Entier &operator++(void) // Opérateur préfixe : incrémente
{ // la variable et la retourne.
++i;
return *this;
}
};Note : Les opérateurs suffixés créant des objets temporaires, ils peuvent nuire gravement aux performances des programmes qui les utilisent de manière inconsidérée. Par conséquent, on ne les utilisera que lorsque cela est réellement nécessaire. En particulier, on évitera d'utiliser ces opérateurs dans toutes les opérations d'incrémentation des boucles d'itération.
8.11.7. Opérateur fonctionnel▲
L'opérateur d'appel de fonctions () peut également être surchargé. Cet opérateur permet de réaliser des objets qui se comportent comme des fonctions (ce que l'on appelle des foncteurs). La bibliothèque standard C++ en fait un usage intensif, comme nous pourrons le constater dans la deuxième partie de ce document.
L'opérateur fonctionnel est également très utile en raison de son n-arité (*, /, etc. sont des opérateurs binaires car ils ont deux opérandes, ?: est un opérateur ternaire car il a trois opérandes, () est n-aire car il peut avoir n opérandes). Il est donc utilisé couramment pour les classes de gestion de matrices de nombres, afin d'autoriser l'écriture « matrice(i,j,k) ».
class matrice
{
typedef double *ligne;
ligne *lignes;
unsigned short int n; // Nombre de lignes (1er paramètre).
unsigned short int m; // Nombre de colonnes (2ème paramètre).
public:
matrice(unsigned short int nl, unsigned short int nc);
matrice(const matrice &source);
~matrice(void);
matrice &operator=(const matrice &m1);
double &operator()(unsigned short int i, unsigned short int j);
double operator()(unsigned short int i, unsigned short int j) const;
};
// Le constructeur :
matrice::matrice(unsigned short int nl, unsigned short int nc)
{
n = nl;
m = nc;
lignes = new ligne[n];
for (unsigned short int i=0; i<n; ++i)
lignes[i] = new double[m];
return;
}
// Le constructeur de copie :
matrice::matrice(const matrice &source)
{
m = source.m;
n = source.n;
lignes = new ligne[n]; // Alloue.
for (unsigned short int i=0; i<n; ++i)
{
lignes[i] = new double[m];
for (unsigned short int j=0; j<m; ++j) // Copie.
lignes[i][j] = source.lignes[i][j];
}
return;
}
// Le destructeur :
matrice::~matrice(void)
{
for (unsigned short int i=0; i<n; ++i)
delete[] lignes[i];
delete[] lignes;
return;
}
// L'opérateur d'affectation :
matrice &matrice::operator=(const matrice &source)
{
if (&source != this)
{
if (source.n!=n || source.m!=m) // Vérifie les dimensions.
{
for (unsigned short int i=0; i<n; ++i)
delete[] lignes[i];
delete[] lignes; // Détruit...
m = source.m;
n = source.n;
lignes = new ligne[n]; // et réalloue.
for (i=0; i<n; ++i) lignes[i] = new double[m];
}
for (unsigned short int i=0; i<n; ++i) // Copie.
for (unsigned short int j=0; j<m; ++j)
lignes[i][j] = source.lignes[i][j];
}
return *this;
}
// Opérateurs d'accès :
double &matrice::operator()(unsigned short int i,
unsigned short int j)
{
return lignes[i][j];
}
double matrice::operator()(unsigned short int i,
unsigned short int j) const
{
return lignes[i][j];
}Ainsi, on pourra effectuer la déclaration d'une matrice avec :
matrice m(2,3);et accéder à ses éléments simplement avec :
m(i,j)=6;On remarquera que l'on a défini deux opérateurs fonctionnels dans l'exemple donné ci-dessus. Le premier renvoie une référence et permet de modifier la valeur d'un des éléments de la matrice. Cet opérateur ne peut bien entendu pas s'appliquer à une matrice constante, même simplement pour lire un élément. C'est donc le deuxième opérateur qui sera utilisé pour lire les éléments des matrices constantes, car il renvoie une valeur et non plus une référence. Le choix de l'opérateur à utiliser est déterminé par la présence du mot clé const, qui indique que seul cet opérateur peut être utilisé pour une matrice constante.
Note : Les opérations de base sur les matrices (addition, soustraction, inversion, transposition, etc.) n'ont pas été reportées ici par souci de clarté. La manière de définir ces opérateurs a été présentée dans les sections précédentes.
8.11.8. Opérateurs d'indirection et de déréférencement▲
L'opérateur de déréférencement * permet l'écriture de classes dont les objets peuvent être utilisés dans des expressions manipulant des pointeurs. L'opérateur d'indirection & quant à lui, permet de renvoyer une adresse autre que celle de l'objet sur lequel il s'applique. Enfin, l'opérateur de déréférencement et de sélection de membres de structures -> permet de réaliser des classes qui encapsulent d'autres classes.
Si les opérateurs de déréférencement et d'indirection & et * peuvent renvoyer une valeur de type quelconque, ce n'est pas le cas de l'opérateur de déréférencement et de sélection de membre ->. Cet opérateur doit nécessairement renvoyer un type pour lequel il doit encore être applicable. Ce type doit donc soit surcharger l'opérateur ->, soit être un pointeur sur une structure, union ou classe.
// Cette classe est encapsulée par une autre classe :
struct Encapsulee
{
int i; // Donnée à accéder.
};
Encapsulee o; // Objet à manipuler.
// Cette classe est la classe encapsulante :
struct Encapsulante
{
Encapsulee *operator->(void) const
{
return &o;
}
Encapsulee *operator&(void) const
{
return &o;
}
Encapsulee &operator*(void) const
{
return o;
}
};
// Exemple d'utilisation :
void f(int i)
{
Encapsulante e;
e->i=2; // Enregistre 2 dans o.i.
(*e).i = 3; // Enregistre 3 dans o.i.
Encapsulee *p = &e;
p->i = 4; // Enregistre 4 dans o.i.
return ;
}8.11.9. Opérateurs d'allocation dynamique de mémoire▲
Les opérateurs les plus difficiles à écrire sont sans doute les opérateurs d'allocation dynamique de mémoire. Ces opérateurs prennent un nombre variable de paramètres, parce qu'ils sont complètement surchargeables (c'est à dire qu'il est possible de définir plusieurs surcharges de ces opérateurs même au sein d'une même classe, s'ils sont définis de manière interne). Il est donc possible de définir plusieurs opérateurs new ou new[], et plusieurs opérateurs delete ou delete[]. Cependant, les premiers paramètres de ces opérateurs doivent toujours être la taille de la zone de la mémoire à allouer dans le cas des opérateurs new et new[], et le pointeur sur la zone de la mémoire à restituer dans le cas des opérateurs delete et delete[].
La forme la plus simple de new ne prend qu'un paramètre : le nombre d'octets à allouer, qui vaut toujours la taille de l'objet à construire. Il doit renvoyer un pointeur du type void. L'opérateur delete correspondant peut prendre, quant à lui, soit un, soit deux paramètres. Comme on l'a déjà dit, le premier paramètre est toujours un pointeur du type void sur l'objet à détruire. Le deuxième paramètre, s'il existe, est du type size_t et contient la taille de l'objet à détruire. Les mêmes règles s'appliquent pour les opérateurs new[] et delete[], utilisés pour les tableaux.
Lorsque les opérateurs delete et delete[] prennent deux paramètres, le deuxième paramètre est la taille de la zone de la mémoire à restituer. Cela signifie que le compilateur se charge de mémoriser cette information. Pour les opérateurs new et delete, cela ne cause pas de problème, puisque la taille de cette zone est fixée par le type de l'objet. En revanche, pour les tableaux, la taille du tableau doit être stockée avec le tableau. En général, le compilateur utilise un en-tête devant le tableau d'objets. C'est pour cela que la taille à allouer passée à new[], qui est la même que la taille à désallouer passée en paramètre à delete[], n'est pas égale à la taille d'un objet multipliée par le nombre d'objets du tableau. Le compilateur demande un peu plus de mémoire, pour mémoriser la taille du tableau. On ne peut donc pas, dans ce cas, faire d'hypothèses quant à la structure que le compilateur donnera à la mémoire allouée pour stocker le tableau.
En revanche, si delete[] ne prend en paramètre que le pointeur sur le tableau, la mémorisation de la taille du tableau est à la charge du programmeur. Dans ce cas, le compilateur donne à new[] la valeur exacte de la taille du tableau, à savoir la taille d'un objet multipliée par le nombre d'objets dans le tableau.
#include <stdio.h>
int buffer[256]; // Buffer servant à stocker le tableau.
class Temp
{
char i[13]; // sizeof(Temp) doit être premier.
public:
static void *operator new[](size_t taille)
{
return buffer;
}
static void operator delete[](void *p, size_t taille)
{
printf("Taille de l'en-tête : %d\n",
taille-(taille/sizeof(Temp))*sizeof(Temp));
return ;
}
};
int main(void)
{
delete[] new Temp[1];
return 0;
}Il est à noter qu'aucun des opérateurs new, delete, new[] et delete[] ne reçoit le pointeur this en paramètre : ce sont des opérateurs statiques. Cela est normal puisque, lorsqu'ils s'exécutent, soit l'objet n'est pas encore créé, soit il est déjà détruit. Le pointeur this n'existe donc pas encore (ou n'est plus valide) lors de l'appel de ces opérateurs.
Les opérateurs new et new[] peuvent avoir une forme encore un peu plus compliquée, qui permet de leur passer des paramètres lors de l'allocation de la mémoire. Les paramètres supplémentaires doivent impérativement être les paramètres deux et suivants, puisque le premier paramètre indique toujours la taille de la zone de mémoire à allouer.
Comme le premier paramètre est calculé par le compilateur, il n'y a pas de syntaxe permettant de le passer aux opérateurs new et new[]. En revanche, une syntaxe spéciale est nécessaire pour passer les paramètres supplémentaires. Cette syntaxe est détaillée ci-dessous.
Si l'opérateur new est déclaré de la manière suivante dans la classe classe :
static void *operator new(size_t taille, paramètres);
où taille est la taille de la zone de mémoire à allouer et paramètres la liste des paramètres additionnels, alors on doit l'appeler avec la syntaxe suivante :
new(paramètres) classe;Les paramètres sont donc passés entre parenthèses comme pour une fonction normale. Le nom de la fonction est new, et le nom de la classe suit l'expression new comme dans la syntaxe sans paramètres. Cette utilisation de new est appelée new avec placement.
Le placement est souvent utilisé afin de réaliser des réallocations de mémoire d'un objet à un autre. Par exemple, si l'on doit détruire un objet alloué dynamiquement et en reconstruire immédiatement un autre du même type, les opérations suivantes se déroulent :
- appel du destructeur de l'objet (réalisé par l'expression delete) ;
- appel de l'opérateur delete ;
- appel de l'opérateur new ;
- appel du constructeur du nouvel objet (réalisé par l'expression new).
Cela n'est pas très efficace, puisque la mémoire est restituée pour être allouée de nouveau immédiatement après. Il est beaucoup plus logique de réutiliser la mémoire de l'objet à détruire pour le nouvel objet, et de reconstruire ce dernier dans cette mémoire. Cela peut se faire comme suit :
- appel explicite du destructeur de l'objet à détruire ;
- appel de new avec comme paramètre supplémentaire le pointeur sur l'objet détruit ;
- appel du constructeur du deuxième objet (réalisé par l'expression new).
L'appel de new ne fait alors aucune allocation : on gagne ainsi beaucoup de temps.
#include <stdlib.h>
class A
{
public:
A(void) // Constructeur.
{
return ;
}
~A(void) // Destructeur.
{
return ;
}
// L'opérateur new suivant utilise le placement.
// Il reçoit en paramètre le pointeur sur le bloc
// à utiliser pour la requête d'allocation dynamique
// de mémoire.
static void *operator new (size_t taille, A *bloc)
{
return (void *) bloc;
}
// Opérateur new normal :
static void *operator new(size_t taille)
{
// Implémentation :
return malloc(taille);
}
// Opérateur delete normal :
static void operator delete(void *pBlock)
{
free(pBlock);
return ;
}
};
int main(void)
{
A *pA=new A; // Création d'un objet de classe A.
// L'opérateur new global du C++ est utilisé.
pA->~A(); // Appel explicite du destructeur de A.
A *pB=new(pA) A; // Réutilisation de la mémoire de A.
delete pB; // Destruction de l'objet.
return 0;
}Dans cet exemple, la gestion de la mémoire est réalisée par les opérateurs new et delete normaux. Cependant, la réutilisation de la mémoire allouée se fait grâce à un opérateur new avec placement, défini pour l'occasion. Ce dernier ne fait strictement rien d'autre que de renvoyer le pointeur qu'on lui a passé en paramètre. On notera qu'il est nécessaire d'appeler explicitement le destructeur de la classe A avant de réutiliser la mémoire de l'objet, car aucune expression delete ne s'en charge avant la réutilisation de la mémoire.
Note : Les opérateurs new et delete avec placement prédéfinis par la bibliothèque standard C++ effectuent exactement ce que les opérateurs de cet exemple font. Il n'est donc pas nécessaire de les définir, si on ne fait aucun autre traitement que de réutiliser le bloc mémoire que l'opérateur new reçoit en paramètre.
Il est impossible de passer des paramètres à l'opérateur delete dans une expression delete. Cela est dû au fait qu'en général on ne connaît pas le contexte de la destruction d'un objet (alors qu'à l'allocation, on connaît le contexte de création de l'objet). Normalement, il ne peut donc y avoir qu'un seul opérateur delete. Cependant, il existe un cas où l'on connaît le contexte de l'appel de l'opérateur delete : c'est le cas où le constructeur de la classe lance une exception (voir le Chapitre 9 pour plus de détails à ce sujet). Dans ce cas, la mémoire allouée par l'opérateur new doit être restituée et l'opérateur delete est automatiquement appelé, puisque l'objet n'a pas pu être construit. Afin d'obtenir un comportement symétrique, il est permis de donner des paramètres additionnels à l'opérateur delete. Lorsqu'une exception est lancée dans le constructeur de l'objet alloué, l'opérateur delete appelé est l'opérateur dont la liste des paramètres correspond à celle de l'opérateur new qui a été utilisé pour créer l'objet. Les paramètres passés à l'opérateur delete prennent alors exactement les mêmes valeurs que celles qui ont été données aux paramètres de l'opérateur new lors de l'allocation de la mémoire de l'objet. Ainsi, si l'opérateur new a été utilisé sans placement, l'opérateur delete sans placement sera appelé. En revanche, si l'opérateur new a été appelé avec des paramètres, l'opérateur delete qui a les mêmes paramètres sera appelé. Si aucun opérateur delete ne correspond, aucun opérateur delete n'est appelé (si l'opérateur new n'a pas alloué de mémoire, cela n'est pas grave, en revanche, si de la mémoire a été allouée, elle ne sera pas restituée). Il est donc important de définir un opérateur delete avec placement pour chaque opérateur new avec placement défini. L'exemple précédent doit donc être réécrit de la manière suivante :
#include <stdlib.h>
static bool bThrow = false;
class A
{
public:
A(void) // Constructeur.
{
// Le constructeur est susceptible
// de lancer une exception :
if (bThrow) throw 2;
return ;
}
~A(void) // Destructeur.
{
return ;
}
// L'opérateur new suivant utilise le placement.
// Il reçoit en paramètre le pointeur sur le bloc
// à utiliser pour la requête d'allocation dynamique
// de mémoire.
static void *operator new (size_t taille, A *bloc)
{
return (void *) bloc;
}
// L'opérateur delete suivant est utilisé dans les expressions
// qui utilisent l'opérateur new avec placement ci-dessus,
// si une exception se produit dans le constructeur.
static void operator delete(void *p, A *bloc)
{
// On ne fait rien, parce que l'opérateur new correspondant
// n'a pas alloué de mémoire.
return ;
}
// Opérateur new et delete normaux :
static void *operator new(size_t taille)
{
return malloc(taille);
}
static void operator delete(void *pBlock)
{
free(pBlock);
return ;
}
};
int main(void)
{
A *pA=new A; // Création d'un objet de classe A.
pA->~A(); // Appel explicite du destructeur de A.
bThrow = true; // Maintenant, le constructeur de A lance
// une exception.
try
{
A *pB=new(pA) A; // Réutilisation de la mémoire de A.
// Si une exception a lieu, l'opérateur
// delete(void *, A *) avec placement
// est utilisé.
delete pB; // Destruction de l'objet.
}
catch (...)
{
// L'opérateur delete(void *, A *) ne libère pas la mémoire
// allouée lors du premier new. Il faut donc quand même
// le faire, mais sans delete, car l'objet pointé par pA
// est déjà détruit, et celui pointé par pB l'a été par
// l'opérateur delete(void *, A *) :
free(pA);
}
return 0;
}Note : Il est possible d'utiliser le placement avec les opérateurs new[] et delete[] exactement de la même manière qu'avec les opérateurs new et delete.
On notera que lorsque l'opérateur new est utilisé avec placement, si le deuxième argument est de type size_t, l'opérateur delete à deux arguments peut être interprété soit comme un opérateur delete classique sans placement mais avec deux paramètres, soit comme l'opérateur delete avec placement correspondant à l'opérateur new avec placement. Afin de résoudre cette ambiguïté, le compilateur interprète systématiquement l'opérateur delete avec un deuxième paramètre de type size_t comme étant l'opérateur à deux paramètres sans placement. Il est donc impossible de définir un opérateur delete avec placement s'il a deux paramètres, le deuxième étant de type size_t. Il en est de même avec les opérateurs new[] et delete[].
Quelle que soit la syntaxe que vous désirez utiliser, les opérateurs new, new[], delete et delete[] doivent avoir un comportement bien déterminé. En particulier, les opérateurs delete et delete[] doivent pouvoir accepter un pointeur nul en paramètre. Lorsqu'un tel pointeur est utilisé dans une expression delete, aucun traitement ne doit être fait.
Enfin, vos opérateurs new et new[] doivent, en cas de manque de mémoire, appeler un gestionnaire d'erreur. Le gestionnaire d'erreur fourni par défaut lance une exception de classe std::bad_alloc (voir le Chapitre 9 pour plus de détails sur les exceptions). Cette classe est définie comme suit dans le fichier d'en-tête new :
class bad_alloc : public exception
{
public:
bad_alloc(void) throw();
bad_alloc(const bad_alloc &) throw();
bad_alloc &operator=(const bad_alloc &) throw();
virtual ~bad_alloc(void) throw();
virtual const char *what(void) const throw();
};Note : Comme son nom l'indique, cette classe est définie dans l'espace de nommage std::. Si vous ne voulez pas utiliser les notions des espaces de nommage, vous devrez inclure le fichier d'en-tête new.h au lieu de new. Vous obtiendrez de plus amples renseignements sur les espaces de nommage dans le Chapitre 11.
La classe exception dont bad_alloc hérite est déclarée comme suit dans le fichier d'en-tête exception :
class exception
{
public:
exception (void) throw();
exception(const exception &) throw();
exception &operator=(const exception &) throw();
virtual ~exception(void) throw();
virtual const char *what(void) const throw();
};Note : Vous trouverez plus d'informations sur les exceptions dans le Chapitre 9.
Si vous désirez remplacer le gestionnaire par défaut, vous pouvez utiliser la fonction std::set_new_handler. Cette fonction attend en paramètre le pointeur sur le gestionnaire d'erreur à installer et renvoie le pointeur sur le gestionnaire d'erreur précédemment installé. Les gestionnaires d'erreurs ne prennent aucun paramètre et ne renvoient aucune valeur.
- soit ils prennent les mesures nécessaires pour permettre l'allocation du bloc de mémoire demandé et rendent la main à l'opérateur new. Ce dernier refait alors une tentative pour allouer le bloc de mémoire. Si cette tentative échoue à nouveau, le gestionnaire d'erreur est rappelé. Cette boucle se poursuit jusqu'à ce que l'opération se déroule correctement ou qu'une exception std::bad_alloc soit lancée ;
- soit ils lancent une exception de classe std::bad_alloc ;
- soit ils terminent l'exécution du programme en cours.
La bibliothèque standard définit une version avec placement des opérateurs new et new[], qui renvoient le pointeur nul au lieu de lancer une exception en cas de manque de mémoire. Ces opérateurs prennent un deuxième paramètre, de type std::nothrow_t, qui doit être spécifié lors de l'appel. La bibliothèque standard définit un objet constant de ce type afin que les programmes puissent l'utiliser sans avoir à le définir eux-même. Cet objet se nomme std::nothrow
char *data = new(std::nothrow) char[25];
if (data == NULL)
{
// Traitement de l'erreur...
⋮
}Note : La plupart des compilateurs ne respectent pas les règles dictées par la norme C++. En effet, ils préfèrent retourner la valeur nulle en cas de manque de mémoire au lieu de lancer une exception. On peut rendre ces implémentations compatibles avec la norme en installant un gestionnaire d'erreur qui lance lui-même l'exception std::bad_alloc.
8.12. Des entrées - sorties simplifiées▲
Les flux d'entrée / sortie de la bibliothèque standard C++ constituent sans doute l'une des applications les plus intéressantes de la surcharge des opérateurs. Comme nous allons le voir, la surcharge des opérateurs << et >> permet d'écrire et de lire sur ces flux de manière très intuitive.
En effet, la bibliothèque standard C++ définit dans l'en-tête iostream des classes extrêmement puissantes permettant de manipuler les flux d'entrée / sortie. Ces classes réalisent en particulier les opérations d'entrée / sortie de et vers les périphériques d'entrée et les périphériques de sortie standards (généralement, le clavier et l'écran), mais elles ne s'arrêtent pas là : elles permettent également de travailler sur des fichiers ou encore sur des tampons en mémoire.
Les classes d'entrée / sortie de la bibliothèque standard C++ permettent donc d'effectuer les mêmes opérations que les fonctions printf et scanf de la bibliothèque C standard. Cependant, grâce au mécanisme de surcharge des opérateurs, elles sont beaucoup plus faciles d'utilisation. En effet, les opérateurs << et >> de ces classes ont été surchargés pour chaque type de donnée du langage, permettant ainsi de réaliser des entrées / sorties typées extrêmement facilement. L'opérateur <<, également appelée opérateur d'insertion, sera utilisé pour réaliser des écritures sur un flux de données, tandis que l'opérateur >>, ou opérateur d'extraction, permettra de réaliser la lecture d'une nouvelle donnée dans le flux d'entrée. Ces deux opérateurs renvoient tous les deux le flux de données utilisé, ce qui permet de réaliser plusieurs opérations d'entrée / sortie successivement sur le même flux.
Note : Cette section n'a pas pour but de décrire en détail les flux d'entrée / sortie de la bibliothèque standard C++, mais plutôt d'en faire une présentation simple permettant de les utiliser sans avoir à se plonger prématurément dans des notions extrêmement évoluées. Vous trouverez une description exhaustive des mécanismes des flux d'entrée / sortie de la bibliothèque standard C++ dans le Chapitre 15.
La bibliothèque standard définit quatre instances particulières de ses classes d'entrée / sortie : cin, cout, cerr et clog. Ces objets sont des instances des classes istream et ostream, prenant respectivement en charge l'entrée et la sortie des données des programmes. L'objet cin correspond au flux d'entrée standard stdin du programme, et l'objet cout aux flux de sortie standard stdout. Enfin, les objets cerr et clog sont associés au flux d'erreurs standard stderr. Théoriquement, cerr doit être utilisé pour l'écriture des messages d'erreur des programmes, et clog pour les messages d'information. Cependant, en pratique, les données écrites sur ces deux flux sont écrites dans le même flux, et l'emploi de l'objet clog est assez rare.
L'utilisation des opérateurs d'insertion et d'extraction sur ces flux se résume donc à la syntaxe suivante :
cin >> variable [>> variable [...]];
cout << valeur [<< valeur [...]];Comme on le voit, il est possible d'effectuer plusieurs entrées ou plusieurs sortie successivement sur un même flux.
De plus, la bibliothèque standard définie ce que l'on appelle des manipulateurs permettant de réaliser des opérations simples sur les flux d'entrée / sortie. Le manipulateur le plus utilisé est sans nul doute le manipulateur endl qui, comme son nom l'indique, permet de signaler une fin de ligne et d'effectuer un saut de ligne lorsqu'il est employé sur un flux de sortie.
#include <iostream>
using namespace std;
int main(void)
{
int i;
// Lit un entier :
cin >> i;
// Affiche cet entier et le suivant :
cout << i << " " << i+1 << endl;
return 0;
}Note : Comme on le verra dans le Chapitre 15, les manipulateurs sont en réalité des fonctions pour le type desquelles un opérateur << ou un opérateur >> a été défini dans les classes d'entrée / sortie. Ces opérateurs appellent ces fonctions, qui effectuent chacune des modifications spécifiques sur le flux sur lequel elles travaillent.
Les flux d'entrée / sortie cin, cout cerr et clog sont déclarés dans l'espace de nommage std:: de la bibliothèque standard C++. On devra donc faire précéder leur nom du préfixe std:: pour y accéder, ou utiliser un directive using pour importer les symboles de la bibliothèque standard C++ dans l'espace de nommage global. Vous trouverez de plus amples renseignements sur les espaces de nommages dans le Chapitre 11.
- le type des donnée est automatiquement pris en compte par les opérateurs d'insertion et d'extraction (ils sont surchargés pour tous les types prédéfinis) ;
- les opérateurs d'extraction travaillent par référence (on ne risque plus d'omettre l'opérateur & dans la fonction scanf) ;
- il est possible de définir des opérateurs d'insertion et d'extraction pour d'autres types de données que les types de base du langage ;
- leur utilisation est globalement plus simple.
Les flux d'entrée / sortie définis par la bibliothèque C++ sont donc d'une extrême souplesse et sont extensibles aux types de données utilisateur. Par ailleurs, ils disposent d'un grand nombre de paramètres de formatage et d'options avancées. Toutes ces fonctionnalités seront décrites dans le Chapitre 15, où nous verrons également comment réaliser des entrées / sorties dans des fichiers.
8.13. Méthodes virtuelles▲
Les méthodes virtuelles n'ont strictement rien à voir avec les classes virtuelles, bien qu'elles utilisent le même mot clé virtual. Ce mot clé est utilisé ici dans un contexte et dans un sens différent.
Nous savons qu'il est possible de redéfinir les méthodes d'une classe mère dans une classe fille. Lors de l'appel d'une fonction ainsi redéfinie, la fonction appelée est la dernière fonction définie dans la hiérarchie de classe. Pour appeler la fonction de la classe mère alors qu'elle a été redéfinie, il faut préciser le nom de la classe à laquelle elle appartient avec l'opérateur de résolution de portée (::).
Bien que simple, cette utilisation de la redéfinition des méthodes peut poser des problèmes. Supposons qu'une classe B hérite de sa classe mère A. Si A possède une méthode x appelant une autre méthode y redéfinie dans la classe fille B, que se passe-t-il lorsqu'un objet de classe B appelle la méthode x ? La méthode appelée étant celle de la classe A, elle appellera la méthode y de la classe A. Par conséquent, la redéfinition de y ne sert à rien dès qu'on l'appelle à partir d'une des fonctions d'une des classes mères.
Une première solution consisterait à redéfinir la méthode x dans la classe B. Mais ce n'est ni élégant, ni efficace. Il faut en fait forcer le compilateur à ne pas faire le lien dans la fonction x de la classe A avec la fonction y de la classe A. Il faut que x appelle soit la fonction y de la classe A si elle est appelée par un objet de la classe A, soit la fonction y de la classe B si elle est appelée pour un objet de la classe B. Le lien avec l'une des méthodes y ne doit être fait qu'au moment de l'exécution, c'est-à-dire qu'on doit faire une édition de liens dynamique.
Le C++ permet de faire cela. Pour cela, il suffit de déclarer virtuelle la fonction de la classe de base qui est redéfinie dans la classe fille, c'est-à-dire la fonction y. Cela se fait en faisant précéder par le mot clé virtual dans la classe de base.
#include <iostream>
using namespace std;
// Définit la classe de base des données.
class DonneeBase
{
protected:
int Numero; // Les données sont numérotées.
int Valeur; // et sont constituées d'une valeur entière
// pour les données de base.
public:
void Entre(void); // Entre une donnée.
void MiseAJour(void); // Met à jour la donnée.
};
void DonneeBase::Entre(void)
{
cin >> Numero; // Entre le numéro de la donnée.
cout << endl;
cin >> Valeur; // Entre sa valeur.
cout << endl;
return;
}
void DonneeBase::MiseAJour(void)
{
Entre(); // Entre une nouvelle donnée
// à la place de la donnée en cours.
return;
}
/* Définit la classe des données détaillées. */
class DonneeDetaillee : private DonneeBase
{
int ValeurEtendue; // Les données détaillées ont en plus
// une valeur étendue.
public:
void Entre(void); // Redéfinition de la méthode d'entrée.
};
void DonneeDetaillee::Entre(void)
{
DonneeBase::Entre(); // Appelle la méthode de base.
cin >> ValeurEtendue; // Entre la valeur étendue.
cout << endl;
return;
}Si d est un objet de la classe DonneeDetaillee, l'appel de d.Entre ne causera pas de problème. En revanche, l'appel de d.MiseAJour ne fonctionnera pas correctement, car la fonction Entre appelée dans MiseAJour est la fonction de la classe DonneeBase, et non la fonction redéfinie dans DonneeDetaille.
Il fallait déclarer la fonction Entre comme une fonction virtuelle. Il n'est nécessaire de le faire que dans la classe de base. Celle-ci doit donc être déclarée comme suit :
class DonneeBase
{
protected:
int Numero;
int Valeur;
public:
virtual void Entre(void); // Fonction virtuelle.
void MiseAJour(void);
};Cette fois, la fonction Entre appelée dans MiseAJour est soit la fonction de la classe DonneeBase, si MiseAJour est appelée pour un objet de classe DonneeBase, soit celle de la classe DonneeDetaille si MiseAJour est appelée pour un objet de la classe DonneeDetaillee.
En résumé, les méthodes virtuelles sont des méthodes qui sont appelées selon la vraie classe de l'objet qui l'appelle. Les objets qui contiennent des méthodes virtuelles peuvent être manipulés en tant qu'objets des classes de base, tout en effectuant les bonnes opérations en fonction de leur type. Ils apparaissent donc comme étant des objets de la classe de base et des objets de leur classe complète indifféremment, et on peut les considérer soit comme les uns, soit comme les autres. Un tel comportement est appelé polymorphisme (c'est-à-dire qui peut avoir plusieurs aspects différents). Nous verrons une application du polymorphisme dans le cas des pointeurs sur les objets.
8.14. Dérivation▲
Nous allons voir ici les règles de dérivation. Ces règles permettent de savoir ce qui est autorisé et ce qui ne l'est pas lorsqu'on travaille avec des classes de base et leurs classes filles (ou classes dérivées).
La première règle, qui est aussi la plus simple, indique qu'il est possible d'utiliser un objet d'une classe dérivée partout où l'on peut utiliser un objet d'une de ses classes mères. Les méthodes et données des classes mères appartiennent en effet par héritage aux classes filles. Bien entendu, on doit avoir les droits d'accès sur les membres de la classe de base que l'on utilise (l'accès peut être restreint lors de l'héritage).
La deuxième règle indique qu'il est possible de faire une affectation d'une classe dérivée vers une classe mère. Les données qui ne servent pas à l'initialisation sont perdues, puisque la classe mère ne possède pas les champs correspondants. En revanche, l'inverse est strictement interdit. En effet, les données de la classe fille qui n'existent pas dans la classe mère ne pourraient pas recevoir de valeur, et l'initialisation ne se ferait pas correctement.
Enfin, la troisième règle dit que les pointeurs des classes dérivées sont compatibles avec les pointeurs des classes mères. Cela signifie qu'il est possible d'affecter un pointeur de classe dérivée à un pointeur d'une de ses classes de base. Il faut bien entendu que l'on ait en outre le droit d'accéder à la classe de base, c'est-à-dire qu'au moins un de ses membres puisse être utilisé. Cette condition n'est pas toujours vérifiée, en particulier pour les classes de base dont l'héritage est private.
Un objet dérivé pointé par un pointeur d'une des classes mères de sa classe est considéré comme un objet de la classe du pointeur qui le pointe. Les données spécifiques à sa classe ne sont pas supprimées, elles sont seulement momentanément inaccessibles. Cependant, le mécanisme des méthodes virtuelles continue de fonctionner correctement. En particulier, le destructeur de la classe de base doit être déclaré en tant que méthode virtuelle. Cela permet d'appeler le bon destructeur en cas de destruction de l'objet.
Il est possible de convertir un pointeur de classe de base en un pointeur de classe dérivée si la classe de base n'est pas virtuelle. Cependant, même lorsque la classe de base n'est pas virtuelle, cela est dangereux, car la classe dérivée peut avoir des membres qui ne sont pas présents dans la classe de base, et l'utilisation de ce pointeur peut conduire à des erreurs très graves. C'est pour cette raison qu'un transtypage est nécessaire pour ce type de conversion.
Soient par exemple les deux classes définies comme suit :
#include <iostream>
using namespace std;
class Mere
{
public:
Mere(void);
~Mere(void);
};
Mere::Mere(void)
{
cout << "Constructeur de la classe mère." << endl;
return;
}
Mere::~Mere(void)
{
cout << "Destructeur de la classe mère." << endl;
return;
}
class Fille : public Mere
{
public:
Fille(void);
~Fille(void);
};
Fille::Fille(void) : Mere()
{
cout << "Constructeur de la classe fille." << endl;
return;
}
Fille::~Fille(void)
{
cout << "Destructeur de la classe fille." << endl;
return;
}Avec ces définitions, seule la première des deux affectations suivantes est autorisée :
Mere m; // Instanciation de deux objets.
Fille f;
m=f; // Cela est autorisé, mais l'inverse ne le serait pas :
f=m; // ERREUR !! (ne compile pas)Les mêmes règles sont applicables pour les pointeurs d'objets :
Mere *pm, m;
Fille *pf, f;
pf=&f; // Autorisé.
pm=pf; // Autorisé. Les données et les méthodes
// de la classe fille ne sont plus accessibles
// avec ce pointeur : *pm est un objet
// de la classe mère.
pf=&m; // ILLÉGAL : il faut faire un transtypage :
pf=(Fille *) &m; // Cette fois, c'est légal, mais DANGEREUX !
// En effet, les méthodes de la classe filles
// ne sont pas définies, puisque m est une classe mère.L'utilisation d'un pointeur sur la classe de base pour accéder à une classe dérivée nécessite d'utiliser des méthodes virtuelles. En particulier, il est nécessaire de rendre virtuels les destructeurs. Par exemple, avec la définition donnée ci-dessus pour les deux classes, le code suivant est faux :
Mere *pm;
Fille *pf = new Fille;
pm = pf;
delete pm; // Appel du destructeur de la classe mère !Pour résoudre le problème, il faut que le destructeur de la classe mère soit virtuel (il est inutile de déclarer virtuel le destructeur des classes filles) :
class Mere
{
public:
Mere(void);
virtual ~Mere(void);
};On notera que bien que l'opérateur delete soit une fonction statique, le bon destructeur est appelé, car le destructeur est déclaré virtual. En effet, l'opérateur delete recherche le destructeur à appeler dans la classe de l'objet le plus dérivé. De plus, l'opérateur delete restitue la mémoire de l'objet complet, et pas seulement celle du sous-objet référencé par le pointeur utilisé dans l'expression delete. Lorsqu'on utilise la dérivation, il est donc très important de déclarer les destructeurs virtuels pour que l'opérateur delete utilise le vrai type de l'objet à détruire.
8.15. Méthodes virtuelles pures - Classes abstraites▲
Une méthode virtuelle pure est une méthode qui est déclarée mais non définie dans une classe. Elle est définie dans une des classes dérivées de cette classe.
Une classe abstraite est une classe comportant au moins une méthode virtuelle pure.
Étant donné que les classes abstraites ont des méthodes non définies, il est impossible d'instancier des objets pour ces classes. En revanche, on pourra les référencer avec des pointeurs.
Le mécanisme des méthodes virtuelles pures et des classes abstraites permet de créer des classes de base contenant toutes les caractéristiques d'un ensemble de classes dérivées, pour pouvoir les manipuler avec un unique type de pointeur. En effet, les pointeurs des classes dérivées sont compatibles avec les pointeurs des classes de base, on pourra donc référencer les classes dérivées avec des pointeurs sur les classes de base, donc avec un unique type sous-jacent : celui de la classe de base. Cependant, les méthodes des classes dérivées doivent exister dans la classe de base pour pouvoir être accessibles à travers le pointeur sur la classe de base. C'est ici que les méthodes virtuelles pures apparaissent. Elles forment un moule pour les méthodes des classes dérivées, qui les définissent. Bien entendu, il faut que ces méthodes soient déclarées virtuelles, puisque l'accès se fait avec un pointeur de classe de base et qu'il faut que ce soit la méthode de la classe réelle de l'objet (c'est-à-dire la classe dérivée) qui soit appelée.
Pour déclarer une méthode virtuelle pure dans une classe, il suffit de faire suivre sa déclaration de « =0 ». La fonction doit également être déclarée virtuelle :
virtual type nom(paramètres) =0;=0 signifie ici simplement qu'il n'y a pas d'implémentation de cette méthode dans cette classe.
Note : =0 doit être placé complètement en fin de déclaration, c'est-à-dire après le mot clé const pour les méthodes const et après la déclaration de la liste des exceptions autorisées (voir le Chapitre 9 pour plus de détails à ce sujet).
Un exemple vaut mieux qu'un long discours. Soit donc, par exemple, à construire une structure de données pouvant contenir d'autres structures de données, quels que soient leurs types. Cette structure de données est appelée un conteneur, parce qu'elle contient d'autres structures de données. Il est possible de définir différents types de conteneurs. Dans cet exemple, on ne s'intéressera qu'au conteneur de type sac.
Un sac est un conteneur pouvant contenir zéro ou plusieurs objets, chaque objet n'étant pas forcément unique. Un objet peut donc être placé plusieurs fois dans le sac. Un sac dispose de deux fonctions permettant d'y mettre et d'en retirer un objet. Il a aussi une fonction permettant de dire si un objet se trouve dans le sac.
Nous allons déclarer une classe abstraite qui servira de classe de base pour tous les objets utilisables. Le sac ne manipulera que des pointeurs sur la classe abstraite, ce qui permettra son utilisation pour toute classe dérivant de cette classe. Afin de différencier deux objets égaux, un numéro unique devra être attribué à chaque objet manipulé. Le choix de ce numéro est à la charge des objets, la classe abstraite dont ils dérivent devra donc avoir une méthode renvoyant ce numéro. Les objets devront tous pouvoir être affichés dans un format qui leur est propre. La fonction à utiliser pour cela sera print. Cette fonction sera une méthode virtuelle pure de la classe abstraite, puisqu'elle devra être définie pour chaque objet.
Passons maintenant au programme...
#include <iostream>
using namespace std;
/************* LA CLASSE ABSTRAITE DE BASE *****************/
class Object
{
unsigned long int new_handle(void);
protected:
unsigned long int h; // Identifiant de l'objet.
public:
Object(void); // Le constructeur.
virtual ~Object(void); // Le destructeur virtuel.
virtual void print(void) =0; // Fonction virtuelle pure.
unsigned long int handle(void) const; // Fonction renvoyant
// le numéro d'identification
// de l'objet.
};
// Cette fonction n'est appelable que par la classe Object :
unsigned long int Object::new_handle(void)
{
static unsigned long int hc = 0;
return hc = hc + 1; // hc est l'identifiant courant.
// Il est incrémenté
} // à chaque appel de new_handle.
// Le constructeur de Object doit être appelé par les classes dérivées :
Object::Object(void)
{
h = new_handle(); // Trouve un nouvel identifiant.
return;
}
Object::~Object(void)
{
return ;
}
unsigned long int Object::handle(void) const
{
return h; // Renvoie le numéro de l'objet.
}
/******************** LA CLASSE SAC ******************/
class Bag : public Object // La classe sac. Elle hérite
// de Object, car un sac peut
// en contenir un autre. Le sac
// est implémenté sous la forme
// d'une liste chaînée.
{
struct BagList
{
BagList *next;
Object *ptr;
};
BagList *head; // La tête de liste.
public:
Bag(void); // Le constructeur : appel celui de Object.
~Bag(void); // Le destructeur.
void print(void); // Fonction d'affichage du sac.
bool has(unsigned long int) const;
// true si le sac contient l'objet.
bool is_empty(void) const; // true si le sac est vide.
void add(Object &); // Ajoute un objet.
void remove(Object &); // Retire un objet.
};
Bag::Bag(void) : Object()
{
return; // Ne fait rien d'autre qu'appeler Object::Object().
}
Bag::~Bag(void)
{
BagList *tmp = head; // Détruit la liste d'objet.
while (tmp != NULL)
{
tmp = tmp->next;
delete head;
head = tmp;
}
return;
}
void Bag::print(void)
{
BagList *tmp = head;
cout << "Sac n° " << handle() << "." << endl;
cout << " Contenu :" << endl;
while (tmp != NULL)
{
cout << "\t"; // Indente la sortie des objets.
tmp->ptr->print(); // Affiche la liste objets.
tmp = tmp->next;
}
return;
}
bool Bag::has(unsigned long int h) const
{
BagList *tmp = head;
while (tmp != NULL && tmp->ptr->handle() != h)
tmp = tmp->next; // Cherche l'objet.
return (tmp != NULL);
}
bool Bag::is_empty(void) const
{
return (head==NULL);
}
void Bag::add(Object &o)
{
BagList *tmp = new BagList; // Ajoute un objet à la liste.
tmp->ptr = &o;
tmp->next = head;
head = tmp;
return;
}
void Bag::remove(Object &o)
{
BagList *tmp1 = head, *tmp2 = NULL;
while (tmp1 != NULL && tmp1->ptr->handle() != o.handle())
{
tmp2 = tmp1; // Cherche l'objet...
tmp1 = tmp1->next;
}
if (tmp1!=NULL) // et le supprime de la liste.
{
if (tmp2!=NULL) tmp2->next = tmp1->next;
else head = tmp1->next;
delete tmp1;
}
return;
}Avec la classe Bag définie telle quelle, il est à présent possible de stocker des objets dérivant de la classe Object avec les fonctions add et remove :
class MonObjet : public Object
{
/* Définir la méthode print() pour l'objet... */
};
Bag MonSac;
int main(void)
{
MonObjet a, b, c; // Effectue quelques opérations
// avec le sac :
MonSac.add(a);
MonSac.add(b);
MonSac.add(c);
MonSac.print();
MonSac.remove(b);
MonSac.add(MonSac); // Un sac peut contenir un sac !
MonSac.print(); // Attention ! Cet appel est récursif !
// (plantage assuré).
return 0;
}Nous avons vu que la classe de base servait de moule aux classes dérivées. Le droit d'empêcher une fonction membre virtuelle pure définie dans une classe dérivée d'accéder en écriture non seulement aux données de la classe de base, mais aussi aux données de la classe dérivée, peut donc faire partie de ses prérogatives. Cela est faisable en déclarant le pointeur this comme étant un pointeur constant sur objet constant. Nous avons vu que cela pouvait se faire en rajoutant le mot clé const après la déclaration de la fonction membre. Par exemple, comme l'identifiant de l'objet de base est placé en protected au lieu d'être en private, la classe Object autorise ses classes dérivées à le modifier. Cependant, elle peut empêcher la fonction print de le modifier en la déclarant const :
class Object
{
unsigned long int new_handle(void);
protected:
unsigned long int h;
public:
Object(void); // Le constructeur.
virtual void print(void) const=0; // Fonction virtuelle pure.
unsigned long int handle(void) const; // Fonction renvoyant
// le numéro d'identification
// de l'objet.
};Dans l'exemple donné ci-dessus, la fonction print peut accéder en lecture à h, mais plus en écriture. En revanche, les autres fonctions membres des classes dérivées peuvent y avoir accès, puisque c'est une donnée membre protected. Cette méthode d'encapsulation est donc coopérative (elle requiert la bonne volonté des autres fonctions membres des classes dérivées), tout comme la méthode qui consistait en C à déclarer une variable constante. Cependant, elle permettra de détecter des anomalies à la compilation, car si une fonction print cherche à modifier l'objet sur lequel elle travaille, il y a manifestement une erreur de conception.
Bien entendu, cela fonctionne également avec les fonctions membres virtuelles non pures, et même avec les fonctions non virtuelles.
8.16. Pointeurs sur les membres d'une classe▲
Nous avons déjà vu les pointeurs sur les objets. Il nous reste à voir les pointeurs sur les membres des classes.
Les classes regroupent les caractéristiques des données et des fonctions des objets. Les membres des classes ne peuvent donc pas être manipulés sans passer par la classe à laquelle ils appartiennent. Par conséquent, il faut, lorsqu'on veut faire un pointeur sur un membre, indiquer le nom de sa classe. Pour cela, la syntaxe suivante est utilisée :
définition classe::* pointeur
Par exemple, si une classe test contient des entiers, le type de pointeurs à utiliser pour stocker leur adresse est :
int test::*Si on veut déclarer un pointeur p de ce type, on écrira donc :
int test::*p1; // Construit le pointeur sur entier
// de la classe test.Une fois le pointeur déclaré, on pourra l'initialiser en prenant l'adresse du membre de la classe du type correspondant. Pour cela, il faudra encore spécifier le nom de la classe avec l'opérateur de résolution de portée :
p1 = &test::i; // Récupère l'adresse de i.La même syntaxe est utilisable pour les fonctions. L'emploi d'un typedef est dans ce cas fortement recommandé. Par exemple, si la classe test dispose d'une fonction membre appelée lit, qui n'attend aucun paramètre et qui renvoie un entier, on pourra récupérer son adresse ainsi :
typedef int (test::* pf)(void); // Définit le type de pointeur.
pf p2=&test::lit; // Construit le pointeur et
// lit l'adresse de la fonction.Cependant, ces pointeurs ne sont pas utilisables directement. En effet, les données d'une classe sont instanciées pour chaque objet, et les fonctions membres reçoivent systématiquement le pointeur this sur l'objet de manière implicite. On ne peut donc pas faire un déréférencement direct de ces pointeurs. Il faut spécifier l'objet pour lequel le pointeur va être utilisé. Cela se fait avec la syntaxe suivante :
objet.*pointeurPour les pointeurs d'objet, on pourra utiliser l'opérateur ->* à la place de l'opérateur .* (appelé pointeur sur opérateur de sélection de membre).
Ainsi, si a est un objet de classe test, on pourra accéder à la donnée i de cet objet à travers le pointeur p1 avec la syntaxe suivante :
a.*p1 = 3; // Initialise la donnée membre i de a avec la valeur 3.Pour les fonctions membres, on mettra des parenthèses à cause des priorités des opérateurs :
int i = (a.*p2)(); // Appelle la fonction lit() pour l'objet a.Pour les données et les fonctions membres statiques, cependant, la syntaxe est différente. En effet, les données n'appartiennent plus aux objets de la classe, mais à la classe elle-même, et il n'est plus nécessaire de connaître l'objet auquel le pointeur s'applique pour les utiliser. De même, les fonctions membres statiques ne reçoivent pas le pointeur sur l'objet, et on peut donc les appeler sans référencer ce dernier.
La syntaxe s'en trouve donc modifiée. Les pointeurs sur les membres statiques des classes sont compatibles avec les pointeurs sur les objets et les fonctions non-membres. Par conséquent, si une classe contient une donnée statique entière, on pourra récupérer son adresse directement et la mettre dans un pointeur d'entier :
int *p3 = &test::entier_statique; // Récupère l'adresse
// de la donnée membre
// statique.
La même syntaxe s'appliquera pour les fonctions :
typedef int (*pg)(void);
pg p4 = &test::fonction_statique; // Récupère l'adresse
// d'une fonction membre
// statique.Enfin, l'utilisation des ces pointeurs est identique à celle des pointeurs classiques, puisqu'il n'est pas nécessaire de fournir le pointeur this. Il est donc impossible de spécifier le pointeur sur l'objet sur lequel la fonction doit travailler aux fonctions membres statiques. Cela est naturel, puisque les fonctions membres statiques ne peuvent pas accéder aux données non statiques d'une classe.
#include <iostream>
using namespace std;
class test
{
int i;
static int j;
public:
test(int j)
{
i=j;
return ;
}
static int get(void)
{
/* return i ; INTERDIT : i est non statique
et get l'est ! */
return j; // Autorisé.
}
};
int test::j=5; // Initialise la variable statique.
typedef int (*pf)(void); // Pointeur de fonction renvoyant
// un entier.
pf p=&test::get; // Initialisation licite, car get
// est statique.
int main(void)
{
cout << (*p)() << endl;// Affiche 5. On ne spécifie pas l'objet.
return 0;
}