



I. Introduction▲
Bienvenue dans ce neuvième article de cette série d'articles que j'écris, le « Programme d'étude sur le C++ bas niveau ». Cela fait longtemps depuis le huitième article (plus de temps que je pensais même), je ne peux que m'en excuser pour. Mon fils de trois ans a cessé de faire la sieste dans l'après-midi à la fin avril et cela a totalement ruiné ma productivité…
Cet article les trois constructions de boucles while, do-while et for et aussi la boucle manuelle if-goto (de la vieille école !). Comme d'habitude, nous allons regarder en détail à quoi ressemble le code assembleur généré par le compilateur. Aurais-je oublié de parler de la nouvelle boucle range-based-for introduite dans le standard C++11 standard ? Non bien sûr. Si vous utilisez un compilateur conforme avec C++11, vous êtes plus que bienvenu pour le découvrir par vous-même, vous n'avez qu'à dire que c'est un travail à faire à la maison…
Voici les liens vers les articles précédents de la série (attention : ça peut prendre un peu de temps, les premiers sont assez longs) :
- Programme d'étude sur le C++ bas niveau ;
- Programme d'étude sur le C++ bas niveau n° 2 : les types de données ;
- Programme d'étude sur le C++ bas niveau n° 3 : la Pile ;
- Programme d'étude sur le C++ bas niveau n° 4 : plus de Pile ;
- Programme d'étude sur le C++ bas niveau n° 5 : encore plus de Pile ;
- Programme d'étude sur le C++ bas niveau n° 6 : les conditions ;
- Programme d'étude sur le C++ bas niveau n° 7 : les conditions (suite) ;
- Programme d'étude sur le C++ bas niveau n° 8 : l'assembleur optimisé.
II. Une courte histoire des boucles▲
Il m'est apparu qu'un ordre logique pour couvrir les structures de boucles du langage C/C++ pourrait être de les traiter dans l'ordre dans lequel elles ont été introduites dans le langage.
Il y a quelques années, un ami m'a montré un site Web brillant et un article qui parle de l'évolution du langage de programmation C. C'était très intéressant et, de ce que je me souviens, il présentait l'ordre dans lequel les différentes fonctionnalités du compilateur C ont été ajoutées, y compris la construction de boucles qui est venu en premier. J'ai essayé de le retrouver sur Internet, mais j'ai échoué. N'hésitez pas à me fournir le lien si vous savez où il est…
Comme je ne peux pas retrouver l'article et le site Web en question, j'ai décidé de les couvrir dans l'ordre de la quantité de travail qu'elles font automatiquement pour le développeur. À mon avis, cet ordre est : if-goto, while, do-while et enfin for.
Cela me semble être un ordre logique pour deux raisons : d'abord parce que c'est susceptible d'être l'ordre dans lequel elles ont été introduites dans les langages de programmation et d'autre part parce que les concepts encapsulés par construction s'appuient les uns sur les autres et dans cet ordre.
III. if-goto▲
De nos excursions précédentes dans le pays de l'assembleur, nous sommes déjà habitués au concept de sauter l'adresse d'exécution et avec le concept de « saut conditionnel » (c'est-à-dire de changement conditionnel de l'adresse d'exécution). Le moyen le plus direct pour sauter l'exécution d'un morceau de code plusieurs fois (par opposition à la plus simple qui consiste à recopier le code) est d'utiliser les mots-clés de haut niveau qui correspondent à ces concepts du niveau assembleur.
Nous sommes déjà familiarisés avec le mot-clé « if », mais nous n'avons pas vraiment parlé de « goto », peut-être le plus décrié de toutes les fonctionnalités de langage de C/C++, et probablement le plus interdit par les normes de codage des compagnies.
Personnellement, je ne pense pas que « goto » soit intrinsèquement plus dangereux que (par exemple) la surcharge d'opérateur, mais, le but de cet article n'est pas de discuter de « goto », si vous êtes intéressés, voici la page de Wikipédia qui contient une grande quantité de détails (et des liens) sur les arguments pour et contre.
Le but de cet article n'étant pas de discuter le bien-fondé de « goto », ou d'ailleurs la surcharge d'opérateur, nous allons donc passer à autre chose.
Voici le premier morceau de code (voir l'article précédent sur la façon de mettre en place un projet qui va tout simplement accepter ce code…) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
#include "stdafx.h"
#define ARRAY_SIZE(array) (sizeof(array)/sizeof(array[0]))
int main(int argc, char* argv[])
{
int k_aiData[] = { 1, 2, 3, 4, 5, 6, 7, 8 };
int iSum = 0;
int iLoop = 0;
LoopStart:
if( iLoop < ARRAY_SIZE(k_aiData) )
{
iSum += k_aiData[ iLoop ];
++iLoop;
goto LoopStart;
}
return 0;
}
Vous devriez être capable de voir que ce code fait simplement une boucle sur les valeurs du tableau k_aiData en les sommant, plus que l'utilisation de « goto » et « if », c'est essentiellement une boucle standard pour parcourir un tableau.
La macro du préprocesseur ARRAY_SIZE que j'utilise ici est un moyen simple de faire moins d'erreurs avec des tableaux alloués statiquement. Essentiellement nous aurions pu initialiser le tableau k_aiData avec le nombre d'éléments désiré et le reste du code fonctionnerait encore. Il existe des moyens simples d'y parvenir d'une manière sûre en utilisant des templates, mais j'ai choisi d'utiliser une macro ici, car une version lisible du code prend moins de place que la version avec templates.
Si vous vous demandez pourquoi je ne fais pas d'incrémentation de iLoop à l'intérieur des crochets, c'est pour que le code de haut niveau qui fait le travail de la boucle soit identique dans tous les extraits de code.
Si vous vous demandez aussi pourquoi j'utilise la version préfixée au lieu de la version postfixée de l'opérateur ++, alors bravo, je vous attribue 6,29 points d'attention. Dans ce cas, il n'y a aucune différence au niveau de l'assembleur généré, mais en ces jours de surcharge d'opérateur, il est généralement préférable d'utiliser la version préfixée comme une bonne pratique, à moins bien sûr que vous n'ayez besoin d'un comportement postfixé (le premier commentaire à la première réponse à cette question sur Stack Overflow devrait vous apporter la lumière, si vous ne savez pas quelles sont les conséquences de ces comportements différents).
Comme nous utilisons deux mots-clés qui ont une relation très claire avec les concepts de niveau assembleur, il est raisonnable de supposer que le désassemblage de ce code sera à peu près le même que celui écrit à un niveau élevé. Mais comme nous le savons tous, nous ne devons jamais supposer, donc nous allons vérifier nos hypothèses.
Voici le désassemblage du code debug x86 pour la partie de la boucle :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
11: LoopStart:
12: if( iLoop < ARRAY_SIZE(k_aiData) )
00BB1299 cmp dword ptr [ebp-2Ch],8
00BB129D jae LoopStart+1Eh (0BB12B7h)
13: {
14: iSum += k_aiData[ iLoop ];
00BB129F mov eax,dword ptr [ebp-2Ch]
00BB12A2 mov ecx,dword ptr [ebp-28h]
00BB12A5 add ecx,dword ptr [ebp+eax*4-24h]
00BB12A9 mov dword ptr [ebp-28h],ecx
15: ++iLoop;
00BB12AC mov eax,dword ptr [ebp-2Ch]
00BB12AF add eax,1
00BB12B2 mov dword ptr [ebp-2Ch],eax
16: goto LoopStart;
00BB12B5 jmp LoopStart (0BB1299h)
17: }
18:
19: return 0;
00BB12B7 xor eax,eax
Comme prévu, le désassemblage est très simple et vous devez être familiarisé avec la quasi-totalité de celui-ci en lisant les articles précédents.
Comme nous l'avons vu dans le premier article sur les conditions, le code assembleur (lignes 3 et 4) qui correspond au if (ligne 2) teste l'opposé logique du code de haut niveau. C'est parce qu'au niveau élevé, conceptuellement le if entre dans les accolades qu'il contrôle si le test est réussi, alors que l'ensemble doit sauter le code assembleur généré par le contenu de l'instruction if afin de ne pas l'exécuter (rappelez-vous, les accolades sont une commodité de haut niveau pour les programmeurs !).
Dans ce cas, la ligne 3 compare iLoop (à l'adresse [ebp-2Ch]) avec 8 (la taille du tableau obtenue avec ARRAY_SIZE est une constante de compilation) et (ligne 4) utilise jae (saut si supérieur ou égal) pour sauter conditionnellement l'exécution à LoopStart + 1Eh (0BB12B7h), qui est l'adresse mémoire immédiatement après l'assembleur généré par le contenu des accolades contrôlé par l'instruction if.
Le bloc suivant d'assembleur ajoute l'élément iLoop-ème de k_aiData à Isum. À ce stade, nous devrions tous être familiarisés avec l'assembleur pour additionner deux nombres entiers et la manière dont les éléments de k_aiData sont accédés est la seule véritable nouveauté dans le code assembleur que nous voyons.
L'instruction qui accède au iLoop-ème élément de la table est constitué d'une quantité surprenante de travail pour une simple instruction assembleur et c'est certainement la première fois que nous voyons un calcul important en cours dans une seule ligne de code assembleur et tout cela survient dans les crochets qui contiennent l'adresse de la valeur à laquelle on souhaite accéder.
Aussi, regardons en détail :
add ecx,dword ptr [ebp+eax*4-24h]Lorsque la ligne 9 est exécutée, le registre eax contient la valeur de iLoop et [ebp-24h] est l'adresse du tableau k_aiData.
Comme k_aiData est un tableau d'entiers, l'adresse de k_aiData[0] est [ebp-24h] et sizeof (int) vaut 4 sur les architectures x86, il devrait être assez évident que le calcul [ebp + eax * 4-24h] sur ligne 9 correspond à l'adresse de mémoire du iLoop-ème élément de k_aiData.
Si vous avez des difficultés à le voir, voici le calcul d'adresse vu dans le désassembleur réarrangé par étape afin que nous puissions échanger les registres et les adresses mémoire pour les variables de haut niveau :
-
ebp+eax*4-24h - =
ebp+(eax*4)+(-24h) - =
ebp+(-24h)+(eax*4) - = ( epb
-24h)+(eax*4) - =
&k_aiData[0]+( iLoop*sizeof(int) )
Maintenant que nous avons examiné les nouveaux éléments du désassembleur que nous n'avions pas vu avant, le reste de cet article devrait aller assez vite. ![]()
Ainsi, après que la valeur stockée dans le iLoop-ème élément de k_aiData a été ajoutée à Isum, tout ce qui reste est ++iLoop (lignes 12-14) et ensuite revenir à l'étiquette en début de la boucle (ligne 16).
Il est clair que cela continuera jusqu'à ce que iLoop>= 8 et ainsi nous pouvons voir que l'assemblage est isomorphe avec le code de haut niveau.
III-A. Pourquoi ajouter d'autres types de boucles ?▲
Puisque le comportement en boucle peut simplement être obtenu en utilisant le if-goto, cela soulève la question suivante : « Pourquoi Dennis Ritchie (malheureusement plus parmi nous) nous embête avec les autres constructions de boucles disponibles avec le C ? »
Il y a trois raisons principales qui me viennent à l'esprit, la première est l'efficacité (de saisie plutôt que d'exécution), la seconde est la robustesse, et la troisième est la clarté d'intention.
Écrire une boucle en utilisant l'idiome if-goto implique une bonne dose de saisie et les boucles sont très communes dans la plupart des codes de base. Personne n'aime à taper plus que nécessaire, en particulier les programmeurs. Étant donné que les programmeurs utilisant le langage étaient probablement les programmeurs à l'origine de ce langage, il était plus ou moins inévitable qu'une méthode plus textuellement laconique de l'écriture des boucles devait arriver.
Deuxièmement, et plus important encore, le code impliqué dans l'écriture des deux morceaux if-goto d'une boucle est très semblable et le faire à la main serait plus sujet à erreur (ainsi que fastidieux) que d'utiliser une construction de code spécialement conçue pour gérer la boucle qui supprime la nécessité d'un goto explicite et son label associé.
Troisièmement, et peut-être plus important encore, une construction explicite en boucle rend l'objet du code beaucoup plus clair. if et goto tous les deux ont beaucoup d'autres utilisations que les boucles et donc n'importe quel programmeur devant lire le code contenant une boucle if-goto devra faire un effort mental important pour se rendre compte que ce code est en fait une boucle, ce qui serait évidemment très mauvais.
Prises ensemble, ces trois raisons font que vous n'aurez presque certainement jamais à écrire une boucle en utilisant if-goto pour toute autre raison que pour le plaisir, et vous ne le ferez certainement pas. La seule raison pour laquelle j'en parle est parce que je pense qu'il vaut la peine de le considérer comme une étape dans l'évolution des structures de boucle des langages.
IV. while▲
Donc, nous commençons avec while. La boucle while est essentiellement une séquence if-goto automatique nous verrons cela quand nous regardons le désassembleur (c'est essentiellement pour cela que j'ai couvert le if-goto en premier lieu).
Voici l'extrait de code mis à niveau pour utiliser while :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
#include "stdafx.h"
#define ARRAY_SIZE(array) (sizeof(array)/sizeof(array[0]))
int main(int argc, char* argv[])
{
int k_aiData[] = { 1, 2, 3, 4, 5, 6, 7, 8 };
int iSum = 0;
int iLoop = 0;
while( iLoop < ARRAY_SIZE(k_aiData) )
{
iSum += k_aiData[ iLoop ];
iLoop++;
}
return 0;
}
Clairement le code de haut niveau semble plus propre déjà et (plus important) les éléments manuels pour mettre le if et le goto dans les bons endroits ont été supprimés de sorte qu'il est plus difficile pour une erreur humaine de faire quelque chose de mal et il est visible immédiatement que le code est une boucle sur le contenu du tableau k_aiData.
Beaucoup mieux - bravo les concepteurs de langages de programmation d'antan !
Maintenant, regardons le désassembleur généré…
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
11: while( iLoop < ARRAY_SIZE(k_aiData) )
013E1299 cmp dword ptr [ebp-2Ch],8
013E129D jae main+77h (13E12B7h)
12: {
13: iSum += k_aiData[ iLoop ];
013E129F mov eax,dword ptr [ebp-2Ch]
013E12A2 mov ecx,dword ptr [ebp-28h]
013E12A5 add ecx,dword ptr [ebp+eax*4-24h]
013E12A9 mov dword ptr [ebp-28h],ecx
14: iLoop++;
013E12AC mov eax,dword ptr [ebp-2Ch]
013E12AF add eax,1
013E12B2 mov dword ptr [ebp-2Ch],eax
15: }
013E12B5 jmp main+59h (13E1299h)
16:
17: return 0;
013E12B7 xor eax,eax
Presque sans surprise, l'assembleur qui a été généré à partir du while est essentiellement identique à celui généré pour le if-goto que nous venons de voir, seules les adresses qui doivent être sautées ont changé.
C'est le genre de chose qui me redonne foi en l'humanité et en particulier les développeurs de compilateur mais ils sont toujours humains. Enfin, je suppose.
V. do-while▲
Passons rapidement sur cet extrait de code pour le prochain type de boucle, le do-while.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
#include "stdafx.h"
#define ARRAY_SIZE(array) (sizeof(array)/sizeof(array[0]))
int main(int argc, char* argv[])
{
int k_aiData[] = { 1, 2, 3, 4, 5, 6, 7, 8 };
int iSum = 0;
int iLoop = 0;
do
{
iSum += k_aiData[ iLoop ];
++iLoop;
}
while( iLoop < ARRAY_SIZE(k_aiData) );
return 0;
}
Essentiellement le même code, mais maintenant, nous testons la condition de sortie de la boucle à la fin de chaque boucle, plutôt qu'au début.
Tout étant sain dans l'univers, je pense qu'il est raisonnable de s'attendre à ce que l'assembleur généré pour ce code soit très similaire aux deux précédentes boucles, sauf que le code du test est susceptible d'être après que le corps de la boucle et non avant elle…
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
11: do
12: {
13: iSum += k_aiData[ iLoop ];
00CC1299 mov eax,dword ptr [ebp-2Ch]
00CC129C mov ecx,dword ptr [ebp-28h]
00CC129F add ecx,dword ptr [ebp+eax*4-24h]
00CC12A3 mov dword ptr [ebp-28h],ecx
14: ++iLoop;
00CC12A6 mov eax,dword ptr [ebp-2Ch]
00CC12A9 add eax,1
00CC12AC mov dword ptr [ebp-2Ch],eax
15: }
16: while( iLoop < ARRAY_SIZE(k_aiData) );
00CC12AF cmp dword ptr [ebp-2Ch],8
00CC12B3 jb main+59h (0CC1299h)
17:
18: return 0;
00CC12B5 xor eax,eax
Comme prévu, puis, le code faisant le travail dans la boucle et l'incrémentation de iLoop est fondamentalement identique.
De plus, comme prévu, le saut conditionnel qui entoure la boucle est un peu différent, il utilise l'instruction de saut jb (sauter si inférieur). Ainsi, contrairement à peu près tout le code assembleur généré par les autres conditions de haut niveau que nous avons regardées, ce test est le même que le code de haut niveau, mais pourquoi ?
Comme indiqué précédemment, le concept de haut niveau du langage de « groupe d'accolades » n'existe pas au niveau de l'assembleur. Malgré cela, le compilateur doit générer du code assembleur qui est logiquement isomorphe avec le code de haut niveau. Ainsi afin de satisfaire la contrainte de haut niveau du comportement « d'entrer dans » le groupe d'accolades si une précondition est remplie, l'assembleur saute le code entre les accolades si la condition n'est pas remplie.
Donc, puisque la condition de la boucle est une postcondition dans une boucle do-while (i.e. à la fin du « groupe d'accolades » qu'il contrôle) le code de haut niveau et le code assembleur ont tous les deux besoin de revenir au début de la boucle si la condition de boucle est remplie, donc le test dans le code assembleur est la même que celui du niveau haut.
VI. for▲
Nous arrivons maintenant à la boucle for, la boucle que vous utiliserez probablement le plus souvent.
La boucle for était la construction de boucle qui a été travaillée le plus pour vous jusqu'à la nouvelle norme ANSI C++11 qui introduit la notion de boucle for sur un intervalle ("range-based" for) au langage l'an dernier (sans compter les solutions à base de modèles). Malheureusement (mais il est évidemment pris en charge dans la dernière version VC2012) le support du standard C++11 est inégal sur la plupart des plates-formes de jeux vidéo de sorte que la boucle for est encore la solution par défaut.
Prenons un instant pour regarder « l'anatomie d'une boucle ». Plus ou moins, tout code qui boucle a trois responsabilités en plus du travail qu'il fait en itérant la boucle :
- déclarer et/ou initialiser les variables d'état de la boucle ;
- tester la condition de sortie de la boucle ;
- mettre à jour les variables d'état pour la boucle suivante.
Ces trois responsabilités définissent l'étendue et les modalités de l'itération de la boucle et de fait, peuvent donc être considérées comme « l'empreinte » de cette itération.
La boucle for est une « factorisation de langage de haut niveau » qui rassemble ces trois responsabilités dans une seule construction en leur donnant de la proximité textuelle, rendant ainsi toute l'empreinte visible en un seul endroit.
Bien que cela soit assez évident quand vous vous arrêtez pour le regarder, l'importance de le dire explicitement ne devrait pas être sous-estimée.
Pourquoi ? Regardons un for comparé à while et remplaçons le code correspondant à a, b ou c dans le code ci-dessous.
2.
3.
4.
for( a; b; c)
{
//do work
}
Par rapport à :
2.
3.
4.
5.
6.
a;
while( b )
{
//do work
c;
}
Ainsi, la boucle for prend moins de place verticalement que while (dans ce cas au moins). Mais quels sont les autres avantages :
- la portée des variables déclarées dans a pour un
forest limitée à la boucle. Moins de portée = moins d'entropie = moins de bogues ; - c'est évidemment distinct du code du travail de la boucle dans le for, mais pas dans le temps (soyez honnête : combien de fois avez-vous accidentellement fait un while infini parce que vous avez oublié d'incrémenter à la fin) ;
- la proximité de a, b et c dans le
forfait que les bogues dans les conditions de la boucle sont mis en évidence plus facilement.
Celui qui a inventé la boucle for mérite une tape dans le dos, parce que for prend les améliorations apportées par les boucles while et do-while en réduisant les erreurs humaines et en augmentant la clarté de l'intention encore plus.
J'ai regardé et il s'avère que le premier équivalent à for que j'ai trouvé sur Google est DO loop in FORTRAN qui a été inventé en 1957 par une équipe dirigée à la fin par John Backus chez IBM. Puisque cette réponse est proche de ma question, je vous invite maintenant à vous joindre à moi pour une salve d'applaudissements, à titre posthume, à John afin de célébrer l'excellent travail de son équipe.
Regardons-en un maintenant, d'accord ? Voici le bout de code :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
#include "stdafx.h"
#define ARRAY_SIZE(array) (sizeof(array)/sizeof(array[0]))
int main(int argc, char* argv[])
{
int k_aiData[] = { 1, 2, 3, 4, 5, 6, 7, 8 };
int iSum = 0;
for( int iLoop = 0; iLoop < ARRAY_SIZE(k_aiData); ++iLoop )
{
iSum += k_aiData[ iLoop ];
}
return 0;
}
... et voici le désassembleur (N.B. j'ai décoché l'option « afficher les noms de symboles » dans les options du désassemblage pour cela…)
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
10: for( int iLoop = 0; iLoop < ARRAY_SIZE(k_aiData); ++iLoop )
00DC1292 mov dword ptr [ebp-2Ch],0
00DC1299 jmp 00DC12A4
00DC129B mov eax,dword ptr [ebp-2Ch]
00DC129E add eax,1
00DC12A1 mov dword ptr [ebp-2Ch],eax
00DC12A4 cmp dword ptr [ebp-2Ch],8
00DC12A8 jae 00DC12B9
11: {
12: iSum += k_aiData[ iLoop ];
00DC12AA mov eax,dword ptr [ebp-2Ch]
00DC12AD mov ecx,dword ptr [ebp-28h]
00DC12B0 add ecx,dword ptr [ebp+eax*4-24h]
00DC12B4 mov dword ptr [ebp-28h],ecx
13: }
00DC12B7 jmp 00DC129B
14:
15: return 0;
00DC12B9 xor eax,eax
Donc… celui-ci est un peu différent, non ? Ce n'est pas très différent, juste réorganisé un peu :
- Lignes 2-3 : c'est l initialisation de iLoop (i.e. [
ebp-2Ch]) à 0 et ensuite un saut au-delà des lignes 4-6 ; - Lignes 4-6 : incrémentation de iLoop ;
- Lignes 7-8 : c'est la comparaison de iLoop avec 8 et la sortie de boucle en sautant à la ligne 19 si iLoop >= 8 (N.B. test précondition donc opposé du haut niveau) ;
- Lignes 11-14 : accès au tableau et somme des valeurs des éléments (cela doit sembler très familier maintenant) ;
- Ligne 16 : retourne à la ligne 4.
Ainsi, l'assembleur dans chacune des étapes 1, 2 et 3 met en œuvre l'une des parties séparées de points-virgules des paramètres de la boucle for. En fait, les étapes 1 à 3 correspondent à a (initialiser), c (incrémenter) et b (condition de sortie de test) respectivement dans le code de notre « anatomie d'une boucle » ci-dessus.
Seules les étapes 1 et 3 sont exécutées lors de la première itération de la boucle et seules les étapes 2 et 3 sont exécutées sur toutes les autres itérations.
Veuillez également noter que les étapes 2 et 3 sont dans l'ordre inverse dans l'assembleur par rapport au code de haut niveau. C'est, encore une fois, la disparité entre finesse de haut niveau et l'exécution du bas niveau.
Ainsi, l'assembleur qui est généré à partir d'une boucle for est plus ou moins comme on pouvait s'y attendre. Nous avons couvert toutes les structures de boucle (non basées sur les modèles et non C++11) maintenant, fin de l'histoire, prochain article. Circulez s'il vous plaît.
VII. Attendez ! Je n'ai pas tout à fait fini !▲
Accrochez-vous ! La raison pour laquelle le dernier article traitait de l'assembleur optimisé est principalement parce que je voulais regarder l'assembleur optimisé généré par le C++ lors de la construction de boucles pour cet article.
Donc, plutôt que de recompiler tous les extraits un par un, nous allons mettre en place un projet, comme dans l'article 8, puis télécharger et coller ce code dans CPPLLC_Part9MoreLoops (copier/coller massif).
Ce fichier contient un programme simple qui possède quatre fonctions en plus du main(). Ce sont :
- SumGoto : additionne les éléments d'un tableau en utilisant une boucle
if-goto; - SumWhile : additionne les éléments d'un tableau en utilisant une boucle
while; - SumDo : additionne les éléments d'un tableau en utilisant une boucle
do-while; - SumFor : additionne les éléments d'un tableau en utilisant une boucle
for.
Tout cela est très simple en réalité. La seule chose inhabituelle que vous remarquerez peut-être est que la fonction main() ressemble à ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
int main( int argc, char* argv[] )
{
// array and a nice const for the size
const int k_iArraySize = 8;
int k_aiData[ k_iArraySize ] = { 0, 1, 2, 3, 4, 5, 6, 7 };
int iSumGoto = SumGoto ( k_aiData, atoi( argv[ 1 ] ) );
int iSumWhile = SumWhile( k_aiData, atoi( argv[ 2 ] ) );
int iSumDo = SumDo ( k_aiData, atoi( argv[ 3 ] ) );
int iSumFor = SumFor ( k_aiData, atoi( argv[ 4 ] ) );
std::cout << iSumGoto << iSumWhile << iSumDo << iSumFor;
return 0;
}
Donc, il prend ces arguments de ligne de commande en entrée et il affiche sur la sortie standard. C'est un moyen relativement simple d'empêcher le compilateur d'optimisation de faire des excès de zèle en supprimant tout le code. Nous forçons l'optimiseur à le conserver en faisant des entrées et des sorties lors de l'exécution.
Avant de compiler et l'exécuter, vous aurez également besoin de faire quelques changements dans les propriétés de votre projet, assurez-vous que vous avez sélectionné l'option de construction en mode « Release »…
La première consiste à passer des arguments en ligne de commande pour le code, en dehors de toute autre raison, ce code est étonnamment naïf et se plante s'il n'obtient pas les arguments qu'il attend, il faut donc ajouter ce qui suit (ce qui fera parcourir entièrement k_aiData pour chaque fonction) :
Nous avons également besoin de désactiver la fonction inline ou sinon, le compilateur va optimiser tous les appels de fonction rendant le désassemblage beaucoup plus difficile à suivre :

Dernière vérification avant lancement : ajouter un point d'arrêt pour le C++ dans chaque boucle qui calcule la somme des éléments (par exemple, « Isum += xxxx »), et nous voilà partis !
VIII. L'heure du désassembleur optimisé !▲
Générez et exécutez le code et vous devriez parvenir avec le débogueur qui s'arrête sur le point d'arrêt que vous avez mis en SumGoto.
Faites un clic droit et choisissez l'option « Go To Disassembly », vous devriez voir quelque chose comme l'image ci-dessous. Mais avant que nous la regardions en détail, un bref aparté est nécessaire :
Le code dans main qui appelle SumGoto ressemble à ceci :
2.
3.
00DB191A push eax
00DB191B lea esi,[ebp-24h]
00DB191E call SumGoto (0DB1880h)
eax (qui contient k_iArraysize) est empilé sur la Pile, mais l'adresse de k_aiData[0] (qui est stockée dans [ebp-24h]) est stockée dans esi plutôt qu'empilée sur la Pile.
Attendez ! Je vous entends déjà dire : « Qu'est-ce qu'ils fabriquent ? Je croyais que nous avions déjà couvert les conventions d'appel et personne ne nous a rien dit sur l'utilisation de esi pour le passage de paramètres ! »
Ne vous inquiétez pas pour le moment, simplement acceptez que, pour une raison quelconque, dans ce cas, l'adresse de k_aiData[0] est transmise via le registre esi (je détaille ceci dans l'épilogue de cet article si vous êtes vraiment intéressé).
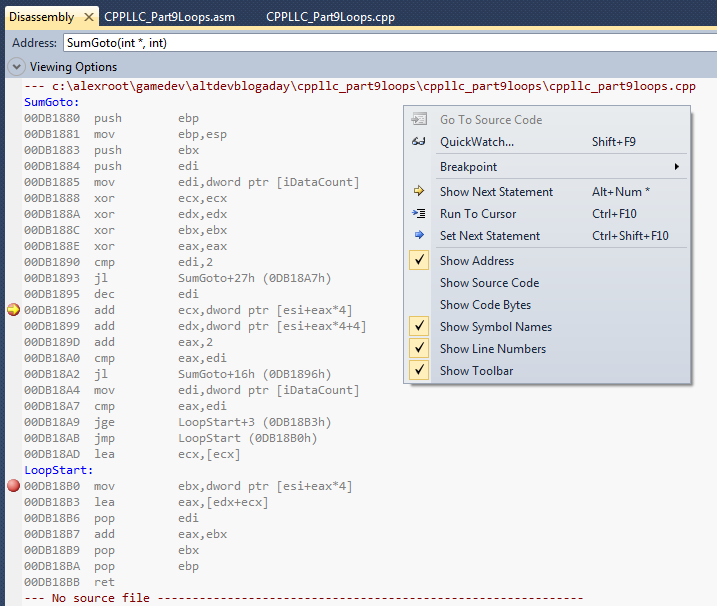
Donc, voici le désassembleur pour SumGoto :
Assurez-vous que vous avez coché les mêmes options d'affichage dans le menu contextuel ou alors votre désassembleur sera peut-être très différent !
Fait intéressant, il y a peu de relations visibles avec le désassembleur du if-goto que nous avons examiné plus tôt. Donc, nous allons le prendre à part pour voir ce qu'il fait différemment :
- 00DB1880 à 00DB1884 : prologue de la fonction SumGoto ;
- 00DB1885 : recopie du paramètre de la fonction iDataCount (le nombre d'itérations) dans le registre
edi; - 00DB1888 à 00DB188E : initialisation des registres
ecx,edx,ebxeteaxà 0 (n'importe quoi XOR lui-même fait 0) ; - 00DB1890 à 00DB1893 : compare
edi(nombre d'itérations restant) avec 2. Si plus petit, saute en 00DB18A7 (deuxième instruction en 9) sinon, continue ; - 00DB1895 : une nouvelle instruction assembleur,
decdécrémente le registre spécifié de 1, dans ce casedi(iDataCount) ; - 00DB1896 à 00DB1899 : nous savons que l'adresse de k_aiData[
0] est dansesi, donc du calcul de l'adresse entre crochets, il est assez évident que ces deux lignes sont l'indexation de k_aiData en additionnant les éléments pairs et impairs dansedxetecxrespectivement ; - 00DB189D : incrémente eax de 2. Clairement,
eaxcontient le nombre d'éléments qui ont été parcourus jusqu'à présent parce que… - 00DB18A0 à ooDB18A2 : … compare
eaxavecedi. Sieax<edil'exécution retourne à l'étape 6 ; - 00DB18A4 à 00DB18AB : ceci est lié à la décrémentation de edi faite à l'étape 5. Comme le code boucle et additionne deux éléments à la fois, ce code vérifie si iDataCount était pair ou impair. Si impair, il passe à l'étape 11, si pair il passe à l'étape 12 ;
- 00DB18AD : laisse ecx inchangé. À quoi cela sert-il ? Il s'agit essentiellement d'une instruction nop (pas d'opération). Les instructions nop sont utilisées dans le code assembleur pour diverses raisons telles que le maintien de l'alignement de la mémoire pour certaines instructions (à ce stade, la première réponse à cette question sur Stack Overflow l'explique suffisamment pour nos besoins). Dans tous les cas, les deux chemins de code possibles grâce à l'étape 9 vont sauter cette instruction ;
- 00DB18B0 : si iDataCount est impair, ce code recopie (
mov) la valeur de l'élément du tableau qui aurait été oublié en itérant deux éléments à la fois dansebx; - 00DB18B3 : ici, on utilise lea pour ajouter les sommes des éléments pairs et impairs de k_aiData qui ont été additionnés dans edx et ecx pour les stocker dans eax rappelez-vous, eax est utilisé pour retourner des valeurs entières de fonctions) ;
- 00DB18B6 : c'est en fait le début de l'épilogue de SumGoto, restaurer
ediavec la valeur qu'il avait avant l'appel à SumGoto. Il n'y a aucune raison particulière pour que cela ait été mis avant l'instruction suivante. Les compilateurs d'optimisation font ce genre de chose assez souvent et aussi longtemps que le code généré est correct, ce n'est pas la peine de trop s'en inquiéter ; - 00DB18B7 : cette ligne ajoute la valeur de ebx (voir étape 11) à la somme qui doit être retourné dans
eax; - 00DB18B9 à 00DB18BB : épilogue de la fonction SumGoto.
Ouch. Cela semble beaucoup plus complexe que le code assembleur de la boucle if-goto. Vous pourriez relire ces lignes à plusieurs reprises avant de répondre sur la manière dont cela fonctionne. Je vous recommande de la faire en pas à pas dans le débogueur en regardant les registres dans une fenêtre de surveillance.
Assez étonnamment, SumWhile et SumFor ressemblent assez à SumGoto mais SumDo est beaucoup plus simple :
2.
3.
4.
5.
6.
7.
8.
SumDo:
00DB1830 xor eax,eax
00DB1832 xor ecx,ecx
00DB1834 add eax,dword ptr [esi+ecx*4]
00DB1837 inc ecx
00DB1838 cmp ecx,edx
00DB183A jl SumDo+4 (0DB1834h)
00DB183C ret
C'est incroyablement simple à suivre et intuitivement beaucoup plus le genre de chose à laquelle on s'attend à voir pour toutes les constructions en boucle, mais il y a l'apparente folie de la méthode du compilateur…
La somme de deux éléments par itération de la boucle, comme l'assembleur de SumGoto, SumWhile et SumFor le font, est en fait une forme de déroulage de boucles. Bien que (dans ce code) le compilateur ne sache pas combien d'itérations de la boucle il va faire, il peut encore améliorer l'ensemble des « instructions de bouclage et instructions de travail » de la boucle en ce déroulement en paires. Sur une table suffisamment grande, il devrait être plus rapide qu'un code qui n'est pas construit de la même façon.
En changeant les options de compilation (sous C/C++ -> Optimisation) de « Maximize Speed (/02) »à« Minimize Size (/01) », vous pouvez générer un assembleur qui ressemble beaucoup plus à ce que vous attendez. Comme /02 est la valeur par défaut pour la compilation en mode « release » sous Visual Studio 2010, je devrais expliquer cet assembleur et je vous laisse la recherche à l'assembleur généré par /01 comme un exercice pour vous, chers lecteurs ![]()
IX. Conclusions▲
Donc, nous y sommes. La construction de boucles et le goût authentique des différences entre les assembleurs optimisés et de débogage bien que dans un scénario grandement simplifié par rapport à un vrai code.
Que devons-nous en tirer ? Eh bien, je suppose avant tout l'intérêt de démontrer que, si le compilateur d'optimisation est contraint de générer du code assembleur qui est isomorphe avec votre code de haut niveau, il ne faut jamais tenir pour acquis que le code qu'il génère sera de la manière à laquelle vous vous attendez.
Cela devrait, je pense, clôture les aspects du contrôle du programme et les aspects structurels de C/ C++ pour nous laisser libres de regarder la façon dont d'autres mécanismes du langage fonctionnent au niveau de l'assembleur.
Je pense qu'il pourrait y avoir éventuellement un article sur la boucle for « range based » et sur la récursivité, mais nous verrons. N'hésitez pas à laisser un commentaire si vous pensez qu'il y a quelque chose flagrante que j'ai laissée de côté et j'essayerai d'y remédier avant de passer à…
Enfin, un grand merci à tous les AltDevAuthors qui m'ont abreuvé de conseils judicieux pour cet article, Tony, Paul, Ted, Bruce, Ignacio, et Rich.
X. Épilogue▲
X-A. Notes sur [ebp+eax*4-XXh]▲
Bien que ce mode d'adressage semble magique, il y a des limites sur les calculs qui peuvent être effectués de cette façon à l'intérieur des crochets, voir cet article sur Wikipédia pour un résumé des limites.
Indépendamment de cela, il est communément utilisé en conjonction avec une autre instruction assembleur x86 appelée lea (load effective address) (comme on peut le voir dans l'assembleur optimisé de SumGoto) qui va charger le résultat du calcul d'adresse (au lieu de la valeur à cette adresse) dans un registre spécifique.
Quand j'ai vu le mnémonique lea dans la fenêtre de désassembleur, il a le plus souvent été utilisé à cette fin mais il ne faut pas supposer que c'est toujours vrai ! Étant donné que nous ne sommes pas (nécessairement) des programmeurs en assembleur, nous n'avons pas besoin de trop nous en inquiéter, mais j'ai pensé utile d'en parler.
X-B. Note au sujet de l'usage de esi pour passer des paramètres aux fonctions▲
Donc, ce n'est certainement pas ce à quoi nous nous attendions compte tenu de la couverture des conventions d'appel que nous avons faite plus tôt dans la série.
J'ai recherché sur Google pendant au moins dix minutes (ce n'est pas exhaustif, mais en général, c'est assez long pour trouver une piste de réponse) et je n'ai pu trouver d'information précise sur l'utilisation de esi pour passer des paramètres dans une convention d'appel documenté. Par contre, j'ai trouvé d'autres personnes qui avaient observé ce comportement et qui cherchaient des réponses à ce sujet.
Donc, dans un esprit de découverte, j'ai décidé de voir ce se passait si je compilais les fonctions de boucle (SumGoto, SumWhile, Sumdo, et SumFor) dans une bibliothèque séparée et ensuite se lier à cette bibliothèque à l'intérieur de l'unité logique de compilation logique de main. Comme prévu, cela règle le passage de paramètres de façon à ce qu'il soit conforme à la convention d'appel cdecl, pas d'utilisation plus dingue de esi pour passer le tableau.
Que conclure de cela, alors ? Eh bien, il semble que si le compilateur sait que le code n'est pas dans une bibliothèque (ou si vous avez l'option de génération Link Time Code Generation activée) et qu'ainsi le code a besoin d'être conforme à des conventions d'appel locales de l'exécutable, alors le compilateur prend des libertés avec les conventions d'appel afin d'optimiser le passage de paramètres aux fonctions. Voici quelques liens de Bruce sur la question : à partir de MSDN (il en parle, mais rien de précis) et de StackOverflow.
Pour avoir le dernier mot : si quelque chose n'a pas de sens lorsque vous déboguez, ne tenez rien pour acquis, prenez votre chapeau de Sherlock Holmes.
X-C. Une note finale au sujet de la genèse des boucles▲
J'ai déjà mentionné que je ne trouvais pas la page sur l'histoire de C que je cherchais, je ne peux donc pas dire avec certitude dans quel ordre les différentes constructions de boucles ont été effectivement ajoutées à la langue.
Cependant, dans mes recherches j'ai trouvé cette intéressante pépite sur Stack Exchange concernant l'histoire des boucles. Mon sentiment personnel sur cette question est que celui qui a inventé la première fois la notion de Sigma en notation mathématique est probablement le père (ou la mère) des boucles en programmation, mais celui qui a inventé le tricot est le véritable auteur;)
XI. Remerciements▲
Cet article est la traduction de l'article « C/C++ Low Level Curriculum Part 9: Loops » écrit en anglais par Alex Darby. Alex Darby a aimablement autorisé l'équipe C/C++ de Developpez.com à traduire et diffuser son article en français.
Je tiens à remercier Bousk pour la relecture technique ainsi que ClaudeLELOUP pour la relecture orthographique de cette traduction.