

10 groupes d'études et plusieurs nouvelles dates de sortie pour les prochaines normes
Depuis la première annonce l'année dernière, le comité à fait plein de petits bébés : la famille s'est agrandie et compte maintenant 10 SG (study group), 4 WG (working group) et un comité.
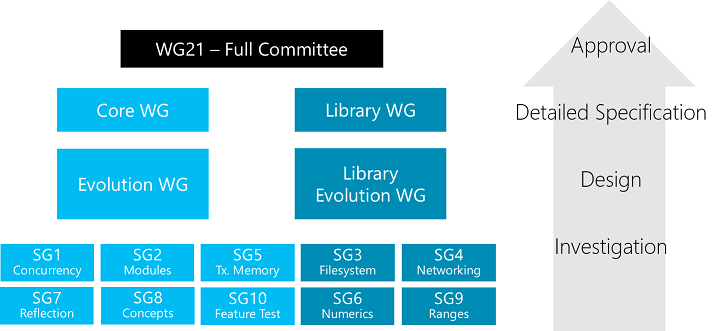
Les working groups ont pour rôle de proposer les modifications à apporter à la norme, modifications qui seront approuvées, ou non, par le comité de normalisation.
- le core working group (CWG) a la charge des corrections sur le langage (chapitres 1 à 16 de la norme) ;
- l'evolution working group (EWG) travaille sur l'évolution du langage (travaux qui sont délégués aux study groups) ;
- le library working group (LWG) s'occupe de le maintenance de la bibliothèque standard (chapitres 17 et suivants de la norme) ;
- le library evolution working groupe (LEWG) est responsable de l'évolution de la bibliothèque standard (travaux qui sont délégués aux study groups).
Les study groups ont la charge d'étudier les évolutions du langage (SG 1, 2, 5, 7, 8 et 10) et de la bibliothèque (SG 3, 4, 6 et 9) sur des thèmes spécifiques et de proposer des modifications de la norme aux WG :
- SG1 Concurrency : concurrence et parallélisme ;
- SG2 Modules : utilisation de modules à la place du système d'en-têtes ;
- SG3 File System : gestion des fichiers (basé sur Boost.Filesystem v3) ;
- SG4 Networking : gestion du réseau, sockets et HTTP ;
- SG5 Transactional Memory : mémoires transactionnelles (mémoire permettant de créer un ensemble indivisible d'écriture et lecture) ;
- SG6 Numerics : analyse numérique, nombres réels fixes et flottants, fractions ;
- SG7 Reflection : réflexion à la compilation ;
- SG8 Concepts : ajout de contraintes sur les types ;
- SG9 Ranges : alternative aux itérateurs ;
- SG10 Feature Test : standardisation des tests.
Au niveau du planning, le comité s'active, avec plus d'une centaine de propositions pour le congrès de Bristol (voir la discussion [ISOC++] Mailing pre-Bristol). En plus de la prochaine norme qui devrait sortir en 2017, le comité prévoit des Technical Specifications, pour les ajouts de fonctionnalités indépendantes, et une révision mineure de la norme en 2014.

 Quelles sont les fonctionnalités qui vous intéressent le plus ? Celles que vous auriez aimer avoir ? Que pensez-vous de laccélération prise par le comité pour le langage et la bibliothèque standard ?
Quelles sont les fonctionnalités qui vous intéressent le plus ? Celles que vous auriez aimer avoir ? Que pensez-vous de laccélération prise par le comité pour le langage et la bibliothèque standard ?Source : http://isocpp.org/std/the-committee
Vous avez lu gratuitement 5 922 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.



