


6. Modularité des programmes et génération des binaires▲
La modularité est le fait, pour un programme, d'être écrit en plusieurs morceaux relativement indépendants les uns des autres. La modularité a d'énormes avantages lors du développement d'un programme. Cependant, elle implique un processus de génération de l'exécutable assez complexe. Dans ce chapitre, nous allons voir l'intérêt de la modularité, les différentes étapes qui permettent la génération de l'exécutable et l'influence de ces étapes sur la syntaxe du langage.
6.1. Pourquoi faire une programmation modulaire ?▲
Ce qui coûte le plus cher en informatique, c'est le développement de logiciel, pas le matériel. En effet, développer un logiciel demande du temps, de la main d'oeuvre qualifiée, et n'est pas facile (il y a toujours des erreurs). De plus, les logiciels développés sont souvent spécifiques à un type de problème donné. Pour chaque problème, il faut tout refaire.
Ce n'est pas un très bon bilan. Pour éviter tous ces inconvénients, une branche de l'informatique a été développée : le génie logiciel. Le génie logiciel donne les grands principes à appliquer lors de la réalisation d'un programme, de la conception à la distribution, et sur toute la durée de vie du projet. Ce sujet dépasse largement le cadre de ce cours, aussi je ne parlerais que de l'aspect codage seul, c'est-à-dire ce qui concerne le C/C++.
Au niveau du codage, le plus important est la programmation modulaire.
Les idées qui en sont à la base sont les suivantes :
- diviser le travail en plusieurs équipes ;
- créer des morceaux de programme indépendants de la problématique globale, donc réutilisables pour d'autres logiciels ;
- supprimer les risques d'erreurs qu'on avait en reprogrammant ces morceaux à chaque fois.
Je tiens à préciser que les principes de la programmation modulaire ne s'appliquent pas qu'aux programmes développés par des équipes de programmeurs. Ils s'appliquent aussi aux programmeurs individuels. En effet il est plus facile de décomposer un problème en ses éléments, forcément plus simples, que de le traiter dans sa totalité (dixit Descartes).
Pour parvenir à ce but, il est indispensable de pouvoir découper un programme en sous-programmes indépendants, ou presque indépendants. Pour que chacun puisse travailler sur sa partie de programme, il faut que ces morceaux de programme soient dans des fichiers séparés.
Pour pouvoir vérifier ces morceaux de programme, il faut que les compilateurs puissent les compiler indépendamment, sans avoir les autres fichiers du programme. Ainsi, le développement de chaque fichier peut se faire relativement indépendamment de celui des autres. Cependant, cette division du travail implique des opérations assez complexes pour générer l'exécutable.
6.2. Les différentes phases du processus de génération des exécutables▲
Les phases du processus qui conduisent à l'exécutable à partir des fichiers sources d'un programme sont décrites ci-dessous. Ces phases ne sont en général pas spécifiques au C++, et même si les différents outils de programmation peuvent les cacher, le processus de génération des exécutables se déroule toujours selon les principes qui suivent.
Au début de la génération de l'exécutable, on ne dispose que des fichiers sources du programme, écrit en C, C++ ou tout autre langage (ce qui suit n'est pas spécifique au C/C++). En général, la première étape est le traitement des fichiers sources avant compilation. Dans le cas du C et du C++, il s'agit des opérations effectuées par le préprocesseur (remplacement de macros, suppression de texte, inclusion de fichiers...).
Vient ensuite la compilation séparée, qui est le fait de compiler séparément les fichiers sources. Le résultat de la compilation d'un fichier source est généralement un fichier en assembleur, c'est-à-dire le langage décrivant les instructions du microprocesseur de la machine cible pour laquelle le programme est destiné. Les fichiers en assembleur peuvent être traduits directement en ce que l'on appelle des fichiers objets. Les fichiers objets contiennent la traduction du code assembleur en langage machine. Ils contiennent aussi d'autres informations, par exemple les données initialisées et les informations qui seront utilisées lors de la création du fichier exécutable à partir de tous les fichiers objets générés. Les fichiers objets peuvent être regroupés en bibliothèques statiques, afin de rassembler un certain nombre de fonctionnalités qui seront utilisées ultérieurement.
Enfin, l'étape finale du processus de compilation est le regroupement de toutes les données et de tout le code des fichiers objets du programme et des bibliothèques (fonctions de la bibliothèque C standard et des autres bibliothèques complémentaires), ainsi que la résolution des références inter-fichiers. Cette étape est appelée édition de liens (« linking » en anglais). Le résultat de l'édition de liens est le fichier image, qui pourra être chargé en mémoire par le système d'exploitation. Les fichiers exécutables et les bibliothèques dynamiques sont des exemples de fichiers image.
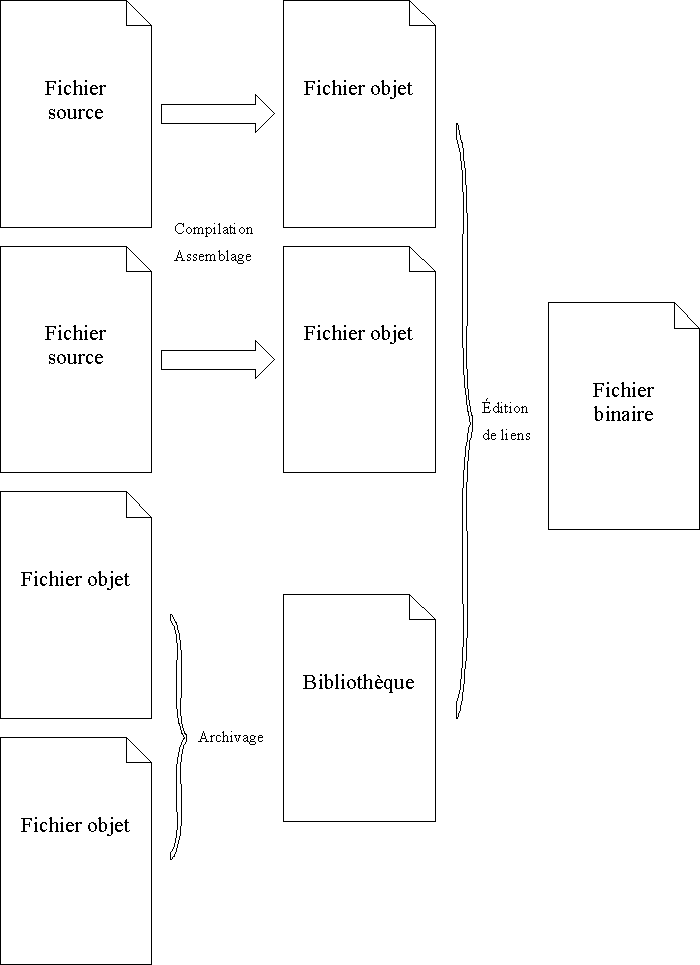
Toutes ces opérations peuvent être régroupées en une seule étape par les outils utilisés. Ainsi, les compilateurs appellent généralement le préprocesseur et l'assembleur automatiquement, et réalisent parfois même l'édition de liens eux-mêmes. Toutefois, il reste généralement possible, à l'aide d'options spécifiques à chaque outil de développement, de décomposer les différentes étapes et d'obtenir les fichiers intermédiaires.
En raison du nombre de fichiers important et des dépendances qui peuvent exister entre eux, le processus de génération d'un programme prend très vite une certaine ampleur. Les deux problèmes les plus courants sont de déterminer l'ordre dans lequel les fichiers et les bibliothèques doivent être compilés, ainsi que les dépendances entre fichiers sources et les fichiers produits afin de pouvoir regénérer correctement les fichiers images après une modification des sources. Tous ces problèmes peuvent être résolus à l'aide d'un programme appelé make. Le principe de make est toujours le même, même si aucune norme n'a été définie en ce qui le concerne. make lit un fichier (le fichier (« makefile »), dans lequel se trouvent toutes les opérations nécessaires pour compiler un programme. Puis, il les exécute si c'est nécessaire. Par exemple, un fichier qui a déjà été compilé et qui n'a pas été modifié depuis ne sera pas recompilé. C'est plus rapide. make se base sur les dates de dernière modification des fichiers pour savoir s'ils ont été modifiés (il compare les dates des fichiers sources et des fichiers produits). La date des fichiers est gérée par le système d'exploitation : il est donc important que l'ordinateur soit à l'heure.
6.3. Compilation séparée en C/C++▲
La compilation séparée en C/C++ se fait au niveau du fichier.
Il existe trois grands types de fichiers sources en C/C++ :
- les fichiers d'en-tête, qui contiennent toutes les déclarations communes à plusieurs fichiers sources. Ce sont les fichiers d'en-têtes qui, en séparant la déclaration de la définition des symboles du programme, permettent de découper l'ensemble des sources en fichiers compilables séparément ;
- les fichiers C, qui contiennent les définitions des symboles en langage C ;
- les fichiers C++, qui contiennent les définitions des symboles en langage C++.
On utilise une extension différente pour les fichiers C et les fichiers C++ afin de les différencier. Les conventions utilisées dépendent du compilateur.
Cependant, on peut en général établir les règles suivantes :
- les fichiers C ont l'extension .c ;
- les fichiers C++ prennent l'extension .cc, ou .C (majuscule) sur UNIX, ou .cpp sur les PC sous DOS ou Windows (ces deux systèmes ne faisant pas la différence entre les majuscules et les minuscules dans leurs systèmes de fichiers) ;
- les fichiers d'en-tête ont l'extension .h, parfois .hpp (en-tête C++).
Les programmes modulaires C/C++ auront donc typiquement la structure suivante :
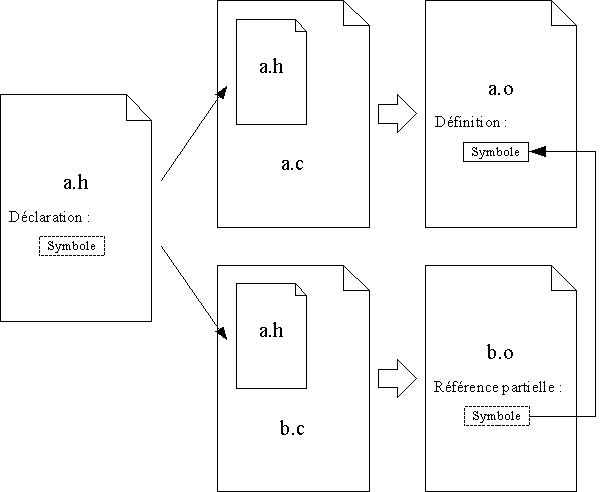
Note : Il faudra bien faire la distinction entre les fichiers sources compilés séparément et les fichiers inclus par le préprocesseur. Ces derniers sont en effet compilés avec les fichiers dans lesquels ils sont inclus. Il n'est donc pas recommandé d'inclure des définitions de symboles dans les fichiers d'en-tête, car ces symboles risquent d'apparaître dans plusieurs fichiers objets après la compilation. Cela provoque généralement une erreur à l'édition de liens, parce que l'éditeur de liens ne peut pas déterminer quelle définition prendre parmi celles qui se trouvent dans les différents fichiers objets.
6.4. Syntaxe des outils de compilation▲
Il existe évidemment un grand nombre de compilateurs C/C++ pour chaque plate-forme. Ils ne sont malheureusement pas compatibles au niveau de la ligne de commande. Le même problème apparaît pour les éditeurs de liens (« linker » en anglais) et pour make. Cependant, quelques principes généraux peuvent être établis. Dans la suite, je supposerai que le nom du compilateur est « cc », que celui du préprocesseur est « cpp », celui de l'éditeur de liens est « ld » et que celui de make est « make ».
En général, les différentes étapes de la compilation et de l'édition de liens sont regroupées au niveau du compilateur, ce qui permet de faire les phases de traitement du préprocesseur, de compilation et d'édition de liens en une seule commande. Les lignes de commandes des compilateurs sont donc souvent compliquées et très peu portable. En revanche, la syntaxe de make est un peu plus portable.
6.4.1. Syntaxe des compilateurs▲
Le compilateur demande en général les noms des fichiers sources à compiler et les noms des fichiers objets à utiliser lors de la phase d'édition de liens. Lorsque l'on spécifie un fichier source, le compilateur utilisera le fichier objet qu'il aura créé pour ce fichier source en plus des fichiers objets donnés dans la ligne de commande. Le compilateur peut aussi accepter en ligne de commande le chemin de recherche des bibliothèques du langage et des fichiers d'en-tête. Enfin, différentes options d'optimisation sont disponibles (mais très peu portables). La syntaxe (simplifiée) des compilateurs est souvent la suivante :
cc [fichier.o [...]] [[-c] fichier.c [...]] [-o exécutable]
[-Lchemin_bibliothèques] [-lbibliothèque [...]] [-Ichemin_include]fichier.c est le nom du fichier à compiler. Si l'option -c le précède, le fichier sera compilé, mais l'éditeur de liens ne sera pas appelé. Si cette option n'est pas présente, l'éditeur de liens est appelé, et le programme exécutable formé est enregistré dans le fichier a.out. Pour donner un autre nom à ce programme, il faut utiliser l'option -o, suivie du nom de l'exécutable. Il est possible de donner le nom des fichiers objets déjà compilés (« fichier.o ») pour que l'éditeur de liens les lie avec le programme compilé.
L'option -L permet d'indiquer le chemin du répertoire des bibliothèques de fonctions prédéfinies. Ce répertoire sera ajouté à la liste des répertoires indiqués dans la variable d'environnement LIBRARY_PATH. L'option -l demande au compilateur d'utiliser la bibliothèque spécifiée, si elle ne fait pas partie des bibliothèques utilisées par défaut. De même, l'option -I permet de donner le chemin d'accès au répertoire des fichiers à inclure (lors de l'utilisation du préprocesseur). Les chemins ajoutés avec cette option viennent s'ajouter aux chemins indiqués dans les variables d'environnement C_INCLUDE_PATH et CPLUS_INCLUDE_PATH pour les programmes compilés respectivement en C et en C++.
L'ordre des paramètres sur la ligne de commande est significatif. La ligne de commande est exécutée de gauche à droite.
cc -c fichier1.c
cc fichier1.o programme.cc -o lancez_moiDans cet exemple, le fichier C fichier1.c est compilé en fichier1.o, puis le fichier C++ programme.cc est compilé et lié au fichier1.o pour former l'exécutable lancez_moi.
6.4.2. Syntaxe de make▲
La syntaxe de make est très simple :
makeEn revanche, la syntaxe du fichier makefile est un peu plus compliquée et peu portable. Cependant, les fonctionnalités de base sont gérées de la même manière par la plupart des programme make.
Le fichier makefile est constitué d'une série de lignes d'information et de lignes de commande (de l'interpréteur de commandes UNIX ou DOS). Les commandes doivent toujours être précédées d'un caractère de tabulation horizontale.
Les lignes d'information donnent des renseignements sur les dépendances des fichiers (en particulier, les fichiers objets qui doivent être utilisés pour créer l'exécutable). Les lignes d'information permettent donc à make d'identifier les fichiers sources à compiler afin de générer l'exécutable. Les lignes de commande indiquent comment effectuer cette compilation (et éventuellement d'autres tâches).
La syntaxe des lignes d'information est la suivante :
nom:dépendanceoù nom est le nom de la cible (généralement, il s'agit du nom du fichier destination), et dépendance est la liste des noms des fichiers dont dépend cette cible, séparés par des espaces. La syntaxe des lignes de commande utilisée est celle de l'interpréteur du système hôte. Enfin, les commentaires dans un fichier makefile se font avec le signe dièse (#).
# Compilation du fichier fichier1.c :
cc - c fichier1.c
# Compilation du programme principal :
cc -o Lancez_moi fichier1.o programme.c# Indique les dépendances :
Lancez_moi: fichier1.o programme.o
# Indique comment compiler le programme :
# (le symbole $@ représente le nom de la cible, ici, Lancez_moi)
cc -o $@ fichier1.o programme.o
#compile les dépendances :
fichier1.o: fichier1.c
cc -c fichier1.c
programme.o: programme1.c
cc -c programme.c6.5. Problèmes syntaxiques relatifs à la compilation séparée▲
Pour que le compilateur puisse compiler les fichiers séparément, il faut que vous respectiez les conditions suivantes :
- chaque type ou variable utilisé doit être déclaré ;
- toute fonction non déclarée doit renvoyer un entier (en C seulement, en C++, l'utilisation d'une fonction non déclarée génère une erreur).
Ces conditions ont des répercussions sur la syntaxe des programmes. Elles seront vues dans les paragraphes suivants.
6.5.1. Déclaration des types▲
Les types doivent toujours être définis avant toute utilisation dans un fichier source. Par exemple, il est interdit d'utiliser une structure client sans l'avoir définie avant sa première utilisation. Toutefois, il est possible d'utiliser un pointeur sur un type de donnée sans l'avoir complètement défini. Une simple déclaration du type de base du pointeur suffit en effet dans ce cas là. De même, un simple class MaClasse suffit en C++ pour déclarer une classe sans la définir complètement.
6.5.2. Déclaration des variables▲
Les variables qui sont définies dans un autre fichier doivent être déclarées avant leur première utilisation. Pour cela, on les spécifie comme étant des variables externes, avec le mot clé extern :
extern int i; /* i est un entier qui est déclaré et
créé dans un autre fichier.
Ici, il est simplement déclaré.
*/Inversement, si une variable ne doit pas être accédée par un autre module, il faut déclarer cette variable statique. Ainsi, même si un autre fichier utilise le mot clé extern, il ne pourra pas y accéder.
6.5.3. Déclaration des fonctions▲
Lorsqu'une fonction se trouve définie dans un autre fichier, il est nécessaire de la déclarer. Pour cela, il suffit de donner sa déclaration (le mot clé extern est également utilisable, mais facultatif dans ce cas) :
int factorielle(int);
/*
factorielle est une fonction attendant comme paramètre
un entier et renvoyant une valeur entière.
Elle est définie dans un autre fichier.
*/Les fonctions inline doivent impérativement être définies dans les fichiers où elles sont utilisées, puisqu'en théorie, elles sont recopiées dans les fonctions qui les utilisent. Cela implique de placer leur définition dans les fichiers d'en-tête .h ou .hpp. Comme le code des fonctions inline est normalement inclus dans le code des fonctions qui les utilisent, les fichiers d'en-tête contenant du code inline peuvent être compilés séparément sans que ces fonctions ne soient définies plusieurs fois. Par conséquent, l'éditeur de liens ne générera pas d'erreur (alors qu'il l'aurait fait si on avait placé le code d'une fonction non inline dans un fichier d'en-tête inclus dans plusieurs fichiers sources .c ou .cpp). Certains programmeurs considèrent qu'il n'est pas bon de placer des définitions de fonctions dans des fichiers d'en-tête, il placent donc toutes leurs fonctions inline dans des fichiers portant l'extension .inl. Ces fichiers sont ensuite inclus soit dans les fichiers d'en-tête .h, soit dans les fichiers .c ou .cpp qui utilisent les fonctions inline.
6.5.4. Directives d'édition de liens▲
Le langage C++ donne la possibilité d'appeler des fonctions et d'utiliser des variables qui proviennent d'un module écrit dans un autre langage. Pour permettre cela, il dispose de directives permettant d'indiquer comment l'édition de liens doit être faite. La syntaxe permettant de réaliser cela utilise le mot clé extern, avec le nom du langage entre guillemets. Cette directive d'édition de liens doit précéder les déclarations de variables et de données concernées. Si plusieurs variables ou fonctions utilisent la même directive, elles peuvent être regroupées dans un bloc délimité par des accolades, avec la directive d'édition de liens placée juste avant ce bloc. La syntaxe est donc la suivante :
extern "langage" [déclaration | {
déclaration
[...]
}]Cependant, les seuls langages qu'une implémentation doit obligatoirement supporter sont les langages « C » et « C++ ». Pour les autres langages, aucune norme n'est définie et les directives d'édition de liens sont dépendantes de l'implémentation.