


I. Introduction▲
Dans cette section et la suivante, nous parlerons un peu plus des grammaires, nous présenterons le rôle des transformées dans l'évaluation d'expressions et nous étudierons en détail l'extension d'expression : celle-ci pouvant fournir aux expressions Proto – jusqu'ici de bêtes arborescences statiques – des comportements qui leur sont propres.
Par ce biais, nous offrirons à nos expressions de nouvelles opportunités. D'ici la fin de cet article, vous saurez tirer parti des grammaires et des transformées dans l'évaluation de vos expressions. Au terme de l'article suivant, vous saurez définir un domaine Proto et doter vos expressions de comportements spécifiques à ce domaine, donnant ainsi corps à votre DSEL.
Entre-temps, nous implémenterons une petite bibliothèque (1) pour nos lambda, légère autant qu'utile.
Complément
Dans cette série d'articles, je me suis efforcé de rendre mes billets accessibles et intéressants pour un développeur C++ de niveau intermédiaire. De ce point de vue, cet article n'est peut-être pas le plus réussi. N'hésitez pas à consulter ces « compléments », où j'essaierai de clarifier certains points quant aux concepts et syntaxes alambiqués présentés dans cette partie.
II. Algorithmes STL, objets-fonctions et lambda▲
La STL nous a offert la possibilité de séparer les structures de données des algorithmes, permettant à un même algorithme de travailler efficacement sur des std::list, des std::map, des std::vector ou même des types définis par l'utilisateur. On lui doit également toute une prolifération d'objets-fonctions ponctuels servant à adapter le comportement des algorithmes, ainsi qu'une curieuse petite collection de fonctions bind et d'adaptateurs. Par exemple, si vous souhaitez ajouter une valeur constante à chaque élément d'une séquence, vous pouvez soit définir votre propre objet-fonction à l'usage de std::transform, soit utiliser les fonctions bind standards, comme suit :
#include <algorithm>
#include <functional>
// Définit un objet-fonction pour ajouter une valeur constante à un entier
struct add_constant
{
typedef int result_type;
explicit add_constant(int i) : i_(i)
{}
int operator()(int i) const
{
return i + i_;
}
private:
int i_;
};
int main()
{
int data[10] = {0,1,2,3,4,5,6,7,8,9};
// Ajoute 42 à chaque élément de "data" en utilisant un objet-fonction isolé
std::transform( data, data+10, data, add_constant(42) );
// Idem, mais en utilisant un objet-fonction issu de bind sur un objet-fonction standard
std::transform( data, data+10, data, std::bind1st( std::plus<int>(), 42 ) );
}Chaque appel à std::transform ci-dessus ajoute 42 à chaque élément du tableau data. Le problème avec la définition d'objets-fonctions isolés tels que add_constant, c'est qu'ils s'accompagnent de beaucoup de code superflu (2). En outre, ils séparent inutilement l'action de son appel. En comparaison, la ligne suivante qui fait appel à bind et à l'objet-fonction serait presque un modèle de concision. C'est peu dire. Toutefois si l'objet-fonction devait gagner en complexité, l'utilisation de bind sur l'objet-fonction perdrait en lisibilité et, parfois même, aucune combinaison de binder/adaptator/negator n'aboutirait au résultat souhaité.
Le C++11 nous fournit une bien meilleure solution : des fonctions lambda de première classe. L'exemple qui précède devient immédiatement plus compact avec l'utilisation de lambda :
// Ajoute 42 à chaque élément d'un tableau en utilisant les fonctions lambda du C++11
std::transform( data, data+10, data, [] (int j) { return j + 42; } );Les fonctions lambda du C++11 se développent beaucoup plus clairement que les fonctions bind quand les expressions se complexifient et j'encourage sincèrement leur utilisation. Si votre compilateur ne les gère pas, quelques options s'offrent à vous :
- fuir. Et en trouver un qui les gère ;
- utiliser Boost.Phoenix (3) ;
- faire votre propre bibliothèque de fonctions lambda, sur environ 30 lignes de code grâce à Boost.Proto.
Bien sûr il existe de bonnes raisons de ne pas en recréer une soi-même, mais cela vous permettra d'explorer par vous-même, au fil de cette série d'articles, les mécanismes internes à Boost.Phoenix en vous octroyant une pleine maîtrise de Boost.Proto.
Les fonctions lambda du C++11 nous préserveraient donc de l'utilisation de bibliothèques telles que Boost.Phoenix ? Pas tout à fait. L'une des raisons à cela est que, contrairement aux fonctions lambda du C++11, celles de Phoenix sont polymorphiques (4) : pas besoin de spécifier les types d'arguments acceptés. En d'autres termes, une même expression Phoenix pourra ajouter 42 à un tableau de int ou de MonBonGrosTypeInt, chose impossible avec une lambda C++11. Mais la vraie raison pour laquelle Phoenix n'a pas à craindre C++11, c'est la structure arborescente de ses expressions, que vous pouvez inspecter et manipuler dès la compilation. Plus de détails sur ce point dans les prochains articles.
III. Lambda dans une bibliothèque▲
Avec Boost.Phoenix, la solution au problème précédent pourrait ressembler à ça :
// On utilise Boost.Phoenix pour ajouter 42 à tous les éléments d'un tableau
using boost::phoenix::arg_names::arg1;
std::transform(data, data+10, data, arg1 + 42 );L'expression arg1 + 42 crée un objet avec un opérateur d'appel de fonction : un objet-fonction. L'objet arg1 défini par Phoenix est un placeholder auquel se substituera une valeur réelle au moment de l'appel de l'objet-fonction. Concrètement : (arg1 + 42)(1) => (1 + 42) => (43).
Comment cela fonctionne-t-il ? Si vous avez lu les précédents articles de cette série, vous aurez certainement deviné que l'expression arg1 + 42 construit un certain type d'arborescence et pas n'importe laquelle : l'une où operator() réalise effectivement une action. Voilà donc une arborescence dont le comportement est spécifique à un domaine. Jusqu'à présent, les arborescences que Proto nous construisait n'avaient rien de très palpitant et ne dépendaient d'aucun domaine. D'une manière ou d'une autre, il va falloir que Proto nous construise non seulement une arborescence, mais également une arborescence lambda.
Mais avant d'apprendre ce nouveau tour, faisons déjà en sorte que l'expression arg1 + 42 compile (les explications suivront) :
#include <boost/proto/proto.hpp>
using namespace boost;
struct arg1_tag {};
proto::terminal<arg1_tag>::type const arg1 = {};
int main()
{
arg1 + 42;
}Plutôt facile. L'expression arg1 + 42 nous construit une arborescence statique, ennuyeuse à souhait. L'expression est représentée dans la figure 1 ci-dessous.
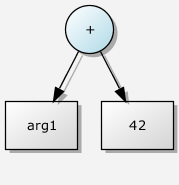
Complément : pourquoi arg1_tag est-il vide ?
Une erreur assez courante chez les nouveaux utilisateurs de bibliothèques comme Boost.Lambda et Boost.Phoenix est de penser que les placeholders tels que arg1 peuvent être modifiés, qu'à un certain moment ceux-ci se verront affecter la valeur à laquelle ils se substituent. Ce n'est pas le cas. Au contraire, toute l'expression lambda, arg1 compris, est inaltérable et inaltérée pendant son exécution. Les arguments réels, passés à la lambda pendant l'exécution, se trouvent dans un emplacement séparé. Quant à savoir si une valeur doit être lue depuis la lambda elle-même ou depuis cet emplacement, cette décision repose sur le type de la valeur. Par exemple, le type int n'ayant rien de spécial, le passage d'un entier tel que 42 à une expression lambda s'explique de lui-même. En revanche, un type arg1_tag aura droit à un traitement spécial. Phoenix comprend que des terminaux de type arg1_tag désignent les données d'un emplacement et lira donc ces données à la place.
arg1 est donc un simple placeholder – un substitut pour des données situées autre part. La seule chose importante à propos de arg1 est son type ; il s'agit d'un nœud terminal d'un type spécial – la structure arg1_tag – qui s'avère être vide. C'est une pratique très courante en conception de DSEL.
Complément : principe d'initialisation par accolades
J'ai reçu plusieurs questions à propos de l'étrange syntaxe utilisée pour l'initialisation avec des accolades de l'objet arg1. D'ailleurs, à quoi correspond arg1 ? Je ne mentionne nulle part le typedef de proto::terminal<arg1_tag>::type. Certes, c'est un nœud terminal présent dans une expression arborescente – une abstraction – et son type réel ne devrait pas nous préoccuper. Malheureusement, dans ce cas précis, c'est une abstraction perméable ; certains détails d'implémentation de arg1 refont surface. Notamment, le fait que le type de arg1 soit de l'ordre des POD – une structure de style C, sans constructeur, ni classe parente, ni accesseurs, ni fonctions virtuelles – transparaît par la manière dont arg1 doit être initialisé.
Par défaut, toutes les expressions Proto sont des POD et nécessitent une initialisation via les accolades. Pourquoi ? Pour permettre une initialisation statique des objets tels que arg1. La construction d'un DSEL amène souvent à devoir définir des constantes globales (par exemple arg1) directement dans un espace de nom. Si ces objets étaient munis de constructeurs devant être appelés avant la fonction main, alors il serait possible, en imaginant un scénario précis, d'utiliser ces données globales avant leur initialisation. On souhaite à tout prix l'éviter. Au lieu de ça, en faisant de arg1 un POD et en utilisant la syntaxe d'initialisation par accolades, le C++ nous garantit que ces objets seront initialisés avant même l'exécution ; arg1 existe quoiqu'il arrive et vous n'avez pas à vous inquiéter de bogues étranges issus d'ordres d'initialisation chaotiques.
Maintenant, plus difficile : faire en sorte que cette arborescence fasse quelque chose.
IV. Présentation des transformées de Proto▲
Si vous êtes un tant soit peu familier avec les outils de construction de compilateurs, tels que ANTLR, yacc ou Spirit, vous devez savoir que pour réaliser une analyse syntaxique, vous devez intégrer des actions sémantiques à la grammaire de votre langage. Les actions sémantiques sont exécutées quand ce qui est fourni en entrée présente des correspondances avec votre grammaire. Proto fait de même. Si ces histoires d'analyse syntaxique ne vous disent rien, alors un peu de patience, ce sera bientôt le cas. Dans Proto, les actions sémantiques sont appelées transformées, un genre particulier d'objet-fonction. Ils acceptent des arborescences d'expressions ainsi que des états additionnels et réalisent des calculs.
Pour les DSEL qui ressemblent et se comportent majoritairement comme le C++, Proto fournira proto::_default, une transformée bien appréciable. Celle-ci rend aux opérateurs leur rôle initial, tels qu'ils se comportent en C++. Observez le code suivant :
// On utilise l'évaluateur d'expression par défaut
proto::_default<> eval;
// On crée une arborescence représentant
// l'expression "1 + 2" et on l'évalue.
int i = eval( proto::lit(1) + 2 );
assert( i == 3 );La première ligne déclare un objet-fonction eval, qui sait comment évaluer des arborescences représentant les expressions C++ qui ont créé ces arbres. En passant proto::lit(1) + 2 à eval, nous obtenons 3. Plutôt facile. Proto::lit est une fonction qui transforme son argument en un terminal Proto, développant ainsi l'arborescence des expressions où elle s'utilise.
Essayer de transmettre l'expression arg1 + 42 à eval ne produirait rien de bon ; proto::_default ne sait pas comment utiliser arg1. Nous lui apprendrons ci-dessous.
Complément
Les transformées sont un point important et cette introduction n'en dit pas très long à ce sujet. Je vais m'efforcer de détailler un peu plus. L'un des obstacles à la compréhension des transformées est qu'elles constituent leur propre petit langage de programmation, selon une syntaxe assez particulière. À moins de connaître ce langage, les transformées risquent de ne pas beaucoup vous parler. Plutôt que de vous présenter cette syntaxe de but en blanc, je vais tenter d'expliquer la logique des transformées, tout d'abord en utilisant un pseudoC++ dépourvu de types. En constatant la logique d'une transformée au-delà de son aspect syntaxique, le fonctionnement des véritables transformées C++ devrait vous sembler plus clair.
À cet effet, voyons à quoi ressemble la transformée _default dans un pseudoC++ sans types :
// On définit une fonction _default qui évalue récursivement
// une arborescence d'expressions selon les règles du C++
auto _default( expr )
{
// Renvoie au cas qui correspond
// au type de noeud de l'expression
switch ( tag_type( expr ) )
{
case terminal:
return value( expr );
case plus:
return _default( left( expr ) ) + _default( right( expr ) );
case minus:
return _default( left( expr ) ) - _default( right( expr ) );
// ... gère tous les opérateurs de manière équivalente
}
}Ci-dessus, tag_type retourne le type d'un nœud d'expressions, left l'enfant de gauche d'un nœud binaire, right l'enfant de droite et value la valeur stockée dans un nœud terminal.
Examinons ce point plus en détail. Comme je l'ai dit, les transformées peuvent accepter un paramètre d'état additionnel. Ainsi, la transformée _default pourra être paramétrée quant au type d'opération à effectuer pour chaque nœud enfant. Cette opération est _default par défaut. Et donc, en pseudocode, _default ressemblera plutôt à cela :
// Définit une fonction _default qui évalue récursivement
// une arborescence d'expressions selon les règles du C++
auto _default( expr, state = null, eval = _default )
{
// Renvoie au cas qui correspond
// au type de noeud de l'expression
switch ( tag_type( expr ) )
{
case terminal:
return value( expr );
case plus:
return eval( left( expr ), state, eval ) + eval( right( expr ), state, eval );
case minus:
return eval( left( expr ), state, eval ) - eval( right( expr ), state, eval );
// ... gère tous les opérateurs de manière équivalente
}
}En C++ réel, eval est un paramètre de _default, mais le résultat final est le même. Espérons-le, la transformée _default devrait maintenant vous sembler un peu moins obscure.
V. Passer un état aux transformées▲
Comme dit précédemment, vous pouvez éventuellement passer des états additionnels au moment d'évaluer vos transformées. Passez simplement cet état en second paramètre :
// Un second paramètre peut être passé à eval
// Dans le cas présent, il est ignoré
int i = eval( proto::lit(1) + 2, 42 );
assert( i == 3 );La transformée proto::_default n'utilise pas son paramètre d'état, celui-ci est bien présent, mais n'est pas utilisé. Toutefois, il existe une transformée proto::_state pour retourner ce paramètre d'état :
// On utilise le paramètre _state pour extraire le paramètre d'état
proto::_state get_state;
int j = get_state( proto::lit(1) + 2, 42 );
assert( j == 42 );Tout cela peut vous paraître accessoire, mais ce qui suit devrait dissiper vos doutes.
Complément
Dans notre pseudoC++ sans types, la transformée _state s'exprimerait très simplement :
// Equivalent pseudo-C++ de la transformée _state.
auto _state( expr, state = null )
{
return state;
}On constate que _state ne fait d'autre que retourner son second argument.
Dans un complément précédent, je faisais référence à un « emplacement » séparé où figuraient les arguments passés à une lambda. Ça peut encore vous sembler confus, mais c'est en tant que paramètre d'état que cet emplacement sera passé, lors de l'évaluation de l'expression lambda. C'est au moyen de la transformée proto::_state que la routine d'évaluation aura accès aux arguments de la lambda.
VI. Grammaires + transformées = les joies de l'EDSL▲
Dans le dernier article, j'ai utilisé une grammaire pour détecter des expressions invalides et retourner des messages d'erreurs bien utiles. J'ai aussi suggéré qu'on pouvait en faire un meilleur usage. Nous allons maintenant franchir une nouvelle étape en utilisant conjointement des grammaires et des transformées pour définir nos propres évaluateurs d'expressions lambda. En voici la description :
Complément
Avant d'en lire davantage et de vous esquinter les yeux sur l'odieuse syntaxe, il pourrait être utile de décrire par avance la logique de nos transformées dans notre pseudoC++ sans type :
// Du pseudo-C++ pour illustrer l'évaluation d'expressions lambda
auto Lambda( expr, state = null )
{
if ( decltype( expr ) matches? terminal<arg1_tag> )
return _state( expr, state )
else
return _default( expr, state, Lambda )
}Dans le pseudoC++ ci-dessus, j'ai introduit un nouvel opérateur que j'ai appelé matches? qui agit non pas sur des valeurs, mais sur des types. Bon, d'accord, mon pseudoC++ n'est pas vraiment « sans type », c'est plus un genre de Haskell où s'utilise l'inférence de types. matches? s'utilisera pour tester à la compilation si un nœud d'expressions correspond à une grammaire. J'insiste sur le fait que matches? agit à la compilation ; la valeur que pourrait prendre expr à l'exécution n'a aucune influence sur le résultat de matches?. La grammaire terminal<arg1_tag> validera n'importe quelle valeur dont le type sera arg1_tag. Si c'est le cas, on appelle la transformée_state, qui nous retourne simplement le paramètre d'état. Sinon, on adopte la solution « par défaut » qui consiste à évaluer les nœuds enfants avec Lambda et à combiner les résultats à la manière classique du C++ : une addition pour un nœud « plus », une soustraction pour un nœud « moins », etc. Comme Lambda est appliquée récursivement, arg1 sera remplacé par le paramètre d'état, où qu'il se trouve dans l'arborescence d'expressions.
Très bien, vous pouvez maintenant poursuivre sans trop de risques votre lecture de la transformée C++ réelle.
// Une grammaire avec transformées intégrées pour évaluer des expressions lambda.
struct Lambda
: proto::or_<
// À l'évaluation d'un placeholder terminal, on retourne l'état.
proto::when< proto::terminal<arg1_tag>, proto::_state >
// Sinon, on choisit la solution par défaut.
, proto::otherwise< proto::_default< Lambda > >
>
{};Parmi les nouveautés, nous avons proto::when et proto::otherwise. Proto::when prend deux paramètres template : une grammaire et une transformée à exécuter si une expression correspond à cette grammaire. Proto::otherwise prend juste une transformée, qu'il exécute quoiqu'il arrive.
Lambda est à la fois une grammaire et un objet-fonction et évalue donc des expressions lambda valides. En tant que grammaire, il lit de cette manière : une expression est un Lambda soit si c'est un terminal arg1_tag (comme arg1), soit dans tous les cas restants. Soyons honnêtes, ce n'est pas une grammaire très intéressante. En tant qu'objet-fonction, Lambda fonctionne de cette manière : pour des terminaux arg1_tag, on retourne l'état courant. Pour tout le reste, on choisit l'action « par défaut » en évaluant récursivement tous les nœuds enfants selon la grammaire Lambda (comme spécifié par le paramètre template Lambda passé à _default), puis en combinant les résultats en utilisant l'opérateur à l'origine du nœud parent.
Complément : pseudoC++ vs C++ réel
Quel rapport y a-t-il entre le code C++ réel, qui peut sembler ésotérique, et le code pseudoC++ beaucoup plus simple et explicite ? En particulier, dans la définition pseudoC++ de Lambda, on voit clairement que des arguments sont transmis, alors que dans la définition C++ réelle de Lambda, il semble qu'aucun argument ne soit transmis. En fait, ils le sont, mais implicitement.
Dans la définition pseudoC++ de Lambda, les transformées _state et _default se font transmettre les paramètres expr et state courants et non modifiés. De la même manière, à l'évaluation du vrai Lambda, Proto connaît à chaque instant les valeurs courantes de expr et state et les transmet à _state et _default. Vous n'avez pas besoin de lui dire de le faire.
Mais qu'est-ce que proto::_state ? C'est une classe qui implémente le protocole result_of de TR1. En vous épargnant les détails, elle ressemble plus ou moins à cela :
// Implémentation approximative de la transformée _state qui
// retourne simplement son second paramètre
struct _state
{
template<class Sig> struct result;
template<class This, class Expr, class State>
struct result<This(Expr, State)>
{
typedef State type;
};
template<class Expr, class State>
State operator()(Expr const & expr, State const & state) const
{
return state;
}
};C'est passablement long, notamment parce que deux « calculs » sont présents : l'un à la compilation qui détermine le type de retour via le type template imbriqué result et l'autre à l'exécution en retournant simplement le second argument. Maintenant que ces deux calculs sont regroupés et désignés par _state, nous pouvons réutiliser ce terme dans nos transformées pour représenter ces calculs de compilation et d'exécution qui permettent de retourner l'état courant.
Et pour revenir à la question initiale, Proto « sait » que le second paramètre de proto::when (et le premier de proto::otherwise) est un objet-fonction de style TR1 qui accepte les paramètres expr et state courants. Donc Proto les transmet sans même que vous le lui demandiez. C'est implicite.
Complément : expressions, grammaires et transformées Pourquoi est-il intéressant de remarquer que Lambda est à la fois une grammaire et un objet-fonction ? Quand il est utilisé en tant qu'objet-fonction, le premier paramètre correspond à l'expression à évaluer. Une grammaire avec des transformées intégrées peut être vue comme un algorithme de traitement d'expressions. La grammaire est utilisée pour contrôler le flux d'exécution au sein de l'algorithme, en utilisant le pattern matching sur les nœuds pour trouver la transformée à appliquer. Ces algorithmes ont une importante précondition : l'expression qui leur est transmise doit correspondre à leur grammaire interne. Par exemple :
// On s'assure à la compilation que l'expression fournie corresponde
// à la grammaire Lambda avant d'appliquer l'algorithme Lambda
static_assert(
proto::matches< decltype(arg1 + 42), Lambda >::value,
"Le type de cette expression DOIT correspondre avec la grammaire Lambda !");
// OK, elle est valide. On l'évalue.
Lambda()( arg1 + 42, 1 );Dans le cas présent, la grammaire Lambda est dégénérée ; en raison de l'utilisation de proto::otherwise, qui n'est pas discriminant, la grammaire correspondra quoiqu'il arrive, mais ce n'est pas toujours le cas.
Une remarque importante concerne aussi la relation qu'entretiennent les expressions, les grammaires et les transformées. En des termes simples, nous pouvons dire :
Expression
Données : aucun comportement intéressant.
Grammaire
Schéma : description de données valides.
Transformée
Fonction : accepte des données et retourne une nouvelle valeur.
Grammaire + Transformée
Algorithme : une procédure pas-à-pas pour appliquer des fonctions aux données qui se conforment au schéma.
J'espère que tout ceci vous semble désormais un peu plus cohérent.
Nous pouvons utiliser Lambda ainsi :
// Évalue l'expression lambda avec 1 en tant qu'état
int k = Lambda()( arg1 + 42, 1 );
assert( k == 43 );À chaque étape de l'évaluation de arg1 + 42 par Lambda, s'opère une correspondance : est-ce que le nœud courant ressemble à un terminal arg1 ? Si oui, on retourne le paramètre d'état. Sinon, on invoque Lambda récursivement sur ses enfants (transmis conjointement à l'état) et on combine les résultats selon les règles des expressions C++. Par exemple :
Lambda()(arg1+42, 1)se développe grosso modo (voir l'encadré ci-dessous) en :
Lambda()(arg1, 1) + Lambda()(42, 1)qui se développe lui-même en 1 + 42 pour aboutir à 43.
En réalité, il se développerait plutôt de cette façon :
Lambda()(arg1, 1) + Lambda()(proto::lit(42), 1)Pourquoi proto::lit ? Lorsque Proto construit des expressions arborescentes, il prend les objets non-Proto tels que 42 pour les convertir en terminaux Proto, avant de les rattacher à l'arborescence. C'est ce terminal d'entier encapsulé qui sera finalement transmis à Lambda, pas l'entier 42 tel quel. Et que fait _default des terminaux ? Il les extrait de l'encapsulation.
VII. À venir▲
Nous avons maintenant un placeholder grâce auquel nous pouvons construire toutes sortes d'expressions lambda, ainsi qu'un évaluateur appelé Lambda pour les évaluer. Ce qui nous manque encore, c'est un operator() qui changera nos expressions lambda en véritables objets-fonctions que nous pourrons passer à des algorithmes standards. Pour ce faire, il nous faudra savoir comment étendre des expressions Proto, mais ça, c'est un tout autre chapitre. Dans la prochaine section, nous reprendrons là où nous nous sommes arrêtés et terminerons cette petite bibliothèque de fonctions lambda. D'ici là…
VIII. Remerciements▲
Merci à Eric Niebler de nous avoir autorisés à traduire Expressive C++: A Lambda Library in 30 Lines (Part 1 of 2).
Merci à Joel F, à Ekleog, à LittleWhite pour leur relecture, à Torgar pour sa relecture orthographique.