



I. Introduction▲
Bonjour et bienvenue dans la 12e partie du programme d'étude sur le bas niveau C/C++. Vraiment peu de temps après la partie 11 ! (Non, bien sûr la partie 11 n'était pas très grosse et devait être coupée. Pourquoi, me demanderez-vous ?)
La dernière fois, nous avions examiné les bases d'implémentation bas-niveau de l'héritage et cette fois-ci, nous allons examiner les effets de l'utilisation de l'héritage multiple sur ce tableau.
Nous allons laisser le mot clé virtual jusqu'à la fois prochaine.
II. Avant que nous commencions▲
Je vais partir du principe que vous avez déjà lu les articles précédents de la série, mais je vais aussi mettre directement les liens sur tous les termes importants ou les concepts que vous pourriez avoir besoin de connaître pour comprendre ce que vous lisez. Je me rends utile comme cela.
Une autre hypothèse importante que je vais faire, c'est que vous êtes déjà très familiarisés au langage C++ et à l'aise avec les fonctionnalités du langage que nous allons détailler, ainsi que les limites liées à l'utilisation de ces fonctionnalités. Si j'ai besoin de prouver quelque chose qui sort de l'ordinaire, je l'expliquerai ou, au minimum, je donnerai un lien vers l'explication.
Dans cette série, j'explique ce qui se produit avec un code simple et non optimisé de débogage Win32 généré par le compilateur VS 2010, bien que les détails diffèrent sur d'autres plates-formes (et probablement avec les autres compilateurs). Le parcours général du code devrait être fondamentalement le même parce que c'est l'assembleur qui a été généré par un compilateur C++. Ainsi, en suivant les mêmes exemples donnés ici, avec un débogueur de source / désassembleur de la plate-forme de votre choix devrait vous fournir le même aperçu que nous avons ici.
Avec ceci en tête, au cas où vous les auriez loupés, voici les liens vers les articles précédents de la série :
- Programme d'étude sur le C++ bas-niveau n°1 ;
- Programme d'étude sur le C++ bas-niveau n°2 ;
- Programme d'étude sur le C++ bas-niveau n°3 ;
- Programme d'étude sur le C++ bas-niveau n°4 ;
- Programme d'étude sur le C++ bas-niveau n°5 ;
- Programme d'étude sur le C++ bas-niveau n°6 ;
- Programme d'étude sur le C++ bas-niveau n°7 ;
- Programme d'étude sur le C++ bas-niveau n°8 ;
- Programme d'étude sur le C++ bas-niveau n°9 ;
- Programme d'étude sur le C++ bas-niveau n°10 ;
- Programme d'étude sur le C++ bas-niveau n°11.
Je ne vais pas mentir, ce n'est pas facile à lire. ![]()
III. Je viens juste de lire l'article 11 et tout me semble assez clair▲
Bien ! Cela devrait être le cas !
De par mon expérience, beaucoup de bonnes solutions à des problèmes apparaissent claires quand elles sont bien expliquées.
Maintenant que nous avons une bonne compréhension du comportement de l'héritage simple, allons examiner les effets de l'héritage multiple€¦
IV. Héritage multiple▲
Passons à l'échantillon d'étude !
Comme la dernière fois , j'ai amoureusement zippé le combo solution VS2010/projet/code source fait maison allant avec cet échantillon et contenant le code suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
class CTestBaseOne
{
public:
int _iA;
int _iB;
CTestBaseOne( int iA, int iB )
: _iA( iA )
, _iB( iB )
{}
int SumBase( void )
{
return _iA + _iB;
}
};
class CTestBaseTwo
{
public:
int _iC;
int _iD;
CTestBaseTwo( int iC, int iD )
: _iC( iC )
, _iD( iD )
{}
int SumBaseTwo( void )
{
return _iC + _iD;
}
};
class CTestDerived : public CTestBaseOne,
public CTestBaseTwo
{
public:
int _iE;
int _iF;
CTestDerived( int iA, int iB, int iC, int iD )
: CTestBaseOne ( iA, iB )
, CTestBaseTwo ( iC, iD )
, _iE ( iB )
, _iF ( iD )
{ }
int SumDerived( void )
{
return return SumBase() + SumBaseTwo() +_iE + _iF;
}
};
int main( int argc, char* argv[] )
{
CTestBaseOne cTestBaseOne( argc, argc + 1 );
CTestBaseTwo cTestBaseTwo( argc, argc + 1 );
CTestDerived cTestDerived( argc, argc + 1, argc + 2, argc + 3 );
return cTestBaseOne.SumBase() + cTestBaseTwo.SumBaseTwo()
+ cTestDerived.SumBase() + cTestDerived.SumBaseTwo() + cTestDerived.SumDerived();
}
Quand vous l'aurez dézippé, allez de l'avant et compilez-le.
N'oubliez pas de faire attention à la sortie du compilateur, elle montre l'agencement mémoire dont nous allons parler après.
V. Agencement mémoire▲
Comme vous pouvez le voir, nous avons maintenant deux classes de base et une classe qui dérive de celles-ci.
Quand vous compilez le projet, vous devriez voir que l'agencement mémoire de ces classes ressemble à ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
1> class CTestBaseOne size(8):
1> +---
1> 0 | _iA
1> 4 | _iB
1> +---
1>
1> class CTestBaseTwo size(8):
1> +---
1> 0 | _iC
1> 4 | _iD
1> +---
1>
1> class CTestDerived size(24):
1> +---
1> | +--- (base class CTestBaseOne)
1> 0 | | _iA
1> 4 | | _iB
1> | +---
1> | +--- (base class CTestBaseTwo)
1> 8 | | _iC
1> 12 | | _iD
1> | +---
1> 16 | _iE
1> 20 | _iF
1> +---
C'est tout ce que nous espérions, étant donné ce que nous avions découvert la dernière fois.
En particulier, notez ceci :
- l'agencement mémoire des deux classes de base est embarqué à l'intérieur de CTestDerived ;
- CTestBaseOne et CTestBaseTwo apparaissent dans l'agencement mémoire suivant le même ordre ou elles sont déclarées dans la liste de spécification de base.
Note : la liste de spécification de base est la partie de la déclaration d'une classe où les classes de base sont spécifiées.
Dans le cas d'un héritage simple que nous considérions dans l'article précédent, nous avions vu que les fonctions d'une classe de base B peuvent être appelées sur une instance d'une classe dérivée D parce que :
- l'agencement mémoire de D contient littéralement une instance de B à un déplacement de 0 octet à partir de lui-même et€¦
- €¦ ceci signifie que les données membres d'une instance de B sont au même emplacement relatif que pour l'agencement mémoire d'une instance de D€¦
- €¦ et donc les déplacements codés en dur utilisés pour accéder à ces membres à l'intérieur des fonctions appartenant à B sont aussi valides pour une instance de D.
En regardant l'agencement mémoire pour cette classe à héritage multiple, nous pouvons voir que :
- Cette relation continue pour CTestBaseOne et CTestDerived. CtestBaseOne est à un déplacement de 0 octet à l'intérieur de l'agencement mémoire de CTestDerived ;
- Cependant, cette même relation n'est pas vraie pour CTestBaseTwo et CTestDerived.
Compte tenu de cette situation, comment font les fonctions de CTestBaseTwo pour fonctionner avec les instances de CTestDerived?
Comme d'habitude, la meilleure chose à faire est d'aller voir€¦
VI. Appeler une fonction de CTestBaseTwo sur CTestDerived▲
Mettez un point d'arrêt sur la ligne return du main(), exécutez le code et quand il s'arrête, faites un clic droit puis choisissez « Atteindre le code machine ».
Plutôt que de coller le code désassembleur comme du texte, cette fois-ci j'ai inséré une capture d'écran de ma fenêtre de débogage ; ceci donne accès à plus d'options de mise en forme et de mise en évidence.
N.B. : dans cette capture d'écran, j'ai coché l'option « Afficher les noms de symboles » dans les options de visualisation. Tandis que cela permet de lier plus facilement le désassembleur au code C ou C++, cela cache des détails (c'est-à-dire l'adresse des symboles).
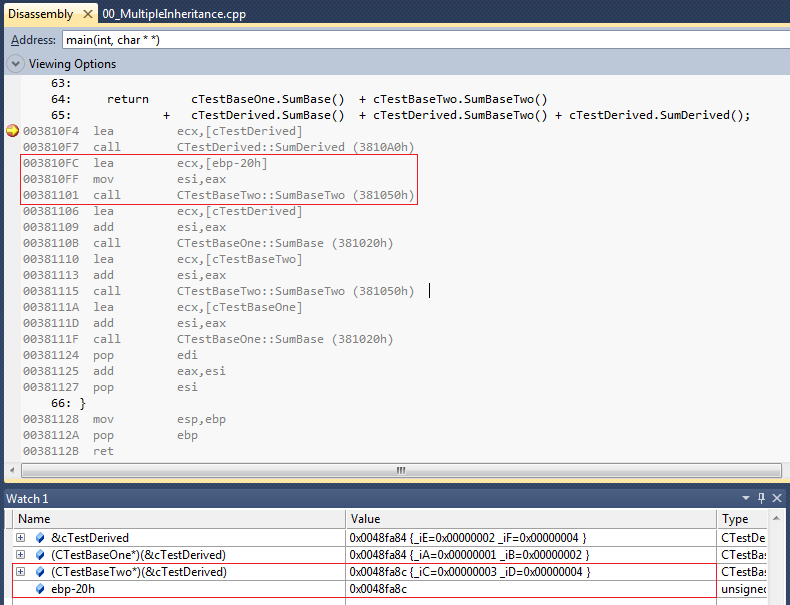
Décortiquons-le en commençant à l'indicateur de ligne où le point d'arrêt est et descendons :
- nous pouvons voir (suivant la convention d'appel x86 thiscall) qu'avant chaque appel de fonction, l'adresse de l'objet correspondant est stockée dans
ecxen utilisantlea; - en premier, il charge l'adresse de cTestDerived dans
ecxet ensuite appelleCTestDerived::SumDerived()€¦ - puis il€¦
- Oh, attendez€¦ il charge l'adresse [
ebp-20h] dansecx€¦ - ce symbole n'est pas résolu par la fenêtre de désassembleur, donc quelle est cette sorcellerie ?
J'ai gentiment encadré en rouge les zones importantes de la capture d'écran. ![]()
Si vous regardez les appels de fonction faits dans le désassembleur et vous les comparez avec les appels dans le code C++, vous verrez que tous les appels de fonction de haut niveau ont un analogue au niveau de l'assembleur excepté cDerived.SumBaseTwo().
CTestBaseTwo::SumBaseTwo va être appelée, mais avec [ebp-20h] comme le pointeur this dans ecx et non [cTestDerived] (N.B. : voir l'encadré rouge d'en haut dans la capture d'écran).
Donc, la question est : Comment l'adresse [ebp-20h] est-elle liée à l'adresse de cTestDerived?
Ce serait le bon moment pour vous rappeler que la fenêtre espion est votre amie. Nous pouvons utiliser cette fenêtre pour déduire une réponse.
Si vous regardez dans la fenêtre espion, en dessous de la vue désassembleur (montrée seule ci-dessous pour ceux d'entre vous qui ont un petit écran), vous pourrez voir que j'ai utilisé l'évaluation d'expression de la fenêtre espion pour découvrir quelques informations concernant ces valeurs :

Cela nous montre que :
- l'adresse de cTestDerived est 0x0048fa84€¦
- €¦ et l'adresse de cTestDerived castée en pointeur sur CTestBaseOne a la même adresse€¦
- €¦ mais quand l'adresse de cTestDerived est castée en CTestBaseTwo, nous obtenons 0x0048fa8c€¦
- €¦ qui est la même valeur que [
ebp-20h]€¦ - €¦ ou un déplacement de 8 octets depuis l'adresse de cTestDerived€¦
- €¦ qui est la position de CTestBaseTwo à l'intérieur de CTestDerived
VII. Ceci devrait-il être surprenant ?▲
Voici encore l'agencement mémoire de CTestDerived :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
1> class CTestDerived size(24):
1> +---
1> | +--- (base class CTestBaseOne)
1> 0 | | _iA
1> 4 | | _iB
1> | +---
1> | +--- (base class CTestBaseTwo)
1> 8 | | _iC
1> 12 | | _iD
1> | +---
1> 16 | _iE
1> 20 | _iF
1> +---
Depuis que nous savons que :
- (dans les fonctions membres non statiques) les variables membres sont accessibles via des déplacements constants depuis leur pointeur
this; - la mémoire pour CTestBaseTwo commence à une position de 8 octets depuis le début de l'agencement mémoire d'une instance de CTestDerived.
Il s'en suit que CTestBaseTwo::SumBaseTwo() ne fonctionnerait pas si le compilateur passait l'adresse d'une instance de CTestDerived. Cela parce que les déplacements constants utilisés pour accéder aux membres de CTestBaseTwo seraient hors des 8 octets.
Par conséquent, à chaque fois qu'une fonction membre de CTestBaseTwo est appelée sur une instance de CTestDerived, le compilateur doit s'assurer qu'un pointeur this compatible est généré pour le passer à la fonction, c'est-à-dire pointant sur l'adresse de début de CTestBaseTwo dans l'instance de CTestDerived.
Terriblement évident une fois que vous le savez, n'est-ce pas ?
Je ne pense pas que cela soit vraiment surprenant, bien qu'en partant du principe que nous connaissons le mode d'accès des données à l'intérieur de types définis par l'utilisateur au niveau de l'assembleur (voir la 10e partie), cela aurait dû fonctionner à peu près comme ça.
VIII. €¦ Encore une petite chose▲
Dans l'exemple ci-dessus, CTestDerived est une variable sur la pile, donc le compilateur connaît sa position exacte dans la structure de la pile courante.
Cela signifie que le compilateur peut calculer l'adresse de l'instance de CTestBaseTwo à l'intérieur de CTestDerived au moment de la compilation, et peut donc y accéder sans coût supplémentaire par rapport aux autres variables de la pile.
Nous devrions probablement vérifier s'il n'y pas de différence lorsque nous avons affaire à un pointeur vers un CTestDerived à un emplacement mémoire arbitraire, juste pour être minutieux.
Heureusement, j'ai déjà pensé à cela.
Si vous placez un point d'arrêt sur l'instruction return de CTestDerived::SumDerived vous pourrez vérifier le désassembleur vous-même, mais voici les lignes concernées de ma fenêtre de désassembleur :
2.
3.
4.
5.
6.
7.
8.
52: int SumDerived( void )
53: {
001010A0 push esi
001010A1 mov esi,ecx
001010A3 push edi
54: return SumBase() + SumBaseTwo() +_iE + _iF;
001010A4 lea ecx,[esi+8]
001010A7 call CTestBaseTwo::SumBaseTwo (101050h)
Comme vous devriez le voir maintenant, le code de cette fonction ajoute un déplacement constant de 8 octets sur le pointeur this qui est passé pour générer le pointeur this qui va être passé à CTestBaseTwo::SumBaseTwo.
Si vous avez des problèmes pour le voir, rappelez-vous que la convention d'appel de fonction membre Win32 « thiscall » utilise ecx pour passer le pointeur this.
Plus important, allez revoir l'article précédent, vous pourriez voir que c'est essentiellement le même mécanisme que pour les variables membres d'un type défini par l'utilisateur quand nous avons un pointeur sur une instance d'un type défini par l'utilisateur. En fait, au niveau du code assembleur, il n'y a vraiment aucune différence entre une variable membre et une classe de base ; cette distinction est réellement significative au niveau du code C++.
Nous savons aussi que l'héritage multiple peut engendrer, dans votre code, une légère augmentation de coût dans l'arithmétique des pointeurs quand vous appelez des fonctions membres de n'importe quelle classe de base qui n'a pas un déplacement de 0 à l'intérieur de l'agencement mémoire.
IX. Qu'est-ce que c'était plutôt ? À propos de l'ordre de déclaration ?▲
Si vous êtes attentif, vous devriez avoir noté que quand nous regardions l'agencement mémoire de CTestDerived, j'avais mentionné en passant que l'ordre de CTestBaseOne et CTestBaseTwo à l'intérieur de celle-ci correspondait à l'ordre textuel dans lequel elles étaient listées dans la liste de spécification de base.
C'est évidemment important, car cela implique que si l'ordre textuel dans lequel CTestBaseOne et CTestBaseTwo sont listées change, alors l'agencement mémoire de CTestDerived va changer pour le refléter.
Si vous changez l'ordre de CTestBaseOne et CTestBaseTwo, vous trouverez l'agencement mémoire affiché pendant le processus de compilation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
1> class CTestDerived size(24):
1> +---
1> | +--- (base class CTestBaseTwo)
1> 0 | | _iC
1> 4 | | _iD
1> | +---
1> | +--- (base class CTestBaseOne)
1> 8 | | _iA
1> 12 | | _iB
1> | +---
1> 16 | _iE
1> 20 | _iF
1> +---
1>
Étant donné ce que nous avons découvert jusqu'à présent, nous pouvons voir que ce nouvel agencement mémoire signifie que CTestDerived peut maintenant être traité comme une instance de CTestBaseTwo.
Nous pouvons aussi voir qu'avec ce nouvel agencement, le compilateur va avoir besoin d'ajuster les pointeurs de CTestDerived afin d'appeler les fonctions de CTestOne.
Je laisse cela comme un exercice pour vous, lecteur expert de désassembleur x86 en herbe, vérifier cela vous-même. ![]()
X. D'un autre côté : construction et destruction avec un héritage simple▲
Quelque chose que nous avons complètement ignoré dans l'article précédent était la construction et la destruction des types hérités.
C'était intentionnel, la construction et la destruction sont simples avec un héritage simple.
Nous devrions tous connaître le comportement de haut niveau d'un héritage simple (pour une profondeur arbitraire). En résumé :
- chaque constructeur appelle le constructeur de sa classe de base avant de faire le travail déclaré dans son corps. Cela signifie que les classes sont construites dans l'ordre « de l'intérieur vers l'extérieur » ou « de la moins dérivée à la plus dérivée » ;
- les destructeurs font l'inverse, chaque destructeur fait d'abord son travail avant d'appeler le destructeur de sa classe de base. Cela signifie que les classes sont détruites dans l'ordre « de l'extérieur vers l'intérieur » ou « de la plus dérivée à la moins dérivée ».
Le désassembleur correspond au comportement de haut niveau et d'une manière très simple. Je laisse cela comme un exercice pour les lecteurs qui souhaitent faire défiler le désassembleur de la construction et destruction dans un code de test pour le voir en action.
Comme le reste du comportement que nous avons découvert jusqu'ici, quand vous pensez à cela, c'est en fait assez évident que le comportement construction/destruction sous forme de « pile » est nécessaire afin de permettre à l'héritage de fonctionner correctement.
XI. Construction et destruction avec l'héritage multiple▲
C'était assez évident que nous allions en arriver là, pas vrai ?
Ce qui se passe lors de la construction et destruction quand l'héritage multiple est impliqué est moins simple.
Par exemple, dans quel ordre sont appelés les constructeurs des multiples classes de base ? €¦ et dans quel ordre sont appelés leur destructeur ?
Nous allons aussi partir du principe que le constructeur et le destructeur sont des fonctions membres, il doit y avoir un jeu autour des pointeurs this pendant ce processus aussi.
Heureusement, c'est très simple à déterminer empiriquement : nous pouvons juste ajouter du texte dans les constructeurs et destructeurs des classes exemples pour afficher le nom des fonctions et la valeur de leur pointeur this.
Voici un lien vers un projet VS2010 que j'ai préparé juste pour faire cela, j'ai juste ajouté un peu de code au code originel d'exemple.
Ci-dessous est affichée la sortie en ligne de commande produite lors de son exécution :

Vous pouvez voir que :
- les constructeurs sont appelés dans l'ordre textuel dans lequel ils apparaissent dans la déclaration de classe de CTestDerived, depuis la moins dérivée (c'est-à-dire CTestBaseOne) à la plus dérivée (c'est-à-dire CTestDerived) ;
- les destructeurs sont appelés dans l'ordre opposé, c'est pour s'assurer que le travail fait dans les constructeurs est défait dans l'ordre opposé ;
- cela montre aussi que les pointeurs
thissont modifiés pour le constructeur et le destructeur de CTestBaseTwo, juste comme cela était effectué quand nous étions en train d'appeler une fonction membre ordinaire.
À ce stade, vous devriez vous sentir libre de changer l'ordre de CTestBaseOne et CTestBaseTwo dans la liste des spécificateurs de CTestDerived, cela pour vérifier que cette construction et destruction suit les mêmes règles que l'ordonnancement des types de base dans l'agencement mémoire d'un type dérivé (ils le font, je vous promets).
XII. Résumé▲
C'est tout pour cette fois et c'était massif ! Je parie que vous êtes heureux que j'aie sorti cela de l'article 11 maintenant. ![]()
Les plus astucieux d'entre vous devraient avoir noté que nous n'avons pas regardé de code utilisant le mot clé virtual. C'est entièrement délibéré et ce sera pour la prochaine fois.
Donc, récapitulons ce que nous avons découvert jusqu'ici à propos de l'héritage€¦
En premier, ce que nous avons appris à propos de l'héritage simple dans la partie 11 :
- Nous savons que l'agencement mémoire d'un type défini par l'utilisateur est fixé à la compilation€¦
- €¦ et donc que le code accédant à une donnée membre d'un type défini par l'utilisateur peut utiliser un déplacement relatif constant à partir de l'adresse de départ d'une instance de ce type (voir la partie 10) ;
- Dans un héritage simple, l'agencement mémoire d'un type dérivé D étend littéralement celle de son type de base B ;
- Cela garantit que les membres hérités de B sont à un emplacement constant par rapport à l'adresse de base d'une instance de D comme ils le seraient par rapport à l'adresse de base d'une instance de B…
- €¦ ce qui signifie qu'un pointeur sur une instance de type D peut être traité en toute sécurité comme un pointeur sur une instance de type B€¦
- €¦ qui à leur tour garantie que les fonctions membres de type B peuvent être appelées en toute sécurité sur une instance de D.
Nous avons aussi découvert que si une classe dérivée D hérite de plusieurs types de base A et B, alors cet héritage multiple rompt quelque peu la commodité de l'approche de l'héritage simple :
- Comme avec un héritage simple, l'agencement mémoire d'une instance de D contient les données membres de A et B, organisées de la même manière que dans chaque classe de base ;
- Les fonctions membres des types A et B vont utiliser un déplacement constant relatif à leurs pointeurs
thispour accéder à leurs données membres ; - Logiquement, seuls A ou B peuvent avoir un déplacement de 0 octet à l'intérieur de l'agencement mémoire d'une instance de D€¦
- €¦ par conséquent, un pointeur sur une instance de type D ne peut être traité en toute sécurité comme un pointeur sur n'importe lequel de A ou B avec un déplacement de 0 octet à l'intérieur de l'agencement mémoire ;
- Quel type de base à un déplacement de 0 octet est déterminé par l'ordre textuel des types A et B à l'intérieur de la liste de spécification de base de la déclaration de D ;
- €¦ si A avait un déplacement de 0 octet à l'intérieur de D, le compilateur devrait calculer un pointeur
thiscompatible chaque fois qu'une fonction membre de B est appelée sur une instance de D (et vice versa) ; - €¦ quand une instance de D est créée, les instances de A et B contenues à l'intérieur de son agencement mémoire vont être construites par leurs propres constructeurs avant que le constructeur de D soit appelé, et€¦
- €¦ l'ordre dans lequel A et B sont construits dépend de l'ordre textuel à l'intérieur de la liste de spécification de base de la déclaration de D (c'est-à-dire qu'ils vont être construits dans l'ordre du déplacement mémoire).
XIII. Démenti▲
Les points ci-dessus sont des faits que nous avons découverts empiriquement en examinant le comportement d'un code x86 Win32 créé par le compilateur Visual Studio 2010.
Ne partez pas du principe que le code généré sur d'autres plates-formes/compilateurs va se comporter de manière identique. Il devrait se comporter de manière similaire, mais vous devriez vérifier.
En général, pour chaque type POD (POD est un simple agrégat de données), vous devriez être capable d'enregistrer sa mémoire dans un fichier en binaire et la recharger en mémoire dans une autre instance de même type.
Évidemment, cela n'est vrai que si et seulement si vous ne changez pas de plate-forme cible, de compilateur, les options, les spécifications d'alignement, ou la déclaration du type.
XIV. Annexe : ce que la norme C++ dit à propos de tout ça ?▲
J'ai passé du temps à lire la norme ISO C++11 (ou une version proche de celle publiée au moins), mais même après avoir consulté le code source, ce n'est pas clair à 100 % pour moi concernant ce qui est garanti de ce qui ne l'est pas par la norme. Voir ce qui suit pour plus d'information.
Voici une suite d'extraits d'informations que j'ai trouvées dans ce brouillon proche de la version de la norme ISO C++11 quand j'étais à la recherche de différents morceaux pour cet article (vous devez payer l'ANSI pour la version actuelle). Si vous voulez plus d'informations sur n'importe lequel des points ci-dessous, cliquez sur le lien ci-dessus pour télécharger le PDF et cherchez le texte en retrait ; cela vous donnera la page sur laquelle il était. Ce document n'est pas fait pour une lecture légère !
XIV-A. Ordre des classes de base en mémoire à l'intérieur d'un héritage multiple▲
Pour autant que je sache, ce n'est pas garanti par la norme. En fait, le brouillon de la norme dit ceci :
XIV-A-1. 10.1 Multiple base classes [class.mi]▲
1 A class can be derived from any number of base classes. [Note: The use of more than one direct base class is often called multiple inheritance. €”end note] [Example:
class A { /_ ... _/ };
class B { /_ ... _/ };
class C { /_ ... _/ };
class D : public A, public B, public C { /_ ... _/ };€”end example]
2 [Note :The order of derivation is not significant except as specified by the semantics of initialization by constructor (12.6.2), cleanup (12.4), and storage layout (9.2, 11.1). €”end note]
XIV-A-2. 10.1 Classes de base multiple [class.mi]▲
1 Une classe peut être dérivée à partir de n'importe quel nombre de classes de base. [Note : l'utilisation de plus d'une classe de base directe est souvent appelé héritage multiple. Fin note] Exemple :
class A { /_ ... _/ };
class B { /_ ... _/ };
class C { /_ ... _/ };
class D : public A, public B, public C { /_ ... _/ };€”end example]
2 [Note : l'ordre de dérivation n'est pas significatif sauf tel que spécifié par la sémantique d'initialisation par constructeur (12.6.2), nettoyage (12.4), et agencement de stockage (9.2, 11.1). Fin note]
Ce qui signifie plus ou moins que ce n'est pas garanti.
XIV-B. Ordre des données membres à l'intérieur d'une classe▲
Donc, il apparaît qu'un compilateur C++ est autorisé à réordonner les données membres d'une classe en mémoire par rapport à leur ordre de déclaration textuel si (et seulement si) leur niveau de visibilité (c'est-à-dire public, private, protected) est différent :
15 Nonstatic data members of a (non-union) class with the same access control (Clause 11) are allocated so that later members have higher addresses within a class object. The order of allocation of non-static data members with different access control is unspecified (11). Implementation alignment requirements might cause two adjacent members not to be allocated immediately after each other; so might requirements for space for managing virtual functions (10.3) and virtual base classes (10.1).
15 Les données membres non statiques d'une classe (n'étant pas une union) avec le même niveau de visibilité (Clause 11) sont allouées de sorte que les derniers membres aient l'adresse la plus grande à l'intérieur de la classe objet. L'ordre d'allocation des données membres non statique avec différents niveaux de visibilité n'est pas spécifié (11). Les spécifications d'alignement, d'implémentation peuvent faire que deux membres adjacents ne soient pas alloués immédiatement l'un après l'autre à cause des exigences d'espace pour la gestion des fonctions virtuelles (10.3) et des classes de base virtuelle (10.1).
Je ne peux pas imaginer que cela puisse être encore un problème pour vous, à moins que vous écriviez une bibliothèque de réflexion ou quelque chose de similaire.
XIV-C. Ordre d'appel des constructeurs lors de la construction du type avec types de base▲
Heureusement, il semble y avoir encore de la raison dans cet univers comme j'ai trouvé la partie de la norme qui spécifie l'ordre dans lequel les constructeurs sont appelés pour les types qui utilisent l'héritage.
8 In a non-delegating constructor, if a given non-static data member or base class is not designated by a mem-initializer-id (including the case where there is no mem-initializer-list because the constructor has no ctor-initializer) and the entity is not a virtual base class of an abstract class (10.4), then €” if the entity is a non-static data member that has a brace-or-equal-initializer, the entity is initialized as specified in 8.5;
€” otherwise, if the entity is a variant member (9.5), no initialization is performed;
€” otherwise, the entity is default-initialized (8.5).
[Note: An abstract class (10.4) is never a most derived class, thus its constructors never initialize virtual base classes, therefore the corresponding mem-initializers may be omitted. €”end note]
8 Dans un constructeur non déléguant, si une donnée membre ou une classe de base n'est pas désignée par un mem-initializer-id (incluant le cas où il n'y a pas de mem-initializer-list parce que le constructeur n'a pas de ctor-initializer) et l'entité n'est pas une classe de base virtuelle d'une classe abstraite (10.4), alors l'entité est une donnée membre non statique qui a une brace-or-equal-initializer. L'entité est initialisée comme spécifié dans 8.5 :
- autrement dit, si l'entité est un membre variant (9.5), aucune initialisation n'est effectuée ;
- sinon, l'entité est initialisée par défaut (8.5).
[Note : une classe abstraite (10.4) n'est jamais la classe la plus dérivée. Ainsi, ses constructeurs n'initialisent jamais des classes de base virtuelle. Cependant, la mem-initializers correspondante peut être omise. Fin note]
Trop long, pas lu (si vous n'utilisez pas des classes de base virtuelle). Chaque constructeur initialise ses classes de base dans l'ordre de déclaration, puis les membres de la classe dans l'ordre de déclaration, puis le corps du constructeur est exécuté.
XV. Remerciements▲
Mes remerciements pour la relecture par des pairs vont à Bruce Dawson et Amir Embrahimi ; et en général à l'administrateur d'aide d'AltDevBlogDay Luke Dicken.
Cet article est la traduction de l'article « C/C++ Low Level Curriculum Part 12: Multiple Inheritance » écrit en anglais par Alex Darby. Ce dernier a aimablement autorisé l'équipe C/C++ de Developpez.com à traduire et diffuser son article en français.
Nous tenons à remercier LittleWhite, Winjerome et oodini pour la relecture technique ainsi que milkoseck pour la relecture orthographique de cette traduction.