



I. Introduction▲
Enfin un instant où j'ai réussi à trouver quelques heures libres pour diffuser un nouvel article sur le programme d'études de bas niveau. Ceci est le huitième de la série, ce qui n'est pas très significatif sauf que j'aime le chiffre 8. En plus d'être une puissance de deux, c'est aussi le nombre maximum de personnes non armées qui peuvent se rapprocher suffisamment de vous pour vous attaquer (selon un livre d'arts martiaux que j'ai lu une fois).
Cet article montre comment configurer Visual Studio pour vous permettre de regarder facilement le code assembleur optimisé généré par des codes simples comme les exemples que nous utilisons dans cette série. Si vous vous demandez pourquoi je pense que cela justifie un article à part entière, voici la raison - les optimiseurs des compilateurs sont bons et compte tenu du code avec des constantes en entrée et pas de sortie (comme les exemples que je donne dans cette série), l'optimiseur du compilateur réduit généralement le code à néant - ce que je trouve, le rend assez difficile à regarder. Cet article devrait s'avérer très utile, à la fois pour s'y référer et aussi pour votre propre expérience.
Voici les liens sur les articles précédents de cette série au cas où vous voudriez vous y référer (attention : les premiers sont assez longs) :
- Programme d'étude sur le C++ bas niveau ;
- Programme d'étude sur le C++ bas niveau n° 2 : les types de données ;
- Programme d'étude sur le C++ bas niveau n° 3 : la Pile ;
- Programme d'étude sur le C++ bas niveau n° 4 : plus de Pile ;
- Programme d'étude sur le C++ bas niveau n° 5 : encore plus de Pile ;
- Programme d'étude sur le C++ bas niveau n° 6 : les conditions ;
- Programme d'étude sur le C++ bas niveau n° 7 : les conditions (suite).
II. Hypothèses▲
Strictement parlant, cher lecteur, je fais des tonnes d'hypothèses sur vous pendant que j'écris ceci - que vous lisez l'anglais, que vous aimez la programmation, etc. Mais nous y passerions la journée si je tentais de les lister, donc tâchons de s'en tenir à celles qui vous poseront un problème immédiat si elles étaient incorrectes.
Je vais supposer que vous avez accès à un Visual Studio 2010 sur un ordinateur Windows et que vous êtes familiarisé avec son utilisation pour faire toutes les choses habituelles comme le changement de la configuration, l'ouverture de fichiers, l'édition, la compilation, l'exécution et le débogage en C/C++.
III. Créer un projet▲
Ouvrez Visual Studio et dans le menu choisissez l'option « File -> New -> Project… ».
Une fois que la fenêtre de l'assistant de création d'un nouveau projet s'ouvre (voir ci-dessous) :
- allez dans l'arborescence sur la gauche de la fenêtre et sélectionnez « Other Languages -> Visual C++ » ;
- dans le panneau principal, sélectionnez « Win32 Console Application Visual C++ » ;
- donnez-lui un nom dans la zone de texte « Name : » ;
- sélectionnez l'emplacement de votre choix sur votre PC ;
- cliquez sur OK pour créer le projet.

Une fois que vous avez cliqué sur OK, cliquez sur « Finish » à la prochaine étape de l'assistant - au cas où vous vous poseriez la question, les options disponibles lorsque vous cliquez sur « Next » n'ont pas d'importance pour nos besoins (et décochez là, l'option « Precompiled header » ne fait aucune différence, il génère toujours une application console qui utilise un en-tête précompilé…).
IV. Modifier les propriétés du projet▲
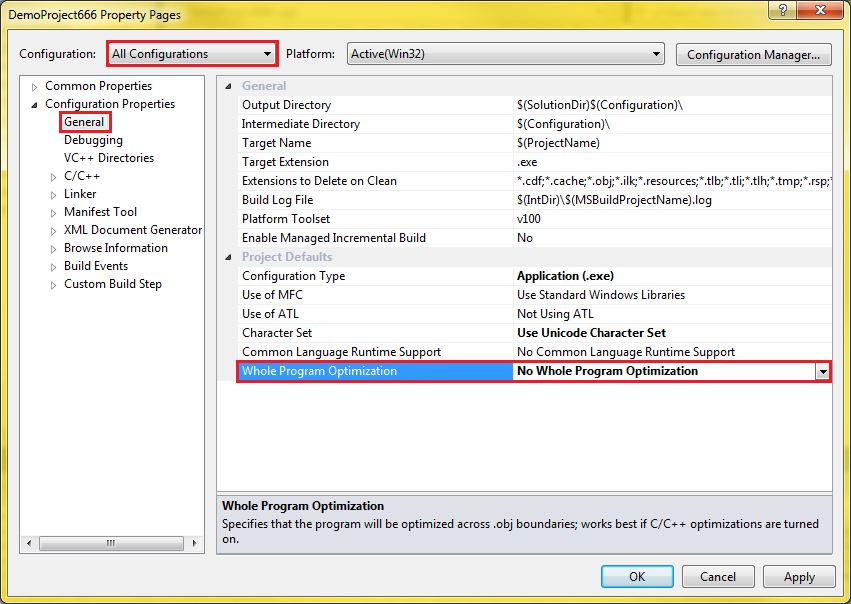
L'étape suivante consiste à utiliser le menu pour sélectionner l'option « Project -> <YourProjectName> Properties » qui fait apparaître la boîte de dialogue des propriétés du projet.
- sélectionnez « All Configurations » dans la liste déroulante « Configuration » ;
- sélectionnez « Configuration Properties ->General » dans l'arborescence à gauche de la fenêtre ;
- dans le panneau principal modifiez l'option « Whole Program Optimisation » pour y mettre la valeur « No Whole Program Optimisation ».
Ensuite, dans l'arborescence (voir image ci-dessous) :
- dans l'arborescence, accédez à « C/C++ -> Code Generation » ;
- dans le panneau principal, changez « Basic Runtime Checks » et mettez la valeur « Default » (c'est-à-dire « off »).

Enfin (voir image ci-dessous) :
- dans l'arborescence, allez dans « C/C++ -> Output Files » ;
- dans le panneau principal, modifiez « Assembler Output » pour « Assembly With Source Code /(FAs) » ;
- une fois que vous avez terminé, cliquez sur « OK ».

Maintenant, lorsque vous compilez, le compilateur Visual Studio génère un fichier « .asm » ainsi qu'un fichier « .exe ». Ce fichier « .asm » contient le code assembleur intermédiaire généré par le compilateur, le code source étant inséré en ligne comme des commentaires.
Vous pouvez également choisir l'option « Assembly, Machine Code and Source (/FAcs) » si vous le souhaitez, cela va générer un fichier « .cod » qui contient le code machine ainsi que l'assembleur et le code source.
Je préfère le fichier « .asm » standard, car il est visuellement moins lourd et les mnémoniques assembleurs sont tous alignés sur la même colonne, c'est ce que je vais supposer que vous utilisez si vous suivez l'article, mais le fichier « .cod » est très bien aussi.
V. Bien, qu'avons-nous fait jusqu'ici ?▲
Eh bien, tout d'abord nous avons supprimé l'optimisation de l'édition de lien. Entre autres choses, cela permet d'éviter à l'éditeur de liens de supprimer dans le fichier « .asm » les fonctions qui sont compilées, mais jamais appelées.
Deuxièmement, nous avons désactivé les contrôles d'exécution de base (qui sont déjà désactivés dans la version release). Ces vérifications permettent aux prologues et épilogues des fonctions générées de faire d'importantes quantités de contrôles (fondamentalement non nécessaires). Ces contrôles supplémentaires provoquent un temps d'exécution dans les pires des cas cinq fois plus long (voir cet article de Bruce Dawson sur son blog personnel pour une explication détaillée).
Enfin, nous avons demandé au compilateur de ne pas effacer le code assembleur intermédiaire qu'il génère pour notre programme. Ces données sont produites par le processus de compilation lorsque vous compilez, mais elles sont généralement effacées, nous demandons simplement à Visual Studio de créer un fichier « .asm », afin que nous puissions y jeter un coup d'œil.
Comme nous avons fait ces changements pour « All Configurations », cela signifie que nous aurons accès au fichier « .asm » contenant le code assembleur généré à la fois pour la version debug mais aussi pour la version release.
VI. Essayons▲
Donc, dans un esprit de découverte, nous allons essayer (afin de nous familiariser) une fonctionnalité du langage que nous avons examinée la dernière fois - l'opérateur conditionnel :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
#include "stdafx.h"
int ConditionalTest( bool bFlag, int iOnTrue, int iOnFalse )
{
return ( bFlag ? iOnTrue : iOnFalse );
}
int main(int argc, char* argv[])
{
int a = 1, b = 2;
bool bFlag = false;
int c = ConditionalTest( bFlag, a, b );
return 0;
}
La question que vous avez en tête en ce moment doit être « pourquoi avons-nous mis le code dans une fonction ? ». Soyez assuré que nous en reparlerons bientôt.
Maintenant, nous devons construire le code et le regarder dans les fichiers « .asm » générés pour voir ce qu'a fait le compilateur…
D'abord, construire la version debug - qui devrait être déjà sélectionnée dans la liste déroulante de la solution (en haut de votre fenêtre de Visual Studio, sauf si vous l'avez déplacée).
Ensuite, construire la configuration release.
Maintenant, nous devons ouvrir les fichiers « .asm ». À moins que vous n'ayez modifié des propriétés du projet que je ne vous ai pas indiquées, ces fichiers seront dans les chemins suivants :
- <Chemin du projet >/Debug/<Nom du projet>.asm ;
- <Chemin du projet >/Release/<Nom du projet>.asm.
VII. Les fichiers « .asm »▲
Je ne vais pas entrer ici dans les détails de façon significative sur le format des fichiers « .asm », si vous voulez en savoir plus, voici un lien vers la documentation de Microsoft pour leur assembleur.
La principale chose que vous devez savoir, c'est que nous pouvons trouver les fonctions C/C++ dans le fichier « .asm » en les recherchant par leur nom et que, une fois que nous les avons trouvés, le mélange de code source et de code assembleur ressemble fondamentalement à ce qui est fait dans la vue désassembleur du débogueur de Visual Studio.
VIII. La fonction main()▲
Regardons tout d'abord la fonction main(). C'est là que j'explique pourquoi l'extrait de code que nous voulions examiner a été mis en fonction. Vous êtes tout excité !
Voici la fonction main() du fichier « .asm » de la version debug (je l'ai légèrement remis en forme pour qu'il prenne moins de place verticalement) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
_TEXT SEGMENT
_c$ = -16 ; size = 4
_bFlag$ = -9 ; size = 1
_b$ = -8 ; size = 4
_a$ = -4 ; size = 4
_argc$ = 8 ; size = 4
_argv$ = 12 ; size = 4
_main PROC ; COMDAT
; 9 : {
push ebp
mov ebp, esp
sub esp, 80 ; 00000050H
push ebx
push esi
push edi
; 10 : int a = 1, b = 2;
mov DWORD PTR _a$[ebp], 1
mov DWORD PTR _b$[ebp], 2
; 11 : bool bFlag = false;
mov BYTE PTR _bFlag$[ebp], 0
; 12 : int c = ConditionalTest( bFlag, a, b );
mov eax, DWORD PTR _b$[ebp]
push eax
mov ecx, DWORD PTR _a$[ebp]
push ecx
movzx edx, BYTE PTR _bFlag$[ebp]
push edx
call ?ConditionalTest@@YAH_NHH@Z ; ConditionalTest
add esp, 12 ; 0000000cH
mov DWORD PTR _c$[ebp], eax
; 13 : return 0;
xor eax, eax
; 14 : }
pop edi
pop esi
pop ebx
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS
Si vous avez lu les articles précédents, cela doit vous sembler assez familier.
Cela se décompose comme suit :
- lignes 1-8 : ces lignes définissent les décalages par rapport à [ebp] des différentes variables dans le « Stack Frame » à l'intérieur de la fonction main() ;
- lignes 10-15 : le prologue de la fonction main() ;
- lignes 17-20 : initialisation des variables dans la Pile ;
- lignes 22-30 : empile les paramètres de la fonction ConditionalTest() sur la Pile, appel de la fonction et récupération de la valeur de retour ;
- ligne 32 : mise en place de la valeur de retour de la fonction main() ;
- lignes 34-38 : épilogue de la fonction main() ;
- ligne 39: fin de la fonction main().
Il n'y a rien de vraiment inattendu, la seule chose nouvelle est la déclaration des variables locales dans la Pile à partie de [ebp].
J'ai l'impression que cela rend le code assembleur plus facile à suivre que le code dans la fenêtre de désassemblage du débogueur Visual Studio.
Et, à titre de comparaison, voici la fonction main() pour la version release :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
_TEXT SEGMENT
_argc$ = 8 ; size = 4
_argv$ = 12 ; size = 4
_main PROC ; COMDAT
; 10 : int a = 1, b = 2;
; 11 : bool bFlag = false;
; 12 : int c = ConditionalTest( bFlag, a, b );
; 13 : return 0;
xor eax, eax
; 14 : }
ret 0
_main ENDP
_TEXT ENDS
Les plus observateurs d'entre vous auront remarqué que le code assembleur en version release est nettement plus petit qu'en version debug.
En fait, cela fait clairement rien d'autre que de retourner 0. Belle optimisation ! « Tape-m'en cinq ! »
Comme je l'ai mentionné plus tôt, le compilateur d'optimisation est très fort pour repérer le code qui, à la compilation, renvoie une constante et remplacera avec bonheur le code qu'il peut avec la constante équivalente.
IX. C'est pour cela que nous avons mis l'extrait de code dans une fonction▲
Il devrait être relativement clair maintenant de comprendre pourquoi nous avons mis le bout de code dans une fonction et ensuite demandé à l'éditeur de liens de ne pas supprimer le code des fonctions qui ne sont pas appelées.
Même si l'optimiseur peut supprimer l'appel à une fonction, le compilateur ne peut pas supprimer totalement la fonction avant l'édition des liens parce que du code en dehors de ce fichier objet pourrait l'appeler. Incidemment, la même cause empêche généralement les variables définies avec une portée globale d'être optimisées avant l'édition des liens.
Je vais appeler ceci le « lien Schrödinger » (accrocheur, non ?). Si nous voulons conserver notre morceau de code simple après optimisation, nous ne devons tricher avec l'optimiseur pour veiller à ce qu'il profite du « lien Schrödinger ».
Si le compilateur ne peut pas dire si la fonction est appelée, alors il ne peut certainement pas dire ce que seront les valeurs de ses paramètres au cours de l'un de ces appels potentiels ou comment sa valeur de retour sera utilisée, et il ne peut donc pas optimiser du code qui repose sur ses paramètres en entrée ou participe à sa valeur de retour.
Le résultat de ceci est que si nous mettons notre morceau de code dans une fonction, que l'on s'assure qu'elle utilise ses paramètres de fonction comme entrées et que sa valeur de retour est renvoyée par la fonction, elle devrait survivre à l'optimisation.
C'est vraiment un témoignage à tous les développeurs de compilateurs au cours des années passées, cela a coûté tant d'efforts pour obtenir un tel code assembleur optimisé à partir de ce morceau de code simple - développeurs de compilateurs, nous vous saluons !
X. La fonction ConditionalTest()▲
Donc, voici l'assembleur version Debug de la fonction ConditionalTest () (en ignorant le prologue et l'épilogue) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
; 5 : return( bFlag ? iOnTrue : iOnFalse );
movzx eax, BYTE PTR _bFlag$[ebp]
test eax, eax
je SHORT $LN3@Conditiona
mov ecx, DWORD PTR _iOnTrue$[ebp]
mov DWORD PTR tv66[ebp], ecx
jmp SHORT $LN4@Conditiona
$LN3@Conditiona:
mov edx, DWORD PTR _iOnFalse$[ebp]
mov DWORD PTR tv66[ebp], edx
$LN4@Conditiona:
mov eax, DWORD PTR tv66[ebp]
; 6 : }
Comme vous pouvez le voir, cela fait essentiellement la même chose que ce que nous avons vu dans le désassembleur du débogueur de l'article précédent :
- saut conditionnel sur la base du résultat du test de la valeur de bFlag (le mnémonique test fait « et logique » (AND) au niveau binaire) ;
- chacune des branches initialise la variable tv66 sur la Pile à partie de [
ebp] ; - et les deux branches exécutent alors la dernière ligne qui recopie le contenu de cette adresse dans
eax.
Encore une fois, le code assembleur est sans doute plus facile à suivre que dans le désassembleur parce que les mnémoniques jmp référencent des étiquettes clairement définies dans le code alors que dans la vue désassembleur de Visual Studio, vous devez croiser l'opérande de l'instruction jmp avec les adresses mémoires pour savoir où va le saut…
Nous allons comparer cela avec l'assembleur en mode release (encore une fois, sans montrer le prologue et l'épilogue de la fonction) :
2.
3.
4.
5.
6.
7.
; 5 : return( bFlag ? iOnTrue : iOnFalse );
cmp BYTE PTR _bFlag$[ebp], 0
mov eax, DWORD PTR _iOnTrue$[ebp]
jne SHORT $LN4@Conditiona
mov eax, DWORD PTR _iOnFalse$[ebp]
$LN4@Conditiona:
; 6 : }
Vous noterez que le travail de cette fonction se fait maintenant en quatre instructions par opposition aux neuf instructions de la version debug :
- il compare (
cmp) la valeur de bFlag avec 0 ; - il copie (
mov) sans condition la valeur de iOnTrue danseax; - si la valeur de bFlag n'est pas égale à 0 (c'est-à-dire qu'il est vrai), il saute la prochaine instruction…
- sinon il copie (mov) la valeur de iOnFalse dans
eax.
Comme je l'ai déjà dit, je ne suis pas un développeur en assembleur et je ne suis pas un expert en optimisation. Par conséquent, je ne vais pas donner mon opinion sur l'importance de l'ordre des instructions dans cet assembleur en version release.
Je suis toutefois prêt à prendre le risque de dire que la version Release avec quatre instructions va s'exécuter nettement plus rapidement que la version Debug avec neuf instructions.
Alors, pourquoi une telle différence entre les versions Debug et Release pour quelque chose qui, lors du débogage au niveau source, est une simple ligne ?
Essentiellement, c'est parce que le code assembleur non optimisé généré par le compilateur doit se prêter au débogage en mode pas à pas au niveau du code source :
- il fait presque toujours l'équivalent logique exact de ce que le code de haut niveau lui a demandé de faire et, en particulier, dans le même ordre ;
- il doit aussi souvent écrire les valeurs des registres de la CPU dans la mémoire pour que le débogueur puisse afficher leurs mises à jour.
XI. Résumé▲
Quel est le point principal que je voudrais que vous reteniez dans cet article ? Les optimiseurs de compilateur sont courageux !
Vous devez savoir comment les empêcher d'optimiser votre bout de code C/C++, si vous voulez être en mesure de facilement voir le code assembleur optimisé qu'ils génèrent.
Cet article montre une manière simple et générique pour court-circuiter l'optimiseur du compilateur Visual Studio - cela peut varier sur d'autres plateformes.
Il existe d'autres stratégies pour empêcher l'optimiseur d'optimiser votre code, mais elles reviennent en général toutes à utiliser le « lien Schrödinger » :
- utilisez des variables globales, les paramètres des fonctions ou les résultats d'appel de fonction comme entrées pour le code ;
- utilisez des variables globales, les valeurs de retour des fonctions ou des paramètres d'appel de fonctions en tant que sorties pour le code ;
- si vous n'utilisez pas le compilateur Visual Studio, vous pouvez aussi avoir besoin de désactiver la fonctionnalité « inline ».
Une dernière méthode extrême dont j'ai déjà parlé consiste à insérer des instructions nop par l'assembleur en ligne autour ou dans le code que vous souhaitez isoler. Notez que vous devez utiliser cette approche avec prudence, car elle interfère directement avec l'optimiseur et peut facilement affecter le résultat à un point tel qu'il n'est plus représentatif.
XII. Épilogue▲
J'espère donc que vous avez trouvé cela intéressant - je m'attends à ce que cela vous soit utile. ![]()
Le prochain article (comme promis la dernière fois !) parlera des boucles. C'est aussi la raison pour laquelle il semblait être le bon moment pour parler du code assembleur optimisé avec des exemples simples en C/C++.
Je ferai référence à cet article dans de prochains articles pour les situations où regarder le code assembleur optimisé est particulièrement pertinent.
Si vous vous demandez ce que vous devriez regarder en premier pour voir comment les versions Debug et Release sont différentes et que vous voulez avoir une bonne pratique pour battre l'optimiseur, je vous suggère de commencer par quelque chose de simple comme l'addition de quelques nombres entre eux.
En dernier, mais pas les moindres, merci à Rich, Ted et Bruce pour leur contribution et leur relecture. Et Bruce pour m'avoir fourni le truc qui a rendu cet article possible.
XIII. Remerciements▲
Cet article est la traduction de l'article « C/C++ Low Level Curriculum Part 8: looking at optimised assembly » écrit en anglais par Alex Darby. Alex Darby a aimablement autorisé l'équipe C/C++ de Developpez.com à traduire et diffuser son article en français.
Je tiens à remercier zoom61 pour la relecture orthographique de cette traduction.