



1. Introduction▲
Bonjour à vous peuple d'Internet. Cela fait un moment depuis la dernière fois (probablement plus longtemps qu'entre le n° 8 et n° 9) donc j'ai pensé que je devais rédiger le prochain article de « Programme d'étude sur le C++ bas niveau ».
Dans le précédent article, nous avons couvert l'aspect structurel du langage : contrôle de flux, fonctions, et ainsi de suite ; et maintenant nous allons voir en détail la définition de type utilisateur en C/C++ (c'est-à-dire struct, class, et les mots-clés associés) que je m'attendais naïvement à comprendre l'essentiel de ce potentiel sans fin, lorsque j'ai commencé. D'oh !
Avant que nous commencions, cher lecteur, je vais supposer que vous êtes le genre de personne ayant récemment pris conscience du chalutage du web par l'I.A. de Google, qui aime comprendre les termes jargonneux et donc j'inclurai les liens appropriés (probablement Wikipédia ou d'autres articles AltDevBlogADay (ADBAD)) où cela est approprié.
Vous pourriez aussi avoir envie de lire les articles précédents de cette série (bien que je ne pense pas que celui-ci se repose sur les anciens articles) donc, au cas où vous les auriez loupés, voici les liens vers les articles précédents de la série (attention : les lire prendra du temps…) :
- Programme d'étude sur le C++ bas niveau n°1 ;
- Programme d'étude sur le C++ bas niveau n°2 ;
- Programme d'étude sur le C++ bas niveau n°3 ;
- Programme d'étude sur le C++ bas niveau n°4 ;
- Programme d'étude sur le C++ bas niveau n°5 ;
- Programme d'étude sur le C++ bas niveau n°6 ;
- Programme d'étude sur le C++ bas niveau n°7 ;
- Programme d'étude sur le C++ bas niveau n°8 ;
- Programme d'étude sur le C++ bas niveau n°9,
2. Type de données et énumération▲
Nous avons découvert les types fondamentaux et intrinsèques dans le second article de la série (Programme d'étude sur le C++ bas niveau n°2), qui traitait également du mot-clé enum. J'ai délibérément omis de traiter l'utilisation des mots-clés struct ou class dans cet article, mais nous avons traité certains points à propos du comportement des valeurs définies en utilisant le mot-clé enum (c'est-à-dire, que c'était le compilateur qui détermine quel type intrinsèque est utilisé pour représenter chacune des énumérations que vous avez déclarées, en se basant sur le nombre de valeurs requises).
Heureusement, la norme C++11 définit des changements radicaux dans le comportement des énumérations (Wikipédia - C++11 - Énumérations fortement typées) : parmi lesquels la possibilité de spécifier le type fondamental utilisé pour représenter les valeurs de chaque enum. Merveilleux.
Signaler ce changement bienvenu est l'extension de notre discussion sur les enum, donc allons-y commençons par regarder struct, class et union.
3. Merci à l'équipe de développement Visual Studio▲
Si vous avez été vraiment attentif dans les anciens articles, vous pouvez vous rappeler que j'ai mentionné quelques options de ligne de commande non documentées (non supportées) pour le compilateur Microsoft Visual Studio C++, qui peuvent être utilisées pour afficher la structure de la mémoire des types définis par les mots-clés struct, class ou union.
Ces options secrètes du compilateur sont /d1reportAllClassLayout qui permet d'afficher l'agencement de toutes les classes du projet courant, et sa sœur plus ergonomique /d1reportSingleClassLayoutxxx (où xxx est une chaîne utilisée pour une comparaison avec les classes que vous voulez afficher).
Je me pencherai plus fortement sur ce compilateur dans les prochains articles, afin que nous puissions voir comment les utiliser. Cela fonctionne sans aucun doute dans VS2010 et VS2012, cela fonctionne même dans les versions Express. Waouh !
C'est ici que vous tapez dans l'option ligne de commande dans la page de propriété (N.B. C'est la « seule » version qui compare n'importe quelle classe ou structure contenant la chaîne « Test » dans son nom) :
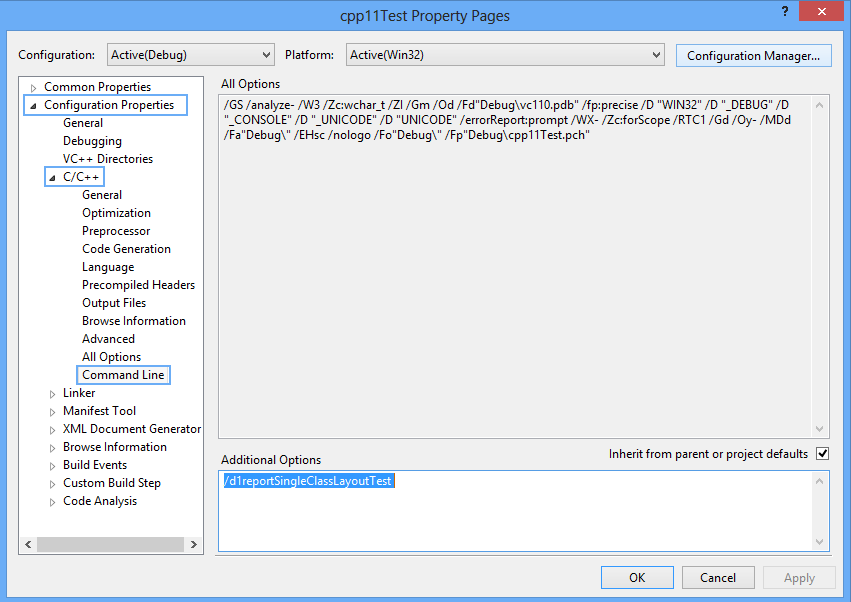
4. Sortie provenant de /d1reportSingleClassLayout▲
Jusqu'ici tout va bien.
Maintenant, c'est le moment de regarder l'extrait de code définissant une simple structure POD (POD est un simple agrégat de données) et les informations de sortie délivrées par /d1reportSingleClassLayout quand nous la compilons…
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
#include "stdafx.h"
struct STest
{
int iA;
int iB;
};
int main(int argc, char* argv[])
{
return 0;
}
Quand nous compilons ceci avec cette fantaisie secrète du compilateur, comme espéré nous obtenons quelques informations supplémentaires au milieu de la sortie usuelle du compilateur de Visual Studio :
2.
3.
4.
5.
1> class STest size(8):
1> +---
1> 0 | iA
1> 4 | iB
1> +---
Espérons que ceci devrait vous apparaitre plutôt explicite, mais dans le cas où cela ne l'est pas - restez rassuré, nous nous apprêtons à regarder un peu plus en détail.
La première ligne contient le nom de la classe et sa taille en octets - Stest est une struct, mais c'est indiquer comme étant une class - ne vous inquiétez pas de cela pour le moment.
Le nom de la structure contient la chaine « Test » qui est la chaine recherchée que nous avons spécifiée dans l'option du compilateur afin d'obtenir l'agencement des informations de la classe.
Le reste des informations détaille membre par membre l'agencement mémoire de la structure organisée par le nom des données membres - le nombre au début de la ligne est le déplacement, en octets, de ce membre relatif au début de la structure.
La première chose à noter est que les variables membres sont disposées en mémoire dans l'ordre spécifié dans la déclaration de classe.
Une garantie est donnée dans les spécifications des langages C et C++ que l'adresse mémoire de chaque membre est plus grande que celle de celui déclaré avant lui (voir cet article de Stack Overflow, en anglais, pour plus de détails sur la formulation).
Dans le cas de STest, le premier membre, iA, est positionné à 0 octet à partir du début de la structure, et le second membre, iB, est positionné à 4 octets à partir du début de la structure.
Important, (en faisant un peu de maths avec les décalages et la taille de la structure) cela nous dit aussi que l'espace occupé par iA est de 4 octets, et l'espace occupé par iB est 4 octets - comme sizeof(int) == 4, cela correspond à ce que nous nous attendions.
5. Accéder au membre de la structure dans l'assembleur▲
Nous savons tous que ça allait arriver, pas vrai ?
Woo ! Je sais que vous vivez tous pour les nombres hexadécimaux et les mnémoniques assembleurs.
Comme toujours, la chose principale que je veux que vous reteniez de ceci, est qu'il ne s'agit pas de comprendre spécifiquement le code assembleur en lui-même (bien que clairement cela soit un bénéfice…), mais plus une appréciation générale de la combinaison des instructions assembleur qui « sentent comme » l'accès du compilateur à un membre d'une structure ou d'une classe.
S'habituer, au niveau de l'assembleur, à « sentir » différentes constructions de haut niveau dans le code assembleur généré par le compilateur, vous permettra de trouver vos marques plus rapidement dans le code que vous voyez dans la fenêtre du désassembleur, et - plus important (en partant du principe que vous avez assez de chance pour avoir une pile d'appels valides - et, comme une personne sensée, vous avez les symboles de votre compilation Release) - vous devriez développer rapidement la capacité d'élaborer quelle partie du code de haut niveau correspond à l'assembleur que vous regardez actuellement. Gagner.
Voici un extrait de code qui accède aux données membres de la structure que nous venons juste de définir :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
#include "stdafx.h"
struct STest
{
int iA;
int iB;
};
int main(int argc, char* argv[])
{
STest sOnStack;
sOnStack.iA = 1;
sOnStack.iB = 2;
STest* psOnHeap = new STest;
psOnHeap->iA = 3;
psOnHeap->iB = 4;
delete psOnHeap;
return 0;
}
Avant de regarder le désassembleur, nous devons expliquer un peu plus l'extrait.
Deux instances de STest sont créées :
- sOnStack sur la pile - c'est-à-dire alloué automatiquement par le compilateur comme une variable locale ;
- sOnHeap sur le tas - c'est-à-dire alloué dynamiquement.
La raison de cela apparaîtra clairement lorsque nous allons inspecter l'assembleur.
Techniquement la zone de mémoire dynamique gérée par new et delete en C++ est appelée the Free Store (le magasin libre), mais tout le monde l'appelle lle Tas. Je suis presque sûr que c'est parce que la mémoire dynamique en C gérée par malloc et free avait été familièrement et historiquement connue comme « le Tas », et beaucoup d'implémentations C++ définissent new et delete en utilisant malloc et free (et la plupart, si ce n'est pas tous l'ont reprise).
Donc voici le désassembleur généré par le compilateur de débogue VS2010 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
14: STest sOnStack;
15: sOnStack.iA = 1;
00A01269 mov dword ptr [ebp-8],1
16: sOnStack.iB = 2;
00A01270 mov dword ptr [ebp-4],2
17:
18: STest* psOnHeap = new STest;
00A01277 push 8
00A01279 call 00A010F5
00A0127E add esp,4
00A01281 mov dword ptr [ebp-54h],eax
00A01284 mov eax,dword ptr [ebp-54h]
00A01287 mov dword ptr [ebp-0Ch],eax
19: psOnHeap->iA = 3;
00A0128A mov eax,dword ptr [ebp-0Ch]
00A0128D mov dword ptr [eax],3
20: psOnHeap->iB = 4;
00A01293 mov eax,dword ptr [ebp-0Ch]
00A01296 mov dword ptr [eax+4],4
Regardez à la ligne 3 et 6 (et rappelez-vous ce que nous avons appris dans l'article 2 sur la façon dont les variables en mémoire sont accédées en assembleur) ; nous pouvons voir que l'on accède aux deux sOnStack.iA et sOnStack.iB directement par leur adresse mémoire en se déplacement à partir de ebp ([ebp-8] et [ebp-4] respectivement).
Regardez aux lignes 15-16 et lignes 18-19 nous pouvons voir que psOnHeap.iA et psOnHeap.iB sont accédées différemment.
Comme c'est différent de ce que nous avons vu auparavant, décomposons un peu :
- pour chacun de ces assignements, d'abord le pointeur psOnHeap (c'est-à-dire l'adresse mémoire de l'instance de STest créée à la ligne 7) est chargé dans
eax(ligne 15 et ligne18), et… - puis le membre est accédé via l'adresse mémoire stockée dans
eax(ligne 16 et ligne 19 - via [eax] et [eax+4] respectivement).
En particulier, notez que lorsqu'on accède à STest::iB (à l'adresse [eax+4] - ligne 19) un décalage de 4 octets est ajouté, ce qui est exactement le décalage que l'affichage de /d1reportSingleClassLayout nous a donné.
Espérons que cela soit maintenant assez évident pourquoi on accède aux instances de STest de manière différente comme ici. Et par extension, pourquoi je vous ai montré du code accédant à une instance sur la Pile et une sur le Tas (via un pointeur) :
- quand une instance d'un type défini par l'utilisateur est sur le Tas, le compilateur est en charge de l'emplacement de stockage de l'instance (par rapport à la structure du Tas) ; et donc il peut accéder à ces membres directement par leur position à l'intérieur de la structure du Tas ;
- quand une instance est stockée dans un espace mémoire qui n'est pas connu à la compilation (par exemple, accessible par un pointeur) le compilateur ne peut pas faire cela et il doit y accéder par déplacement à partir de l'adresse de base de l'instance (c'est-à-dire l'adresse mémoire de début de l'instance).
C'est le code de débogue désassemblé, s'il vous plaît n'essayer pas d'en déduire quoi que ce soit en ce qui concerne l'efficacité relative de la Pile par rapport au Tas à partir de cela ! Autant que je sache, sur toutes les machines que j'ai jamais utilisées, le Tas et la Pile sont tous les deux stockés dans le même espace mémoire et accédés via le même système physique, donc en termes de vitesse d'accès minimale théorique Tas == Pile.
6. Qu'en est-il des classes ?▲
La réponse courte à cette question est qu'il n'y aucune différence entre classes et structures au niveau de l'implémentation C++.
La réponse longue est que, dans le langage C++, struct est en fait un cas particulier de class avec une différence spécifique - pour class toute visibilité non spécifiée (c'est-à-dire public, protected, ou private n'importe où dans la déclaration de type) sera par défaut private, mais pour struct ce sera par défaut public.
C'est tout. La seule différence. Honnête.
Les visibilités sont finalement juste des plus syntaxiques au niveau du langage pour nous permettre de contrôler la façon dont nos classes sont utilisées ; sous le capot les structures et les classes sont implémentées de la même façon - même en ce qui concerne des choses comme l'héritage et les fonctions virtuelles.
Si vous faites une recherche et remplacez struct par class dans l'extrait et ajoutez public: en début de chaque déclaration de class (donc cela compile). Vous allez obtenir exactement la même sortie sur l'organisation de la classe et le même désassembleur.
7. Union▲
Comme class et struct, il y a un autre mot-clé qui permet de définir un type : le mot-clé union.
Ce n'est pas une fonctionnalité du langage fréquemment vue et utilisée, et d'autant plus utile de discuter ici, parce que cela peut être très utile et cette fréquence d'utilisation faible indique que beaucoup de gens ne connaissent pas vraiment à quoi cela sert, et encore moins comment cela fonctionne.
Regardons cela avec un autre exemple d'extrait de code. Nous allons y ajouter deux nouveaux types :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
#include "stdafx.h"
struct STest
{
int iA;
int iB;
};
struct STestTwo
{
int iC;
int iD;
int iE;
};
union UTestUnion
{
STest sTest;
STestTwo sTestTwo;
};
int main(int argc, char* argv[])
{
UTestUnion* psOnHeap = new UTestUnion;
psOnHeap->sTest.iA = 1;
psOnHeap->sTestTwo.iC = 2;
psOnHeap->sTest.iB = 3;
psOnHeap->sTestTwo.iD = 4;
psOnHeap->sTestTwo.iE = 5;
delete psOnHeap;
return 0;
}
Compilons ce code avec /d1reportSingleClassLayout nous obtenons le résultat suivant pour les organisations :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
1> class STest size(8):
1> +---
1> 0 | iA
1> 4 | iB
1> +---
1>
1> class STestTwo size(12):
1> +---
1> 0 | iC
1> 4 | iD
1> 8 | iE
1> +---
1>
1> class UTestUnion size(12):
1> +---
1> 0 | STest sTest
1> 0 | STestTwo sTestTwo
1> +---
La première chose à noter est qu'UTestUnion possède la même taille que STestTwo. C'est exactement comme on s'y attendait.
La seconde chose à noter est que les deux UTestUnion::sTest et UTestUnion::sTestTwo sont positionnées à 0 à partir de UTestUnion. Encore une fois, exactement comme on s'y attendait.
Donc, pourquoi est-ce le cas ?
Le mot-clé union vous permet de spécifier de multiples organisations pour un espace mémoire. Quand nous déclarons l'union de STest et STestTwo au sein d'UTestUnion, nous déclarons notre intention de pouvoir traiter la mémoire du type UTestUnion comme une instance de STest ou une instance de STestTwo à notre discrétion.
Cela signifie que, au sein du type UTestUnion, une instance de STest et une instance de STestTwo existent superposées l'une sur l'autre. Comme l'union peut être traitée comme n'importe quel type, cela signifie qu'elle doit nécessairement avoir la même taille que le plus grand des deux types.
Revenons en arrière pour regarder le désassembleur :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
29: psOnHeap->sTest.iA = 1;
0122127C mov eax,dword ptr [ebp-4]
0122127F mov dword ptr [eax],1
30: psOnHeap->sTestTwo.iC = 2;
01221285 mov eax,dword ptr [ebp-4]
01221288 mov dword ptr [eax],2
31:
32: psOnHeap->sTest.iB = 3;
0122128E mov eax,dword ptr [ebp-4]
01221291 mov dword ptr [eax+4],3
33: psOnHeap->sTestTwo.iD = 4;
01221298 mov eax,dword ptr [ebp-4]
0122129B mov dword ptr [eax+4],4
34:
35: psOnHeap->sTestTwo.iE = 5;
012212A2 mov eax,dword ptr [ebp-4]
012212A5 mov dword ptr [eax+8],5
C'est ici, clair comme de l'eau de roche.
Dans le cas où vous ne le voyez pas, voici une description rapide :
- nous pouvons voir que psOnHeap est stocké à [
ebp-4] ; - on accède à (ligne 2)
UTestUnion::sTest::iA et (ligne 5)UTestUnion::sTestTwo::iC directement via la valeur chargée danseaxdepuis [ebp-4] - c'est-à-dire à l'emplacement 0, le même emplacement que celui dans leur type respectif comme indiqué dans l'organisation de la structure de la classe ; - on accède à (ligne 9)
UTestUnion::sTest::iB et (ligne 12)UTestUnion::sTestTwo::iD via [eax+4] avec un déplacement de 4 octets depuis la valeur chargée danseaxdepuis [ebp-4]. Encore, le même déplacement que celui dans leur type respectif comme indiqué dans l'organisation de la structure de la classe ; - on accède à (ligne 16)
UTestUnion::sTest::iE via [eax+8] - un déplacement de 8 octets comme spécifié dans l'organisation de la structure de la classe.
Un exemple plus réel de l'utilisation d'union pourrait être une structure de données utilisée dans un vecteur d'une bibliothèque mathématique semblable à celle ci-dessous :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
class CTestVec4
{
union
{
struct
{
float x;
float y;
float z;
float w;
};
struct
{
float vec[ 4 ];
};
};
};
Le code ci-dessus déclare une structure de vecteur dont les données peuvent être accédées via ses membres ou comme un tableau - par exemple, CTestVec4::z occupe le même espace mémoire que CTestVec4::vec[2].
Le code semble être illégal, mais il ne l'est pas : laisser tous les noms vides est entièrement délibéré, cela définit une union anonyme ce qui rend la syntaxe pour accéder à l'union « moins encombrante » (c'est-à-dire juste moins longue à taper).
Si vous n'étiez pas sûr de savoir comment fonctionne une union, ou encore à quoi cela sert, maintenant vous savez.
8. Certes, nous sommes bloqués, et maintenant ?▲
Nous le sommes très clairement ! Bien vu.
Il y a un aspect bas niveau incroyablement important concernant la manière dont la mémoire est organisée dans une class ou une struct que j'ai délibérément occulté jusqu'à maintenant.
Considérons l'extrait de code suivant contenant une innocente déclaration de struct :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
#include "stdafx.h"
struct STestSpanner
{
int iOne;
double fdTwo;
char chThree;
int iFour;
};
int main(int argc, char* argv[])
{
return 0;
}
Quand nous compilons ceci, nous obtenons les informations suivantes concernant l'organisation de la classe.
2.
3.
4.
5.
6.
7.
8.
9.
1> class STestSpanner size(24):
1> +---
1> 0 | iOne
1> | <alignment member> (size=4)
1> 8 | fdTwo
1> 16 | chThree
1> | <alignment member> (size=3)
1> 20 | iFour
1> +---
Quelle est cette sorcellerie ?
Nous avons ajouté un char et un double à notre struct - requérant un total de 9 octets supplémentaires (sous Win 32 sizeof(char) == 1 et sizeof(double) == 8).
Cependant, la taille totale de la structure a augmenté de 16 octets - en plus des 9 octets que nous avons demandés, nous avons aussi ajouté 7 octets de « membre d'alignement » invisible.
Qu'est-ce qui se passe ? Remplissage (Padding) - C'est quoi ?
9. Remplissage (Padding) !?!▲
Tant que l'organisation des données membres d'un type satisfait à l'ordre requis par le standard du langage (comme expliqué plus tôt), les données peuvent ne pas être immédiatement adjacentes en mémoire.
Le compilateur est libre, encouragé même, d'insérer des octets de remplissage à l'intérieur de vos structures et classes à sa discrétion.
Pourquoi le compilateur voudrait-il ajuster l'organisation mémoire comme ça ?
La réponse courte est : pour optimiser la vitesse d'accès mémoire pour les types de stockage intrinsèques dans cette structure.
La réponse longue est quelque chose comme ça…
Sur chaque plateforme, les différents types intrinsèques ont des tailles différentes et généralement aussi différentes exigences d'alignement mémoire.
Dans le meilleur cas, accéder à un type intrinsèque avec un alignement exigé à partir d'une adresse mémoire alignée incorrectement provoquera un temps d'accès plus lent que la normale (sur x86 le coût est généralement relativement faible, mais il peut être beaucoup plus lent sur d'autres plateformes) ; et dans le pire des cas, il peut actuellement provoquer le plantage du CPU (oui, vraiment - sur certaines plateformes l'accès non aligné met le CPU en panique).
Il y a trois facteurs différents qui sont en jeu dans la détermination de la taille de STestSpanner :
- le nombre logique d'octets requis par ses types constituants - c'est la taille minimum possible de ce type ;
- l'ordre des types constituants à l'intérieur de la déclaration de la classe ;
- l'exigence d'alignement individuel de ces types constituants.
Le compilateur honore à la fois l'ordre des types constituants et leurs exigences individuelles d'alignement, et cette interaction détermine la quantité d'octets de remplissage qui seront ajoutés.
Ils s'influencent mutuellement et sont étroitement liés. La distinction entre alignement, empaquetage et remplissage engendre souvent une confusion :
- l'alignement est une contrainte sur l'adresse de début de l'instance d'un type en mémoire ;
- l'empaquetage est une contrainte sur l'alignement sur les membres adjacents à l'intérieur de la mémoire d'une structure ou une classe ;
- le remplissage est les octets ajoutés à l'intérieur d'une classe ou une structure pour maintenir l'exigence d'empaquetage. Cette question Stack Overflow est une bonne discussion sur l'implication de l'accès non aligné sur x86 pour ceux d'entre vous qui sont intéressés.
10. Pardon, pourquoi le remplissage ?▲
Comme nous l'avons dit avant, les rédacteurs de compilateur sont astucieux.
Vous devez pouvoir déclarer un tableau de n'importe quel type que vous avez défini, et donc l'organisation mémoire de la structure ou la classe que vous avez définie doit seulement maintenir l'exigence d'alignement de ces types constituants intrinsèques à l'intérieur d'une instance, mais aussi à travers un tableau d'instances disposé de façon contiguë en mémoire.
Le chemin le plus simple pour s'assurer que la structure interne du type est cohérente avec l'exigence d'alignement la plus grande de ces types constituants - et cela signifie que la taille et l'empaquetage interne de n'importe quelle structure que vous déclarez seront finalement généralement déterminés par l'exigence d'alignement la plus large de ses types constituants.
Dans le cas de notre structure cela serait le double qui a un alignement par défaut de 8 octets (du moins avec le compilateur Visual Studio x86, cela varie avec les autres compilateurs), et par conséquent, il en va de même pour la structure STest - d'où les 7 octets supplémentaires de remplissage pour faire que la structure passe de 17 octets (2 int (8 octets) + 1 double (8 octets) + 1 char (1 byte) de données que nous avons demandées à 24 octets - c'est-à-dire la taille suivante qui maintient l'alignement du double.
Vous devriez trouver ça, peu importe comment vous mélangiez les membres de STestSpanner, vous finirez toujours avec une structure de 24 octets qui inclut 7 octets de remplissage.
Sur le plan positif, si nous avons besoin d'ajouter 3 char supplémentaires et 1 int supplémentaire dans STestSpanner nous obtiendrions cet espace de stockage pour rien tant que nous les mettons à la bonne position dans la déclaration du type.
11. Mais quid de tous ces octets gaspillés ?▲
Le compilateur sait ce qu'il fait, et 99 % du temps vous ne devrez pas vous inquiéter à propos de l'espace gaspillé.
Prenez une tasse de thé et un biscuit et cassez-le en deux - ce n'est pas de l'espace gaspillé, c'est de l'espace investi pour rendre vos accès mémoire plus efficaces.
Cependant, vous devriez vous en inquiéter un peu parce qu'il est tout à fait possible de provoquer le compilateur d'introduire du remplissage dans un type qui est en fait un gaspillage total de mémoire.
Considérez cette structure :
2.
3.
4.
5.
6.
struct STestSpannerTwo
{
int iOne;
double fdTwo;
int iThree;
};
Qui produit cette organisation mémoire :
2.
3.
4.
5.
6.
7.
8.
1> class STestSpanner size(24):
1> +---
1> 0 | iOne
1> | <alignment member> (size=4)
1> 8 | fdTwo
1> 16 | iThree
1> | <alignment member> (size=4)
1> +---
Un coup d'œil rapide à l'organisation mémoire ci-dessus nous informe qu'il y a 4 octets de remplissage entre STestSpannerTwo::iOne et STestSpannerTwo::fdTwo ; et encore 4 octets de remplissage après STestSpanner::iThree.
Le format en virgule flottante de 64 bits x86 intrinsèque utilisé pour représenter un double est long de 8 octets et a clairement un alignement par défaut de 8 octets sous le compilateur Visual Studio.
Les contraintes de notre type combiné déclaré avec la contrainte d'alignement de 8 octets pour le double a abouti à :
- 4 octets de remplissage après
STestSpannerTwo::iOne et avantSTestSpannerTwo::fdTwo pour conserver l'alignement à l'intérieur de la mémoire d'une seule instance de STestSpannerTwo ; - et 4 octets de remplissage après
STestSpannerTwo::iThree pour conserver l'alignement de 8 octets dans des instances de STestSpannerTwo qui sont contiguës en mémoire (c'est-à-dire un tableau de STestSpannerTwo).
Cependant, nous pouvons aussi voir que STestSpannerTwo::iThree est un int sur 4 octets et donc qu'il s'adapterait dans le premier bloc de remplissage ; supprimant la nécessité des 8 octets de remplissage.
Réorganiser les membres à la main permettrait d'économiser 8 octets sur la taille totale de la structure, et donc nous pouvons voir que - dans ce cas - nous pouvons économiser 33 % de la mémoire utilisée par la structure fondamentalement gratuitement - ne me croyez pas sur parole, essayez !
Alors que ce n'est pas quelque chose qui doit vous empêcher de dormir, vous devriez maintenant être capable de voir le bénéfice de toujours prendre une seconde pour étudier la meilleure place pour insérer une nouvelle donnée membre dans un type existant.
12. … mais que se passe-t-il si j'ai « vraiment » besoin de ces octets de remplissage ?▲
Sans surprise, ceci étant C/C++, c'est entièrement possible de demander au compilateur de changer son comportement par défaut d'alignement et d'empaquetage.
C'est habituellement accompli par l'utilisation d'options du compilateur en ligne de commande et/ou par des commandes spécifiques au compilateur qui sont insérées directement dans votre code.
Dans Visual Studio, par exemple, il y a l'option du compilateur /Zp, et deux autres façons pour modifier l'alignement des structures de données et l'empaquetage de leurs membres avec des commandes du compilateur à l'intérieur du code lui-même __declspec( align( x ) ) et #pragma pack (x). Il y en a peut-être encore d'autres que je n'ai jamais vues ou utilisées, mais une recherche rapide sur Internet ne trouvera rien.
Par exemple, utiliser #pragma pack pour dire au compilateur d'empaqueter STestSpanner a une limite de 1 octet comme ceci :
2.
3.
4.
5.
6.
7.
8.
#pragma pack(1)
struct STestSpanner
{
int iOne;
double fdTwo;
char chThree;
int iFour;
};
Donne cette organisation mémoire :
2.
3.
4.
5.
6.
7.
1> class STestSpanner size(17):
1> +---
1> 0 | iOne
1> 4 | fdTwo
1> 12 | chThree
1> 13 | iFour
1> +---
Soyez averti !
Ajuster l'empaquetage d'un type peut (probablement va) briser les contraintes d'alignement de ses types constituants - dans l'exemple ci-dessus il n'y pas d'octet « gaspillé », mais STestSpanner ne répond plus aux exigences d'alignement de ses types constituants et donc va probablement mettre significativement plus de temps pour y accéder que si nous ne l'avions pas trafiqué.
Cela signifie que quand nous demandons au compilateur de changer l'empaquetage d'un type nous devons être très prudents.
Mon conseil est celui-ci - en général -, vous ne devriez pas plaisanter avec l'alignement et le remplissage sauf si vous avez une très bonne raison. Modifier le remplissage et l'alignement peut vous entrainer dans le pétrin, spécialement avec de gros projets et quand vous utilisez du code de bibliothèques, voici un lien vers un article sur le blog de l'équipe de Visual C++ (en Anglais) qui entre dans les détails.
Les décisions de changement d'alignement et de remplissage vont généralement provoquer des arbitrages spécifiques à la plateforme basés sur des données provenant du profil d'exécution - des problèmes d'équilibrage comme la taille des données par rapport aux contraintes ressource mémoire, les temps d'accès d'une partie individuelle de données dans le pire cas, et des problèmes en relation avec les tailles de cache système et l'alignement.
13. Résumé▲
En résumé voici les points principaux que j'aimerai que vous reteniez de cet article.
- Les options de compilation non documentées /d1reportSingleClassLayout et /d1reportAllClassLayout sont incroyables, et peuvent vous aidez à comprendre l'implication de l'utilisation mémoire du code que vous écrivez, tout en étant des outils de débogage très utiles.
- Nous le savons maintenant, quand une instance d'une structure est accédée via un pointeur, ses membres sont accédés via un déplacement depuis l'adresse de base de l'instance dans l'assembleur, et…
- …que, logiquement, nous pouvons utiliser ceci dans la vue désassembleur pour travailler sur le membre qui est accédé.
- La différence entre
structetclassc'est-à-dire qu'il n'y a pas de différence de représentation bas niveau. - Ce que provoque le mot-clé
unionet comment il fonctionne. - Ce que sont le remplissage et l'alignement et certaines de leurs implications.
La prochaine fois nous verrons comment l'héritage (simple) affecte ce tableau…
14. Épilogue : astuce de débogueur 17a▲
Voici une alternative pour trouver la position d'un membre à l'intérieur d'un type de données défini par l'utilisateur, une voie que vous pouvez heureusement utiliser dans le débogueur plutôt que de compiler le code.
Cette méthode fonctionne avec la très grande majorité des débogueurs que j'ai utilisés au cours de ces cinq dernières années à la fois sur PC et console ; et il repose sur le fait que la syntaxe du cast C standard fonctionne dans l'affichage d'espionnage. (Essayez ! C'est formidable.)
Un résultat de ceci est que vous pouvez utiliser les cast pour calculer le déplacement en octets de n'importe quel membre d'un type défini (c'est aussi valable, et très utile, dans du code C/C++) :

Ce code semble horrible, pour ne pas dire dangereux, mais ce qu'il fait est en fait très simple et totalement sûr.
Nous l'avons vu, quand nous utilisons un pointeur sur une instance d'un type, le compilateur accède aux membres de ce type défini par l'utilisateur en ajoutant un déplacement à l'adresse mémoire de l'instance stockée à son « adresse de base ».
Notez que les valeurs que nous voyons dans la fenêtre d'espionnage sont identiques à celle que nous avons vue dans le résultat donné par /d1reportSingleClassLayout.
Voici comment cela fonctionne :
- (STest
*)0- dit au débogueur de traiter 0 comme une valeur d'un pointeur sur une instance STest. Si vous pensez « mais 0 c'est NULL ! - Rappelez-vous que 0 est seulement NULL par convention (dans les faits, sur certaines consoles, 0 est une adresse mémoire valide et peut être accédée…). En aucun cas, ce code n'accède à la mémoire - il demande juste au compilateur de traiter 0 comme la valeur d'un pointeur ; &(((STest*)0)->iB) - dit au débogueur de calculer l'adresse deStest::iB. Encore une fois, tant que c'est juste le calcul d'une adresse et pas une tentative d'accès c'est bon.
C'est peut-être la chose préférée que j'ai apprise à propos des débogueurs et qui s'est révélée incroyablement utile tout au long de ces années.
15. Remerciements▲
Cet article est la traduction de l'article « C/C++ Low Level Curriculum Part 10: User Defined Types » écrit en anglais par Alex Darby. Alex Darby a aimablement autorisé l'équipe C/C++ de Developpez.com à traduire et diffuser son article en français.
Nous tenons à remercier germinolegrand pour la relecture technique ainsi que ClaudeLELOUP pour la relecture orthographique de cette traduction.