



I. Prologue▲
Bonjour et bienvenue dans la seconde partie du programme d'études C & C++ bas niveau.
Cette partie va être un peu plus légère que la plupart de la série, principalement parce que cet article prend sur mon temps libre et mon envie de sauver une jeune fille blonde aux oreilles pointues du Seigneur Démon androgyne maigre de longs monologues dans un univers virtuel alimenté par trois triangles équilatéraux.
Avant de continuer, je voudrais vous présenter un livre qui m'a été recommandé à plusieurs reprises suite au premier article : Building a Modern Computer from First Principles.
Je ne peux me porter garant de sa qualité, mais j'ai bien l'intention de l'acheter et le lire dès que j'ai le temps. Ce livre a l'air bon et s'il est à moitié aussi bon qu'il en a l'air alors vous gagneriez vraiment à le lire…
II. Hypothèses▲
La prochaine chose sur mon agenda est de discuter des hypothèses/suppositions.
Les suppositions sont dangereuses. Même en écrivant ça je fais de nombreuses suppositions - que vous avez un ordinateur, que vous savez lire et comprendre l'anglais, et que vous vous intéressez au C++ bas niveau.
Par conséquent, cher lecteur, je pense qu'il est important que je mentionne ce que je suppose à votre sujet avant d'aller plus loin.
L'important selon moi à mentionner est que je suppose que vous êtes familier et compétent sur l'usage du C et/ou du C++. Si vous ne l'êtes pas, je vous conseillerais de le devenir avant d'aller plus loin.
III. Types de données ?▲
À nouveau je vais expliquer le titre de l'article au début et expliquer ce que j'entends par « types de données ».
Je parle des types de base du C++ et ce que vous devriez savoir à propos de leur représentation au niveau de la machine - même si cet aspect du C++ n'est pas nécessairement ce que vous attendiez ; particulièrement quand vous travaillez à destination de plusieurs plates-formes.
Ces informations ne vont pas soudainement améliorer votre code, mais, à mon avis, seront un atout sur la compréhension bas niveau de code C/C++ ; et sur les nombreux effets potentiels sur la vitesse d'exécution, agencement mémoire des types complexes, etc.
Certes, personne ne m'a jamais fait asseoir afin de m'expliquer tout cela, j'ai juste fait le tri des informations engrangées depuis des années.
IV. Les types de base et intrinsèques▲
Les types de base du C/C++ sont ceux qui bénéficient d'un mot-clé.
Ils ne doivent pas être confondus avec les types intrinsèques qui sont ceux gérés nativement par certains CPU (i.e. les types de données sur lesquels la machine sait opérer les instructions).
Quand vous utilisez du nouveau matériel, vous devriez vérifier comment le compilateur de la plate-forme représente les types de base. Et le meilleur moyen de vérifier est (vous l'auriez deviné ?) de regarder le code assembleur.
De nos jours, tous les types de base du C++ peuvent être représentés par un type intrinsèque sur la plupart des plates-formes ; mais vous ne devez pas tenir ça pour acquis, ce n'est le cas que depuis la dernière génération de console.
Il y a trois catégories de types de base : entier, flottant et void.
Comme on le sait tous, le type void ne peut pas être utilisé pour stocker des valeurs. Il est utilisé pour spécifier « aucun type ».
Pour les entiers et flottants, il y a différents types pour stocker des valeurs plus ou moins grandes et/ou avoir plus de précision.
Pour les entiers, les types sont (du plus petit au plus large) char, short, int, long, long long ; et pour les flottants : float, double, long double.
Il est clair que les valeurs possibles que peut stocker un type imposent une certaine taille de données (i.e. le nombre de bits nécessaires quand stocké en binaire).
V. Les tailles des types de base▲
Aussi loin que je l'ai découvert, les standards C et C++ ne donnent aucune garantie sur les tailles des types de base.
Il y a par contre certaines règles à propos des tailles de chaque type que je vais paraphraser ci-dessous :
charfait au moins 8 bits ;sizeof(char)==1;- Si un pointeur de type
char*pointe sur la première adresse d'un bloc de mémoire contigüe, alors on peut traverser le bloc et accéder à chaque élément en incrémentant le pointeur ; - Le standard C spécifie une valeur que chaque type entier doit être capable de représenter (voir page 33 de la norme C) ;
- Le standard C++ ne dit rien à propos des tailles des données, sauf que « il y a cinq types d'entiers signés :
signedchar,shortint,int,longintetlonglongint. Dans cette liste, chaque type est au moins aussi grand que le précédent » (voir page 75 de la norme C++) ; - Les points 4 et 5 ont des règles similaires sur la progression des types flottants.
La MSDN fournit un résumé de ces informations à cette URL. Ces informations sont en partie spécifiques à Visual Studio mais sont un bon point de départ.
Malgré cette absence du standard, la taille des types de base sur les PC et consoles est plutôt consistante.
Le standard C++ définit également le type bool comme un type entier. Il peut prendre deux valeurs, vrai (true) ou faux (false), qui peuvent être implicitement converties vers et depuis les valeurs entières 1 et 0 respectivement ; et qui est le type retourné par toutes les opérations logiques (==, !=, >, <, etc.).
Pour autant que je sache, le standard spécifie uniquement que le bool doit être capable de représenter un état binaire. Par conséquent, la taille d'un bool peut énormément varier d'un compilateur à l'autre, voire au sein d'un code généré par le même compilateur - je l'ai vu varier de 1 à 4 bytes sur les plates-formes que j'ai utilisées - j'ai toujours pensé qu'il s'agissait d'un compromis entre la vitesse d'exécution et la taille de stockage.
Le « problème de la taille du bool » a mené à l'interdiction de son utilisation dans les structures de données complexes au moins dans une société où j'ai travaillé. Je devrais préciser qu'il s'agissait d'une interdiction proactive parce que ça pouvait causer des problèmes et non parce que ça en avait déjà causé.
On devrait aussi mentionner les enums à ce moment (merci John !) - le standard donne la liberté de stocker les énumérations selon les valeurs qu'il contient. Donc un enum avec des valeurs < 255 (ou moins de 256 énumérations sans valeur assignée) devrait vérifier sizeof() == 1 et une énumération qui doit contenir des valeurs 32 bits devrait vérifier sizeof() == 4.
Ceci nous mène aux pointeurs. Les pointeurs ne sont pas définis comme un type de base à proprement parler, mais la valeur d'un pointeur a clairement une taille de donnée.
La première chose à remarquer sur les pointeurs est que la limite numérique nécessaire sur une plate-forme donnée est déterminée par la taille de la mémoire adressable.
Si vous avez 1 Go de mémoire qui doit être accessible par incrément de un byte, alors un pointeur doit pouvoir stocker jusqu'à ((1024 * 1024 * 1024) - 1) = (2^30 - 1) = 30 bits. 4 Go est le maximum qui peut être adressé avec une valeur sur 32 bits - ce qui explique pourquoi les systèmes win32 ne peuvent pas utiliser plus de 4 Go de mémoire.
Par exemple, si vous compilez pour win32 avec Visual Studio 2010, les pointeurs sont sur 32 bits (i.e. sizeof() == 4) et si vous compilez pour OSX avec XCode (sur le Macbook Pro que j'utilise au travail pour le développement IOS) les pointeurs sont sur 42 bits (sizeof() == 6).
La seule chose que l'on peut remarquer est que tous les pointeurs de données produits par un compilateur donné ont la même taille (N.B. : ce n'est pas vrai pour les pointeurs de fonction). Le type de pointeur est une abstraction du langage - pour la machine il s'agit juste d'adresse mémoire. C'est aussi pourquoi on peut tous les convertir vers et depuis void* - void* étant un « pointeur non typé » (N.B. : les pointeurs de fonction ne peuvent pas être convertis vers et depuis void*).
Ceci dit, connaître le type du pointeur est crucial à bas niveau et pour la plupart des mécanismes de plus haut niveau - comme nous le verrons dans les prochains articles.
VI. Supplément▲
Suite à certains commentaires, je dois traiter les pointeurs de fonction distinctement des pointeurs de données.
J'ai fait un postulat incorrect que tous les pointeurs avaient la même taille. Ceci est vrai pour les pointeurs de données uniquement.
Les pointeurs de fonction peuvent être de tailles différentes, précisément parce qu'il ne s'agit pas nécessairement d'adresses mémoire – dans le cas d'héritage ou fonctions virtuelles il s'agit typiquement de structures.
Je recommande le blog que Bryan Robertson m'a indiqué, qui fournit des exemples concrets du pourquoi les pointeurs de fonctions membres ont souvent besoin de bien plus qu'une simple adresse mémoire : Pointers to member functions are very strange animals
J'ai également trouvé ces liens utiles à propos des pointeurs de fonction et du type void* (l'ensemble de ce site est plutôt utile en fait) :
- Can I convert a pointerto-member-function to a void*? ;
- Can I convert a pointerto-function to a void*?.
Merci à Bryan et Jalf de m'avoir poussé à rechercher à ce sujet.
VII. Les types intrinsèques utilisés par les types de base▲
Comme mentionné plus haut, ça varie selon les plates-formes - et même à ce moment il n'y a aucune garantie que le compilateur utilisera les types intrinsèques supportés par la plate-forme sur laquelle vous travaillez.
Voici une capture d'écran d'une application console win32 créée sous VS2010 qui affiche les tailles des types de base :
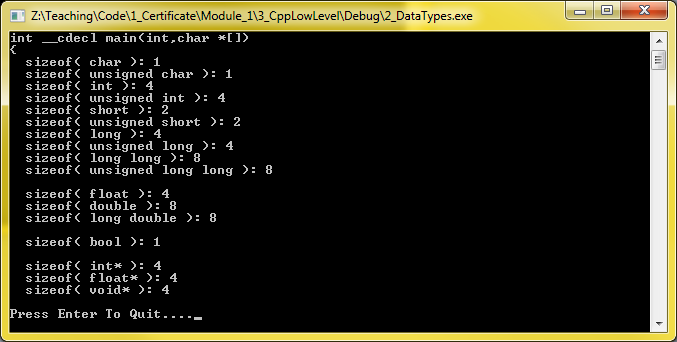
Ma machine personnelle est un Intel 64 bits d'à peu près un an.
Comme le processeur est 64 bits, je m'attends à ce que ces tailles correspondent aux types intrinsèques (huit bytes étant la taille d'un registre sur un CPU 64 bits), mais comme je compile pour win32 (qui peut uniquement traiter un registre de quatre bytes), je suppose que les types intrinsèques ne seront pas utilisés pour des tailles supérieures à 32 bits.
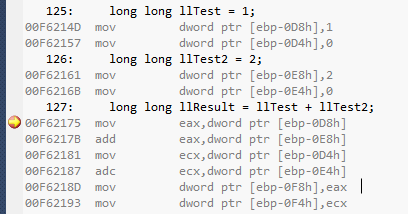
Comme à l'accoutumée, on ne peut pas être certain sans regarder le code assembleur.
Les long long de huit bytes sont gérés comme deux valeurs 32 bits.
Ignorons l'addition, vous pouvez clairement remarquer ça avec l'initialisation de llTest et llTest2 qui est faite en deux étapes pour les bytes de poids fort et de poids faible de 32 bits chacun.
VIII. Fantaisies internes▲
La plupart des CPU modernes ont des fantaisies internes - par exemple des registres de 128 bits qui peuvent stocker et opérer sur quatre flottants 32 bits en une seule fois.
En théorie ces types intrinsèques supplémentaires peuvent être un gros avantage dans certaines situations - par exemple de gros blocs de mathématiques vectorielles, ou de mathématiques non vectorielles qui peuvent être parallélisés dans des vecteurs.
Par chance, le compilateur n'utilisera pas ces artifices sans le demander clairement. Il y a plein de raisons pour lesquelles c'est le cas (apparemment), mais vous devriez trouver le support pour ces spécifications matérielles dans les manuels du compilateur ou de votre matériel.
IX. Résumé▲
Que faut-il retenir de cet article ?
D'abord, qu'il y a une différence entre les types de données du C++ et leur représentation par le matériel.
Ensuite, ne croyez pas que le compilateur fait ce qui vous semble intuitif. Vérifiez son travail.
Ce n'est pas sorcier ! Vous pouvez en apprendre en modifiant des exemples de programmes pour votre matériel et regarder le code assembleur dans le débogueur.
Enfin, j'ai pensé que je pourrais insérer ici quelques points-clés :
- Presque tous les CPU ont des bytes de 8 bits. Tout CPU avec plus de 8 bits par byte a probablement été créé par un maniaque/génie (N.B. : j’ai remarqué qu'il y avait une différence particulièrement floue entre les deux en informatique).
- Vous devez faire attention avec les types numériques dans le standard C, les
intetshortont la même valeur limite à stocker (unsignedintetunsignedshortont tous deux0xFFFF(i.e. 16 bits)). Je n'ai jamais eu de problème avec ça, mais unintpourrait être représenté par 16 bits. - Si vous voulez connaître la taille d'un type donné, utilisez le mot-clé
sizeof(). Votre compilateur sait ces choses.
X. Remerciements▲
Cet article est une traduction autorisée de C/C++ Low Level Curriculum part 2: Data Types par Alex Darby.
Merci à mitkl pour leur relecture technique, à ram-0000 pour la gabarisation de l'article, à FirePrawn et à ClaudeLELOUP pour leur relecture orthographique.